







准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Load the data
/ 20
Setting up Pub/Sub Topic
/ 20
Add a Pub/Sub subscription
/ 20
Add Cloud Data Fusion API Service Agent role to service account
/ 20
Build and execute runtime pipeline
/ 20

除了批处理流水线,Data Fusion 还允许您创建实时流水线,在事件生成的同时即可处理。目前,实时流水线通过 Cloud Dataproc 集群上的 Apache Spark Streaming 执行。在本实验中,您将学习如何使用 Data Fusion 构建流处理流水线。
您将创建一个流水线,该流水线会从 Cloud Pub/Sub 主题读取数据并处理事件,然后执行一些转换,最后将输出写入 BigQuery。
对于每个实验,您都会免费获得一个新的 Google Cloud 项目及一组资源,它们都有固定的使用时限。
使用无痕式窗口登录 Google Skills。
留意实验的访问时限(例如 02:00:00)并确保能在此时限内完成实验。
系统不提供暂停功能。如有需要,您可以重新开始实验,不过必须从头开始。
准备就绪时,点击开始实验。
请记好您的实验凭据(用户名和密码)。您需要使用这组凭据来登录 Google Cloud 控制台。
点击打开 Google 控制台。
点击使用其他账号,然后将此实验的凭据复制并粘贴到相应提示框中。
如果您使用其他凭据,将会收到错误消息或产生费用。
接受条款并跳过恢复资源页面。
由于这是一个临时账号,仅在本次实验期间有效:
