GSP808

Visão geral
Além dos pipelines em lote, o Data Fusion também permite criar pipelines em tempo real para processar eventos conforme são gerados. Atualmente, os pipelines em tempo real usam o Apache Spark Streaming em clusters do Cloud Dataproc. Neste laboratório, você vai aprender a criar um pipeline de streaming usando o Data Fusion.
Você vai criar um pipeline que lê um tópico do Cloud Pub/Sub e processa os eventos, executa transformações e grava o resultado no BigQuery.
Objetivos
- Aprender a criar um pipeline em tempo real
- Aprender a configurar o plug-in de origem do Pub/Sub no Data Fusion
- Aprender a usar o Wrangler para definir transformações para dados localizados em conexões não compatíveis
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Faça login no Google Skills usando uma janela anônima.
-
Verifique o tempo de acesso do laboratório (por exemplo, 02:00:00) para conseguir finalizar todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
-
Quando tudo estiver pronto, clique em Começar o laboratório.
Observação: depois de clicar em Começar o laboratório, o tempo para provisionar os recursos necessários e criar uma instância do Data Fusion é de 15 a 20 minutos.
Enquanto isso, você pode conferir as etapas abaixo para conhecer as metas do laboratório.
Quando as credenciais do laboratório (nome de usuário e senha) aparecem no painel esquerdo, isso significa que a instância foi criada, e você pode continuar o login no console.
-
Anote as credenciais (nome de usuário e senha). É com elas que você vai fazer login no console do Google Cloud.
-
Clique em Abrir console do Google.
-
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Aceite os termos e pule a página de recursos de recuperação.
Observação: não clique em Terminar o laboratório a menos que você tenha concluído as atividades ou queira refazer tudo. Essa opção limpa as ações que você realizou e remove o projeto.
Fazer login no console do Google Cloud
- Na guia ou janela do navegador desta sessão de laboratório, copie o Nome de usuário do painel Detalhes da conexão e clique no botão Abrir console do Google.
Observação: se precisar escolher uma conta, clique em Usar outra conta.
- Cole o nome de usuário e a senha quando solicitado.
- Clique em Próxima.
- Aceite os Termos e Condições.
Como a conta é temporária, ela só dura até o final deste laboratório:
- não adicione opções de recuperação.
- não se inscreva em testes.
- Assim que o console abrir, clique no menu de navegação (
 ) no canto superior esquerdo para acessar a lista de serviços.
) no canto superior esquerdo para acessar a lista de serviços.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
-
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ( ).
).
-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:

Exemplo de comandos
gcloud auth list
(Saída)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemplo de saída)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Saída)
[core]
project = <project_ID>
(Exemplo de saída)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Tarefa 1: permissões do projeto
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
-
No Console do Google Cloud, acesse o menu de navegação () e clique em IAM e administrador > IAM.
-
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.

Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
-
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
-
No card Informações do projeto, copie o Número do projeto.
-
No Menu de navegação, clique em IAM e administrador > IAM.
-
Na parte superior da página IAM, clique em Adicionar.
-
Para Novos principais, digite:
{project-number}-compute@developer.gserviceaccount.com
Substitua {project-number} pelo número do seu projeto.
-
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
-
Clique em Salvar.
Tarefa 2: ativar a API Dataflow
Para ter acesso à API Dataflow, reinicie a conexão.
-
No console do Cloud, digite "API Dataflow" na barra de pesquisa superior. Clique no resultado para API Dataflow.
-
Selecione Gerenciar.
-
Clique em Desativar API.
Se for necessário confirmar, clique em Desativar.
- Clique em Ativar.
Tarefa 3: carregar os dados
- Primeiro, você precisa baixar os tweets de exemplo no seu computador. Carregue esse arquivo usando o Wrangler para criar etapas de transformação.
Você também vai precisar organizar o mesmo arquivo de tweets de exemplo no bucket do Cloud Storage. No fim deste laboratório, você vai transmitir os dados do bucket para um tópico do Pub/Sub.
- No Cloud Shell, execute os seguintes comandos para criar um novo bucket:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gsutil mb gs://$BUCKET
O bucket criado tem o mesmo do seu ID do projeto.
- Execute o comando abaixo para copiar o arquivo de tweets para o bucket:
gsutil cp gs://cloud-training/OCBL164/pubnub_tweets_2019-06-09-05-50_part-r-00000 gs://$BUCKET
- Verifique se o arquivo foi copiado para o bucket do Cloud Storage.