 ) 即可查看服务列表。
) 即可查看服务列表。Cloud Shell 是一种包含开发工具的虚拟机。它提供了一个 5 GB 的永久性主目录,并且在 Google Cloud 上运行。Cloud Shell 可让您通过命令行访问 Google Cloud 资源。gcloud 是 Google Cloud 的命令行工具。它会预先安装在 Cloud Shell 上,且支持 Tab 键自动补全功能。
在 Google Cloud Console 的导航窗格中,点击激活 Cloud Shell (
点击继续。
预配和连接到环境需要一些时间。若连接成功,也就表明您已通过身份验证,且相关项目的 ID 会被设为您的 PROJECT_ID。例如:
列出有效的帐号名称:
(输出)
(输出示例)
列出项目 ID:
(输出)
(输出示例)
在开始在 Google Cloud 中工作之前,您必须确保您的项目在 Identity and Access Management (IAM) 中拥有正确的权限。
在 Google Cloud 控制台的导航菜单 (
确认默认计算服务账号 {project-number}-compute@developer.gserviceaccount.com 已存在且被授予了 editor 角色。账号前缀是项目编号,您可以在导航菜单 > Cloud 概览中找到此编号。
如果该账号在 IAM 中不存在或不具有 editor 角色,请按照以下步骤向其分配所需的角色。
在 Google Cloud 控制台的导航菜单中,点击 Cloud 概览。
从项目信息卡片中复制项目编号。
在导航菜单中,点击 IAM 和管理 > IAM。
在 IAM 页面顶部,点击添加。
在新的主账号字段中,输入:
将 {project-number} 替换为您的项目编号。
在选择角色部分,依次选择基本(或“项目”)> Editor。
点击保存。
为了确保能访问这个必要的 API,请重新启动与 Dataflow API 的连接。
在 Cloud 控制台的顶部搜索栏中输入“Dataflow API”。点击 Dataflow API 的搜索结果。
点击管理。
点击停用 API。
如果系统要求您确认,请点击停用。
您还需要将同一份示例推文文件暂存在 Cloud Storage 存储桶中。在本实验的最后,您将把存储桶中的数据流式传输到 Pub/Sub 主题。
新建存储桶的名称与您的项目 ID 相同。
点击“检查我的进度”以验证是否完成了以下目标:
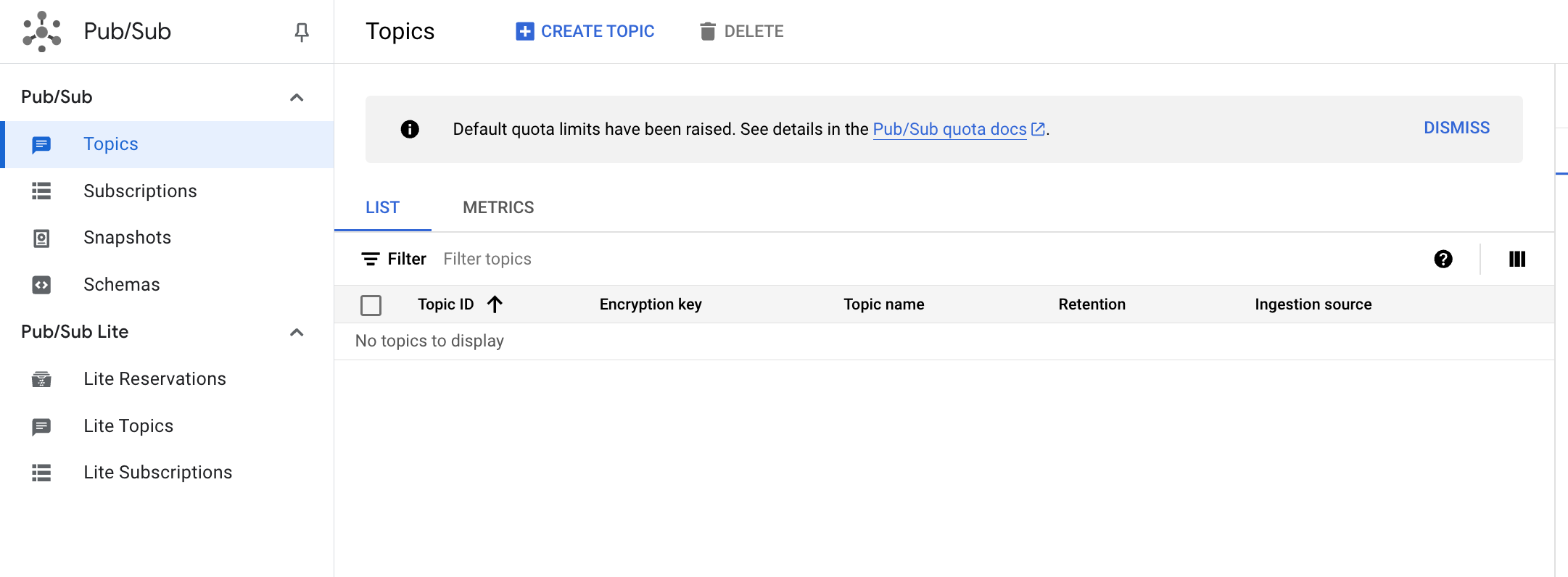
要使用 Pub/Sub,您需创建一个用于保存数据的主题,然后创建订阅来访问发布到该主题的数据。
在 Cloud 控制台的导航菜单中,点击查看所有产品,然后在“Analytics”部分下点击 Pub/Sub,再选择主题。
点击创建主题。
cdf_lab_topic,然后点击创建。点击“检查我的进度”以验证是否完成了以下目标:
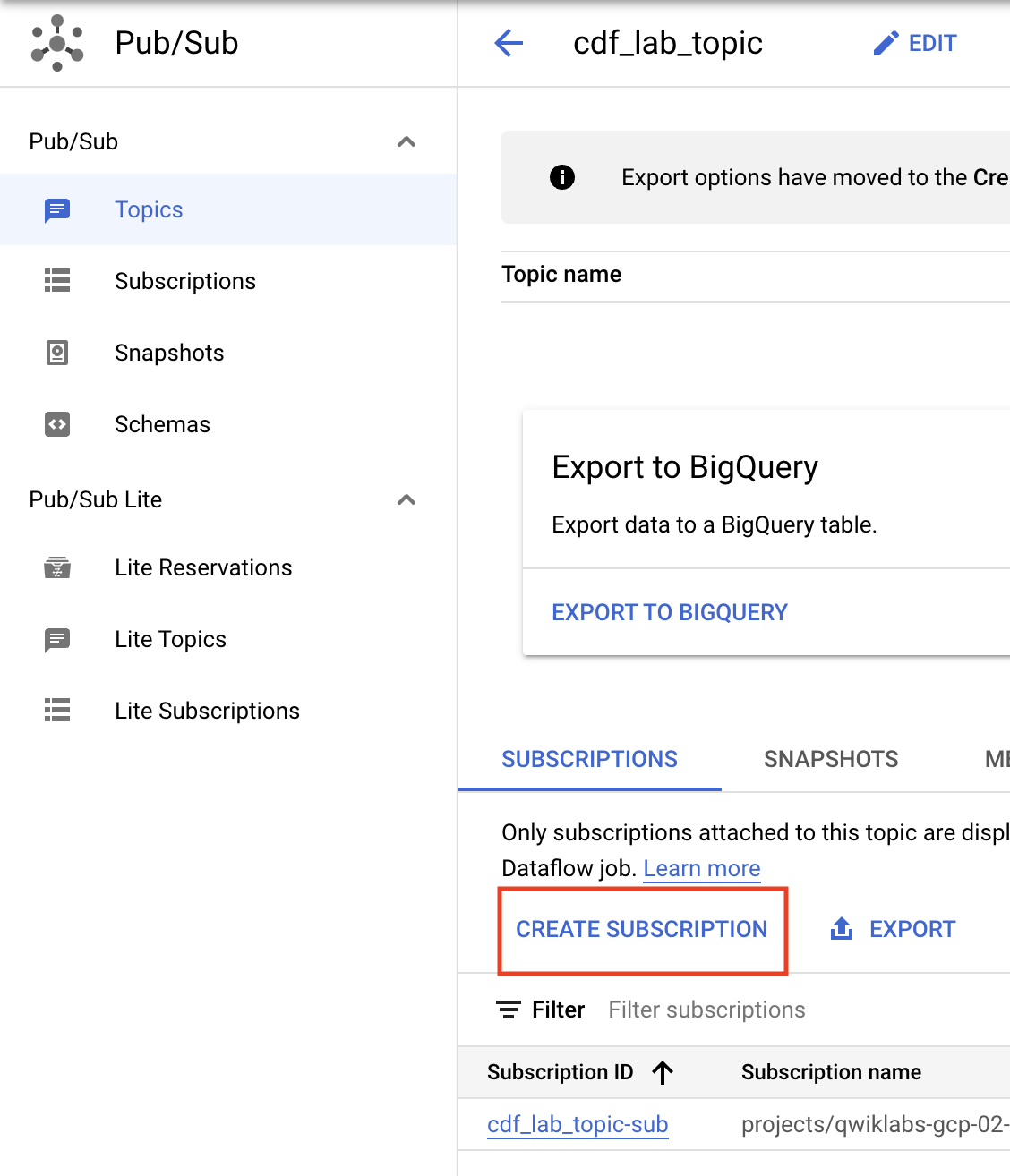
还是在主题页面上。现在您要创建订阅以访问该主题。
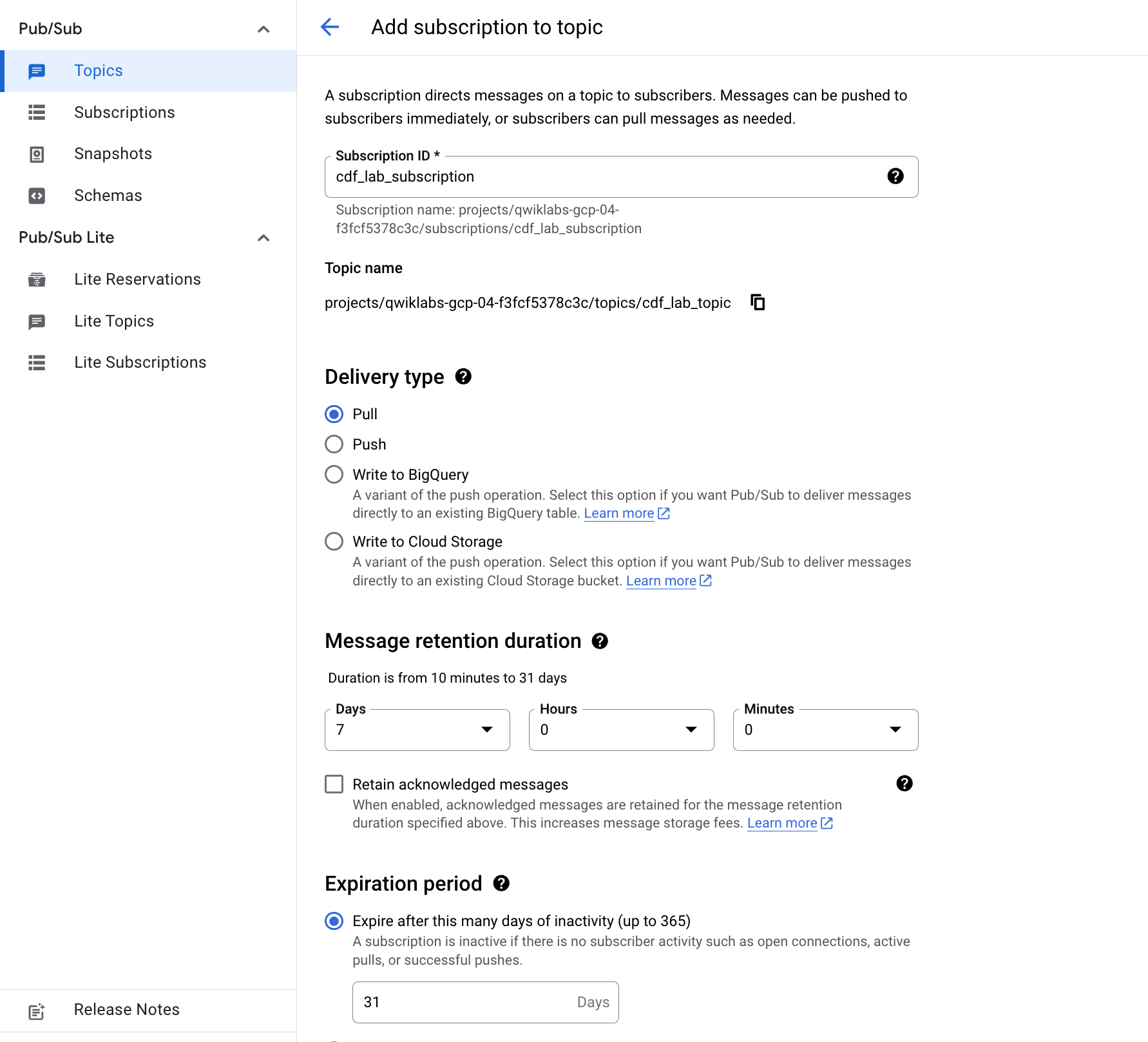
cdf_lab_subscription),将传送类型设置为拉取,然后点击创建。点击“检查我的进度”以验证是否完成了以下目标:
接下来,您将按照以下步骤,向与实例关联的服务账号授予权限。
在 Google Cloud 控制台中,找到 IAM 和管理 > IAM。
确认 Compute Engine 默认服务账号 {project-number}-compute@developer.gserviceaccount.com 已存在,并将服务账号复制到剪贴板。
在 IAM 权限页面,点击 +授予访问权限。
在“新的主账号”字段中,粘贴刚刚复制的服务账号。
点击选择角色字段,输入 Cloud Data Fusion API Service Agent,然后选择该角色。
点击添加其他角色。
添加 Dataproc Administrator 角色。
点击保存。
点击“检查我的进度”以验证是否完成了以下目标:
在控制台中,点击导航菜单下的 IAM 和管理 > IAM。
选中包括 Google 提供的角色授权复选框。
在列表中向下滚动,找到由 Google 管理的 Cloud Data Fusion 服务账号(其形式类似于 service-{项目编号}@gcp-sa-datafusion.iam.gserviceaccount.com),随后将该服务账号名称复制到剪贴板。
然后前往 IAM 和管理 > 服务账号。
点击默认 Compute Engine 账号(其形式类似于 {项目编号}-compute@developer.gserviceaccount.com),然后选择顶部导航栏中的具有访问权限的主账号标签页。
点击授予访问权限按钮。
将您先前复制的服务账号粘贴到新的主账号字段中。
在角色下拉菜单中,选择 Service Account User。
点击保存。
使用 Cloud Data Fusion 时,您将同时使用 Cloud 控制台和单独的 Cloud Data Fusion 界面。在 Cloud 控制台中,您可以创建 Cloud 控制台项目,以及创建和删除 Cloud Data Fusion 实例。在 Cloud Data Fusion 界面中,您可以通过各种页面(例如 Pipeline Studio 或 Wrangler)来使用 Cloud Data Fusion 功能。
若要浏览 Cloud Data Fusion 界面,请按以下步骤操作:
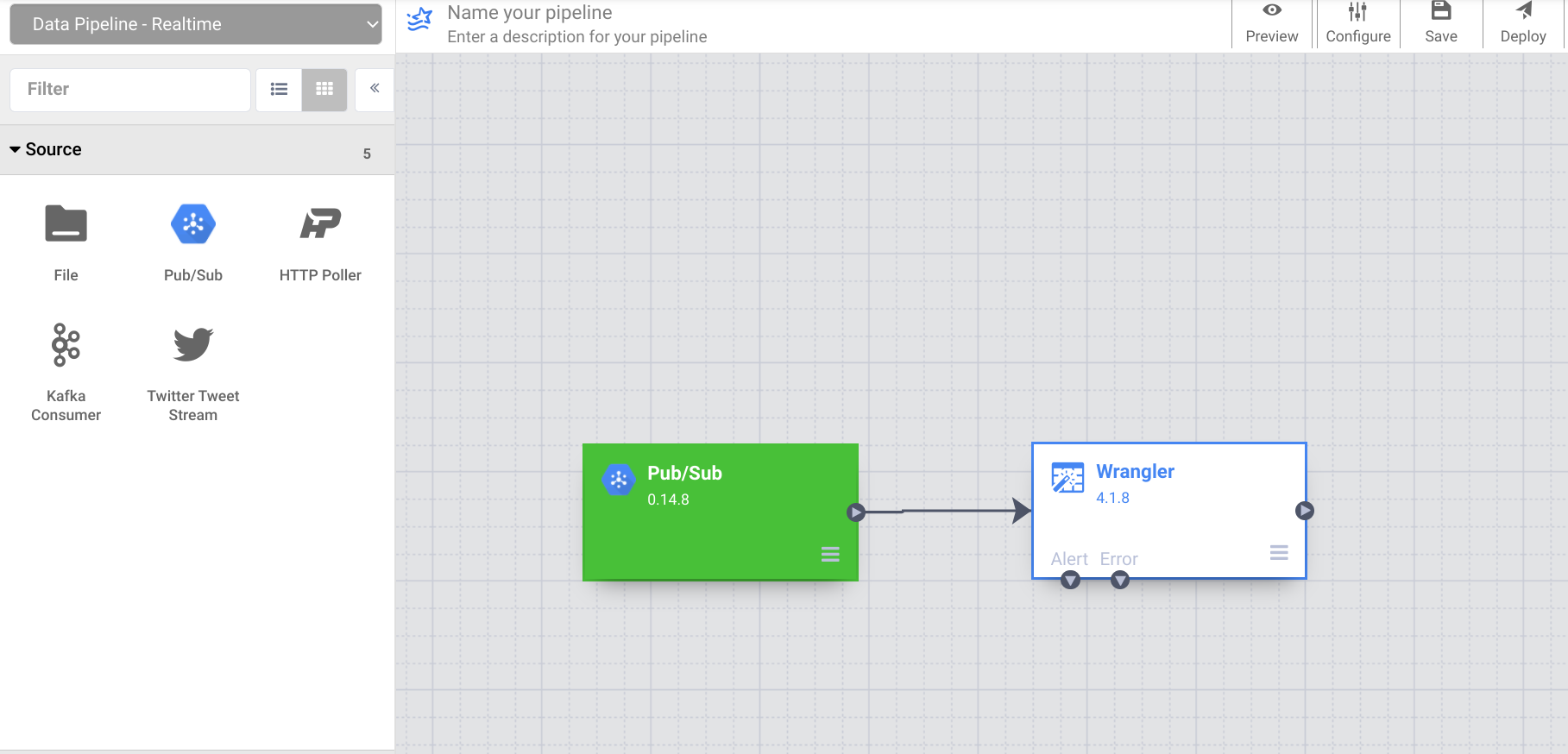
在 Cloud Data Fusion 控制中心,使用导航菜单显示左侧菜单,然后依次选择 Pipeline > Studio。
在左上角,使用下拉菜单选择 Data Pipeline - Realtime。
在处理数据时,如果能直观地查看原始数据的样貌会非常方便,这能为您后续的转换工作提供基础。为此,您将使用 Wrangler 来准备和清理数据。这种以数据为先的方法可让您快速直观地了解转换情况,而实时反馈则可确保您走在正确的轨道上。
在插件面板的转换部分中,选择 Wrangler。Wrangler 节点将显示在画布上,点击“属性”按钮即可打开。
点击指令部分下的 WRANGLE 按钮。
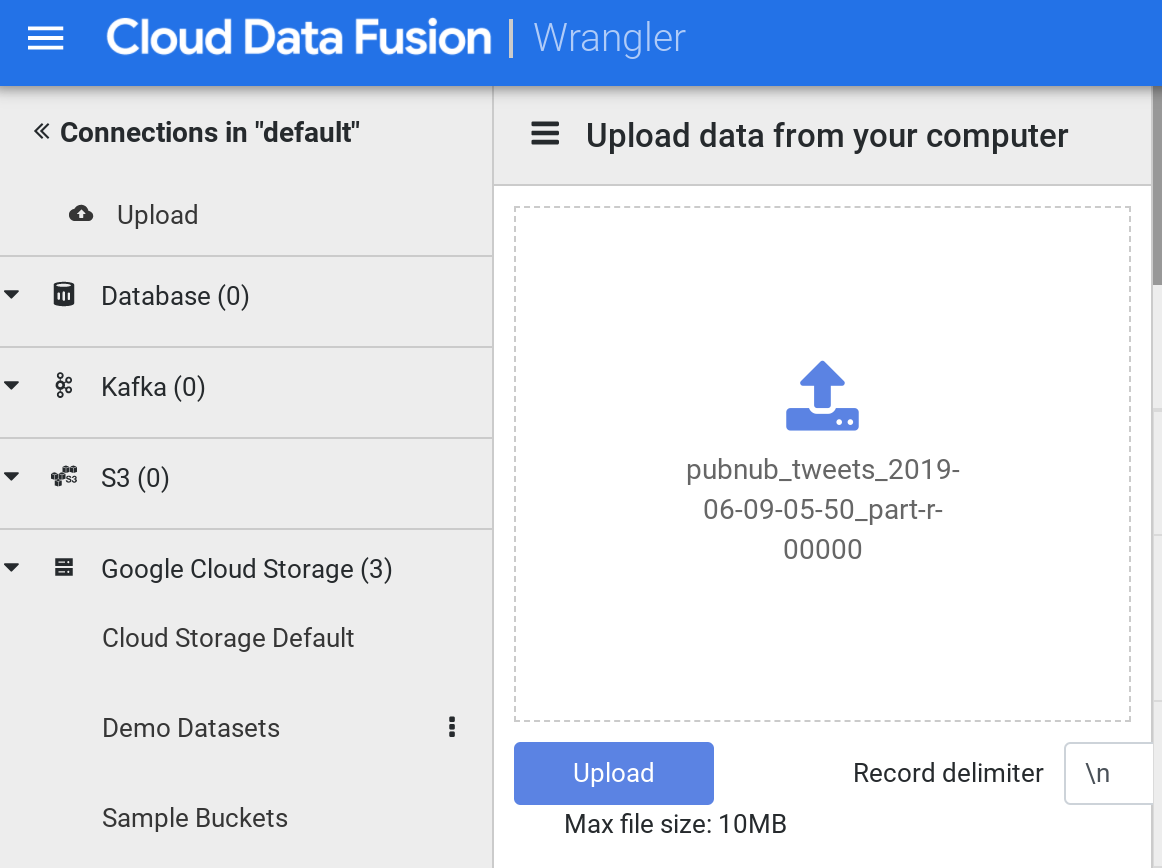
加载完成后,点击左侧侧边菜单中的上传。接下来,点击上传图标,上传您之前下载到计算机中的示例推文文件。
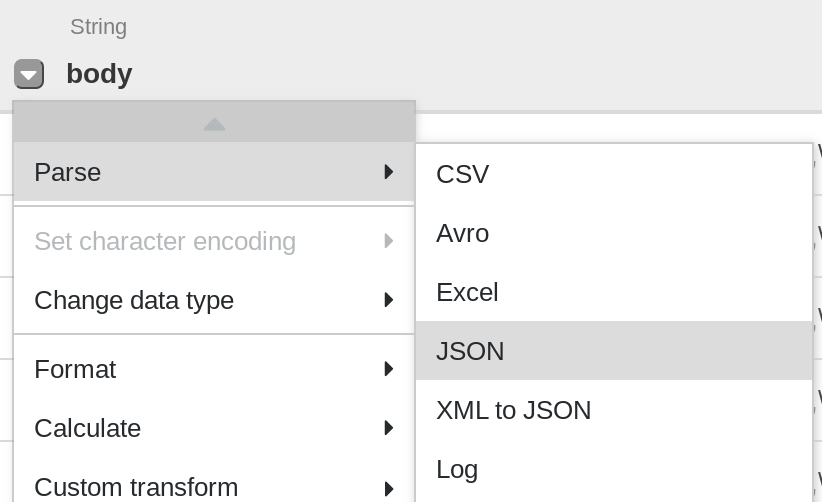
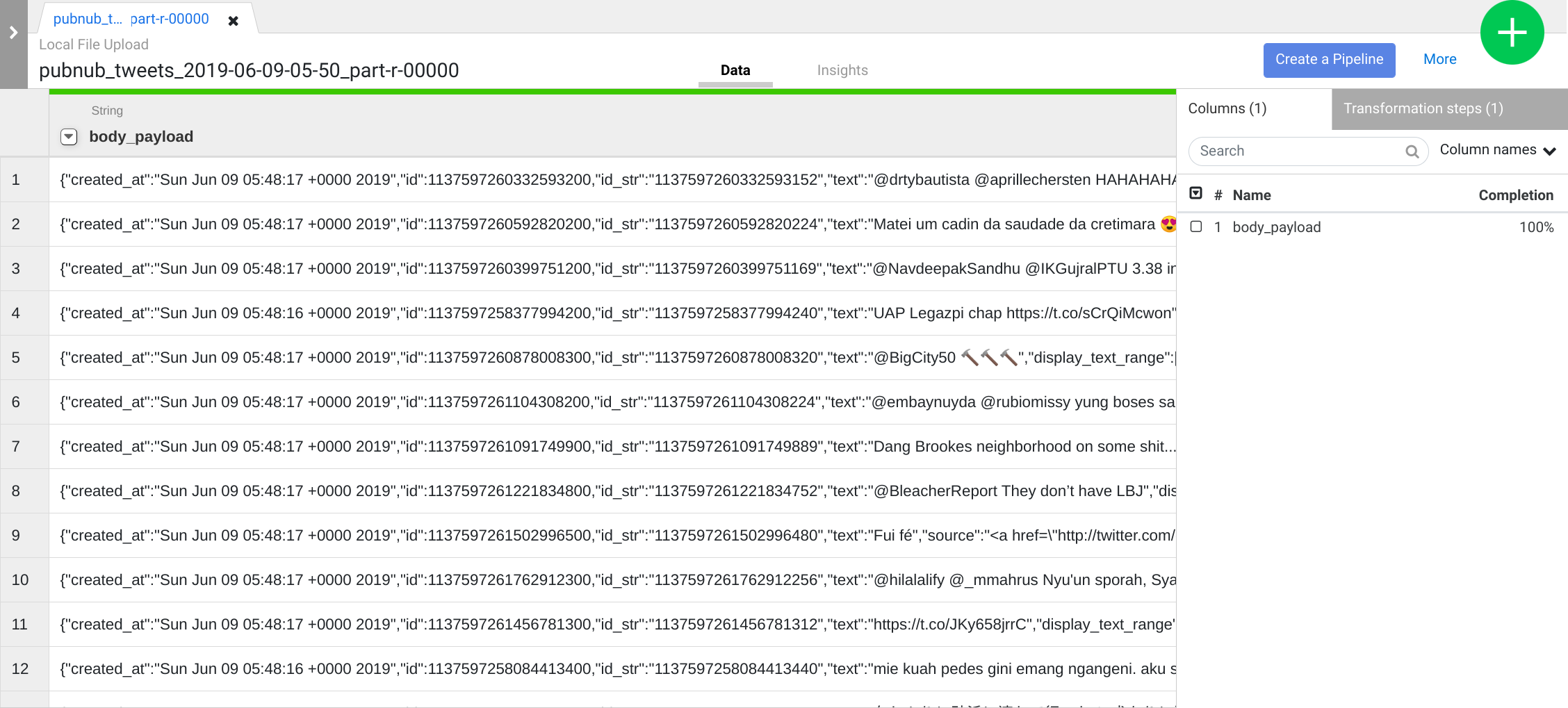
第一项操作是将 JSON 数据解析成划分为行和列的表格形式。为此,您需要从第一列 (body) 标题中选择下拉菜单图标,然后选择解析菜单项,再从子菜单中选择 JSON。在弹出式窗口中,将深度设置为 1,然后点击应用。
重复上一步,以查看更易于理解的数据结构,方便后续转换。点击 body 列下拉菜单图标,依次选择解析 > JSON,并将深度设置为 1,然后点击应用。
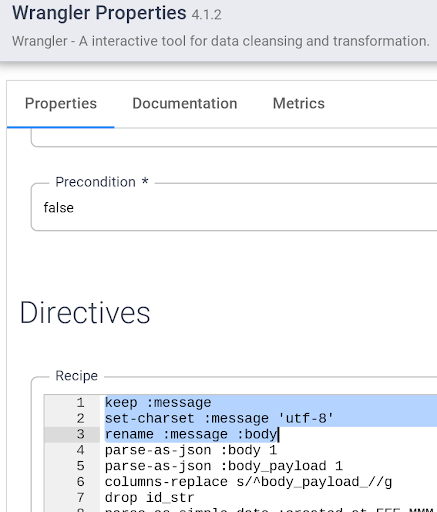
除了使用界面之外,您还可以在 Wrangler 界面底部的指令命令行框(查找带有绿色 $ 提示的命令控制台)中编写转换步骤。 在下一步中,您将使用命令控制台粘贴一组转换步骤。
将以下指令全部复制粘贴至 Wrangler 指令命令行框中,以添加转换步骤:
可以看到,您回到了 Pipeline Studio,画布上放置了一个节点,代表您刚刚在 Wrangler 中定义的转换。不过,如前所述,由于您在笔记本电脑上对数据的代表性样本应用了这些转换,而不是对实际生产位置的数据应用这些转换,因此没有将任何来源连接到此流水线。
在下一步中,我们来指定数据的实际位置。
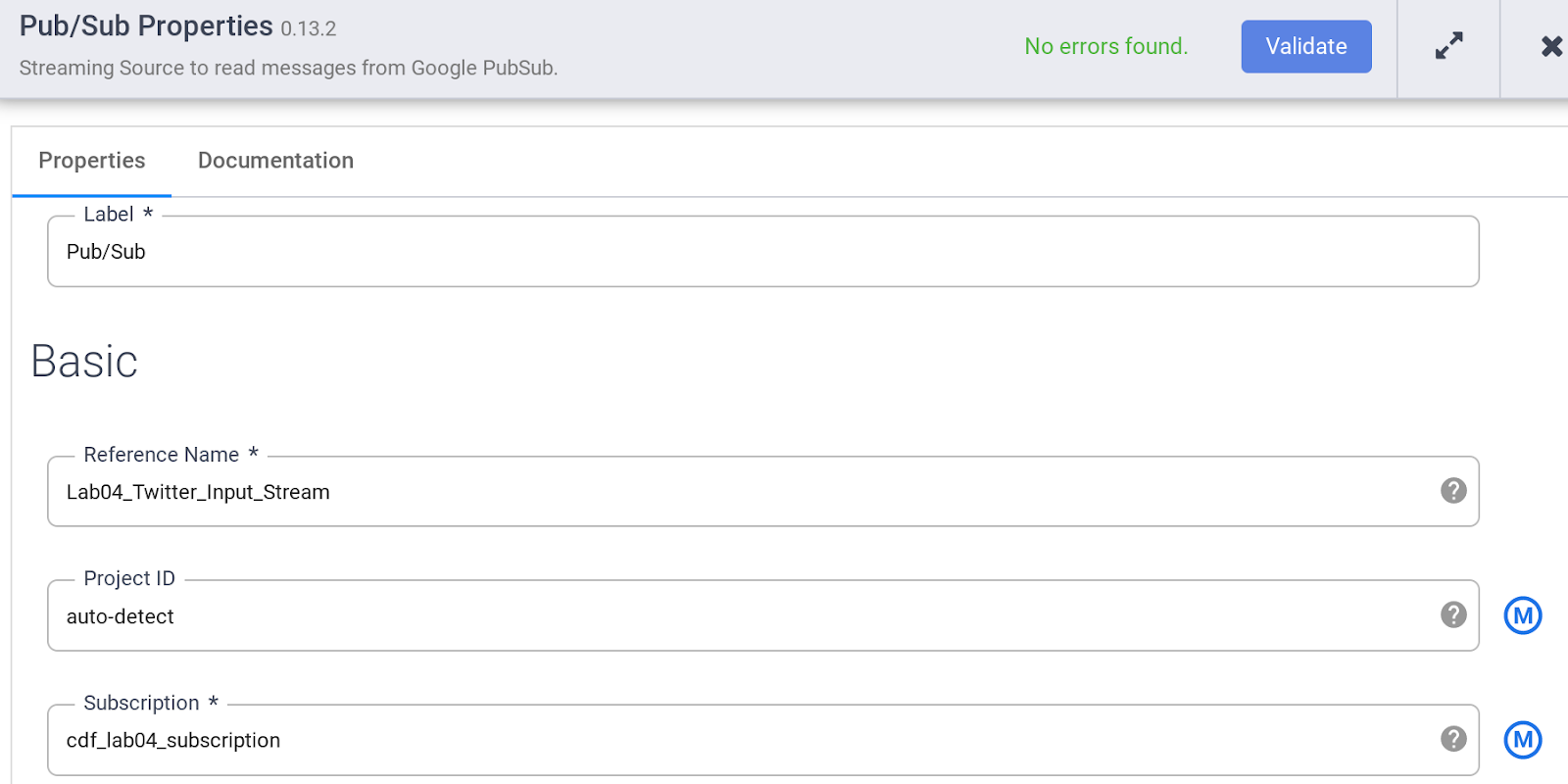
在插件面板的来源部分,选择 PubSub。PubSub 来源节点将显示在画布上,点击属性按钮即可打开。
指定 PubSub 来源的各种属性,如下所示:
a. 在参考名称下,输入 Twitter_Input_Stream
b. 在订阅下,输入 cdf_lab_subscription(这是您之前创建的 PubSub 订阅的名称)
c. 点击验证,确保没有错误。
d. 点击右上角的 X 关闭属性框。
请注意,由于您之前在 Wrangler 中使用了数据样本,因此来源列在 Wrangler 中显示为“body”。不过,PubSub 来源会在名为“message”的字段中发出数据。在下一步中,您将修复字段名称不一致的问题。
点击右上角的 X 关闭属性框。
现在,您已将来源和转换连接到流水线,接下来添加一个接收器来完成流水线。在左侧边栏的接收器部分,选择 BigQuery。画布上会显示一个 BigQuery 接收器节点。
将 Wrangler 节点连接到 BigQuery 节点,方法是将箭头从 Wrangler 节点拖动到 BigQuery 节点。接下来,您将配置 BigQuery 节点属性。
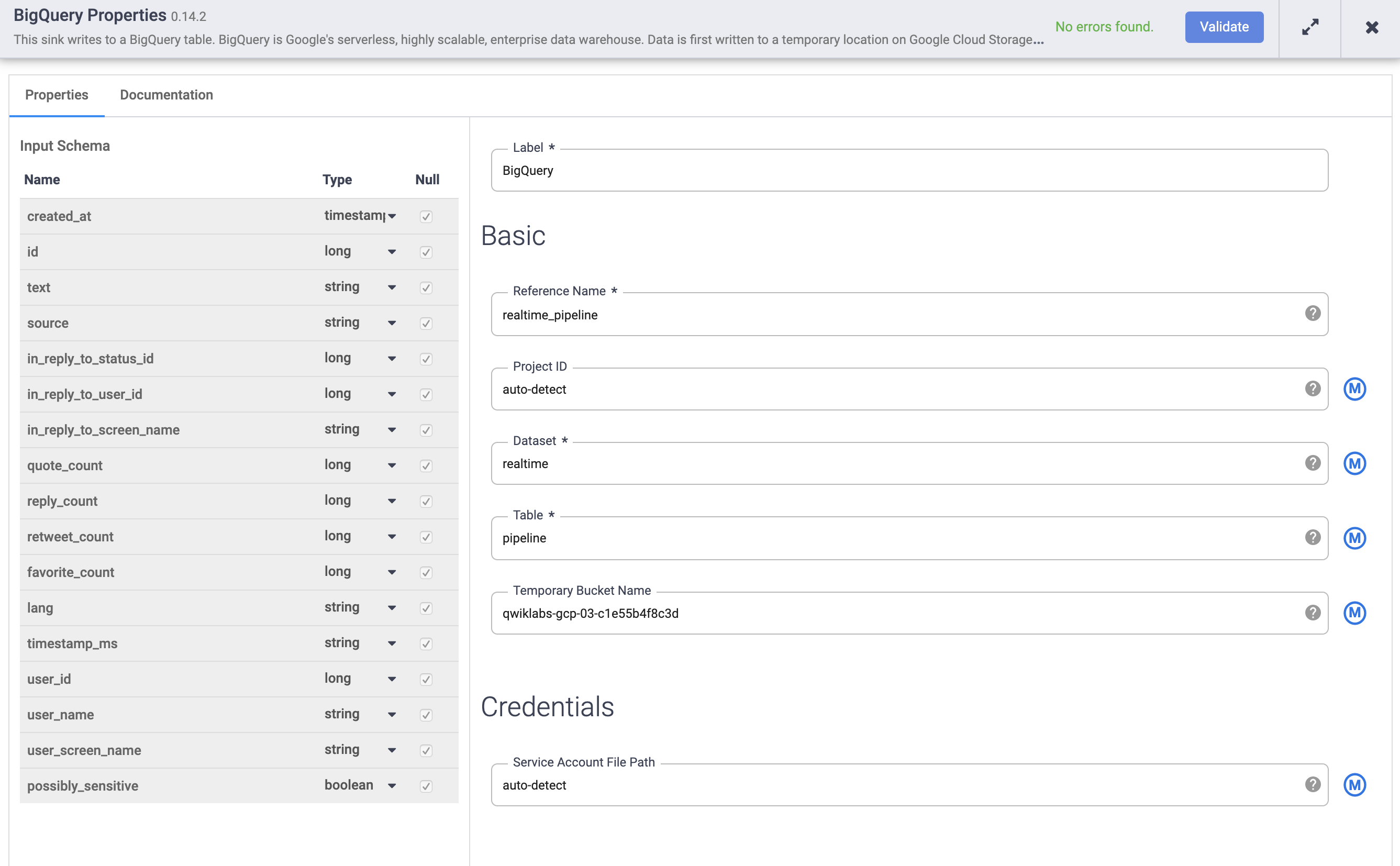
将鼠标悬停在 BigQuery 节点上,然后点击属性。
a. 在参考名称下,输入 realtime_pipeline
b. 在数据集下,输入 realtime
c. 在表下,输入 tweets
d. 点击验证,确保没有错误。
点击右上角的 X 关闭属性框。
点击 Name your pipeline(为流水线命名),添加 Realtime_Pipeline 作为名称,然后点击保存。
点击部署图标,然后启动流水线。
部署完成后,点击运行。等待流水线的状态变为“正在运行”。这需要几分钟时间。
使用 Dataflow 模板将事件批量加载到订阅中,以发送事件。
现在,您将基于模板创建一个 Dataflow 作业,以处理推文文件中的多条消息,并将这些消息发布到之前创建的 Pub/Sub 主题。在 Dataflow 的作业创建页面中,使用连续处理数据(流处理)下的 Text Files on Cloud Storage to Pub/Sub 模板。
返回 Cloud 控制台,依次点击导航菜单 > 查看所有产品,然后点击“分析”部分下的 Dataflow。
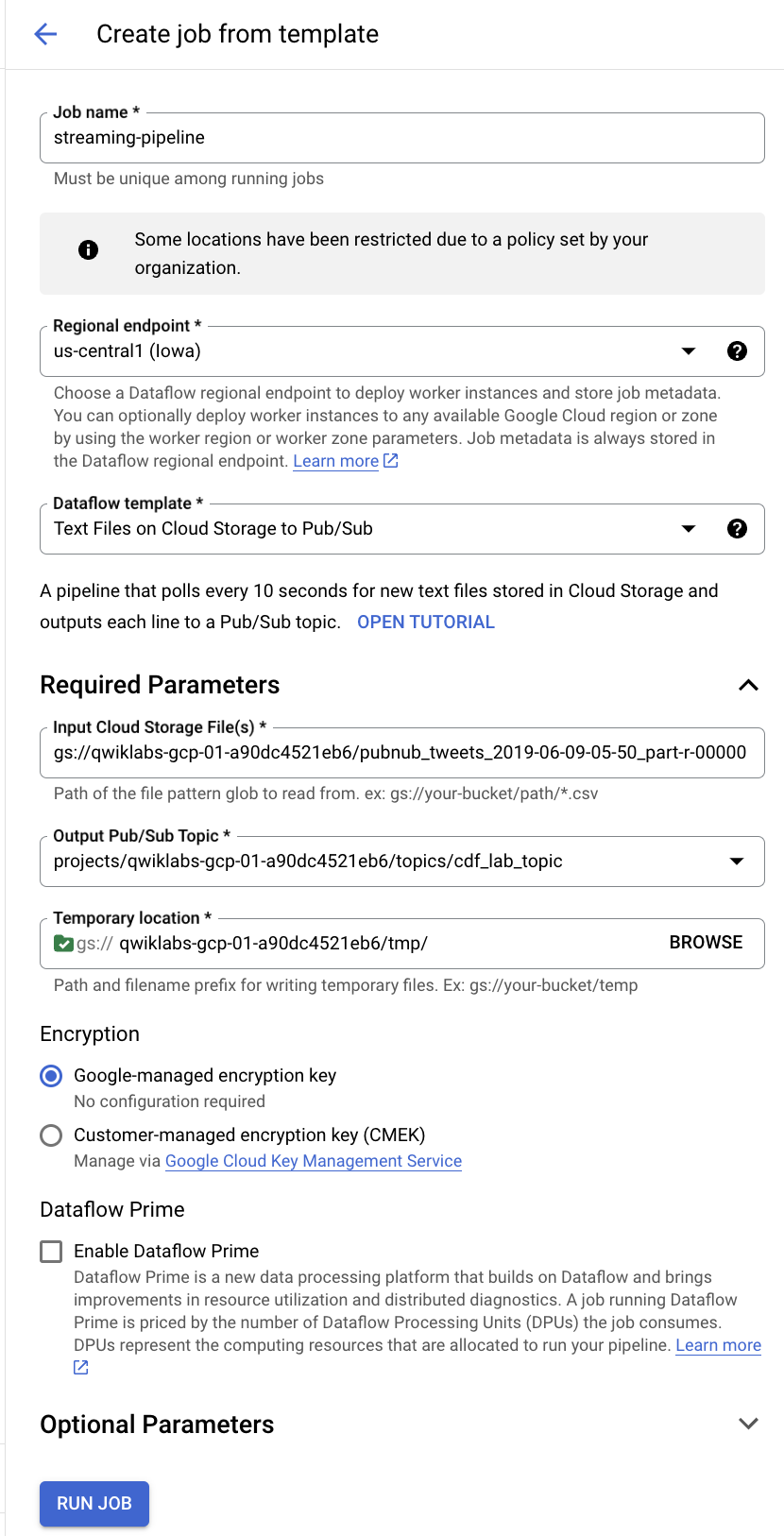
在顶部菜单栏中,点击基于模板创建作业。
输入 streaming-pipeline 作为 Cloud Dataflow 作业的名称。
在 Cloud Dataflow 模板下,选择 Text Files on Cloud Storage to Pub/Sub 模板。
在 Input Cloud Storage File(s)(输入 Cloud Storage 文件)下,输入 gs://<YOUR-BUCKET-NAME>/<FILE-NAME>
请务必将 <YOUR-BUCKET-NAME> 替换为您的存储桶名称,并将 <FILE-NAME> 替换为您之前下载到计算机中的文件名。
例如:gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
projects/<PROJECT-ID>/topics/cdf_lab_topic
请务必将 PROJECT-ID 替换为您的实际项目 ID。
<YOUR-BUCKET-NAME>/tmp/
请务必将 <YOUR-BUCKET-NAME> 替换为您的存储桶名称。
点击运行作业按钮。
执行 Dataflow 作业并等待几分钟。您可以查看 Pub/Sub 订阅中的消息,然后查看这些消息通过实时 CDF 流水线进行处理的过程。
点击“检查我的进度”以验证是否完成了以下目标:
事件加载到 Pub/Sub 主题后,您应该会看到流水线开始处理这些事件 - 请注意每个节点上的指标是否更新。
在 Data Fusion 控制台中,等待流水线指标发生变化
在本实验中,您学习了如何在 Data Fusion 中设置实时流水线,该流水线可以从 Cloud Pub/Sub 读取传入的流式消息、处理数据并将其写入 BigQuery。
本手册的最后更新时间:2025 年 2 月 6 日
本实验的最后测试时间:2025 年 2 月 6 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名称和产品名称可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验