Clique em Verificar meu progresso para conferir o objetivo.
Carregar os dados
Tarefa 4: configurar o tópico do Pub/Sub
Crie um tópico para reter dados e uma assinatura para acessar as informações publicadas no tópico.
-
No console do Cloud, no Menu de navegação, clique em Ver todos os produtos. Na seção "Análise", clique em Pub/Sub e selecione Tópicos.
-
Selecione Criar tópico.
- O tópico precisa ter um nome exclusivo. Para este laboratório, o nome do tópico deve ser
cdf_lab_topic. Depois, clique em CRIAR.
Clique em Verificar meu progresso para conferir o objetivo.
configurar o tópico do Pub/Sub
Tarefa 5: adicionar uma assinatura do Pub/Sub
Ainda na página do tópico, você verá como fazer uma assinatura para acessá-lo.
- Clique em Criar assinatura.
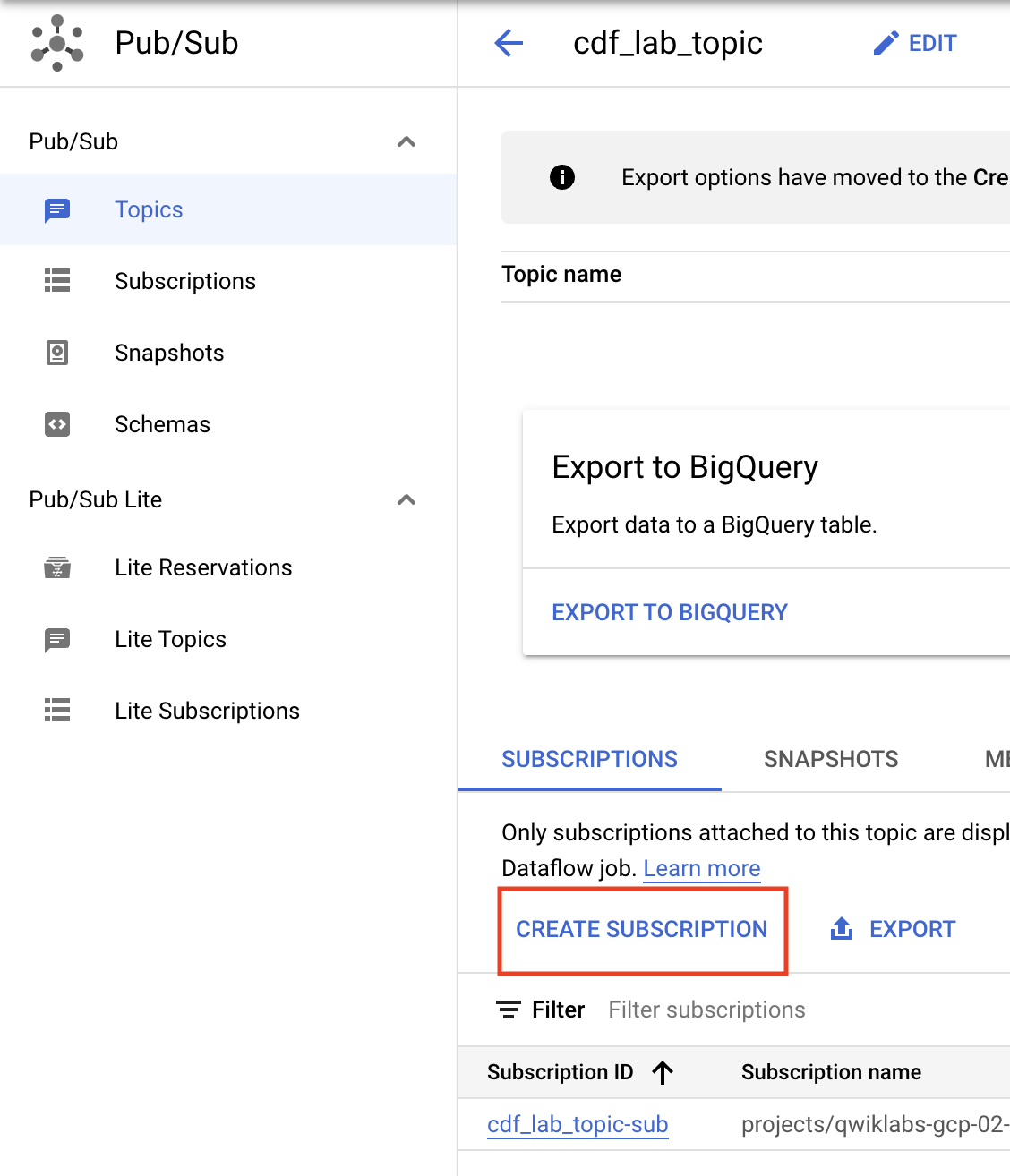
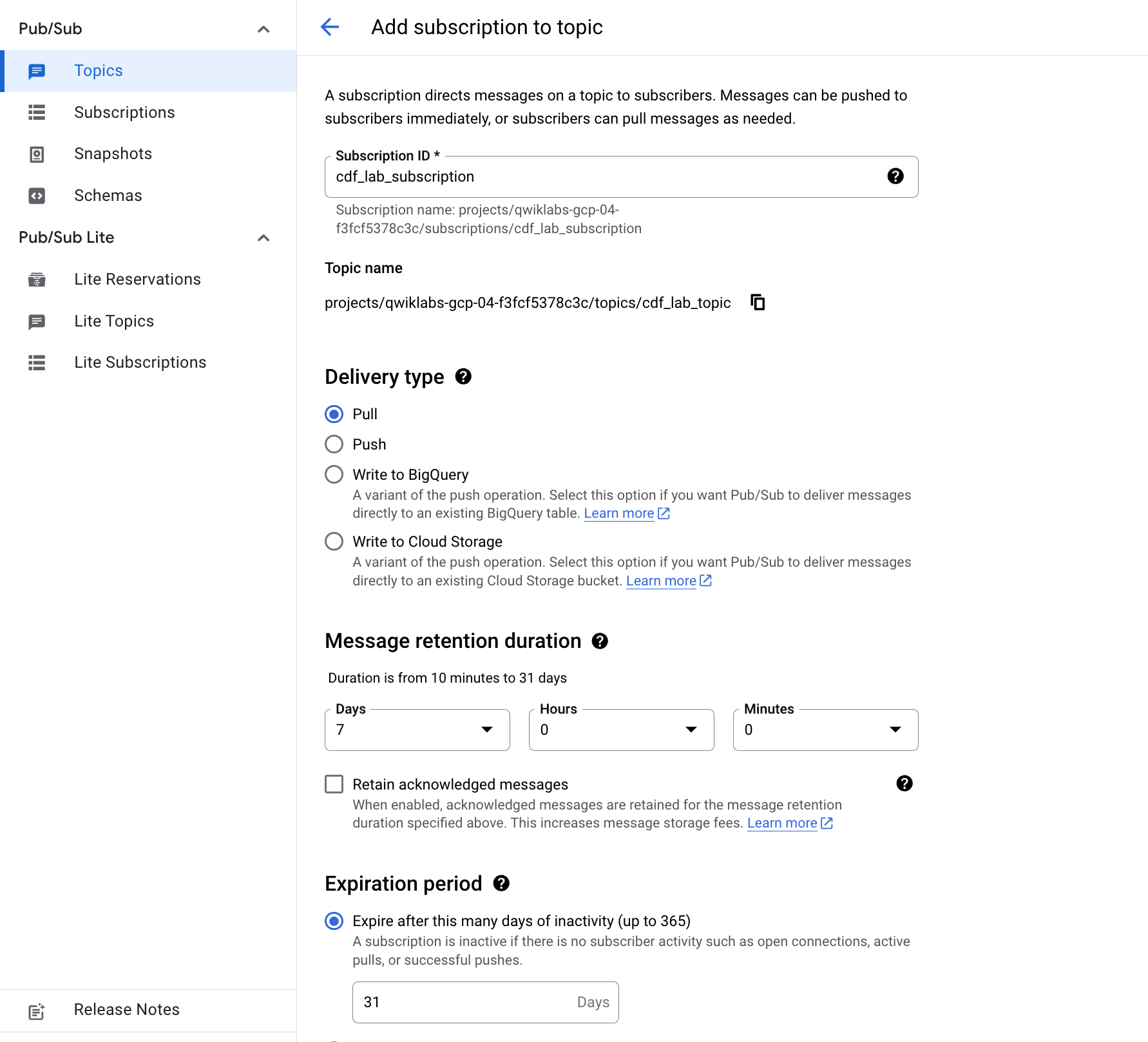
- Escolha um nome para a assinatura, como
cdf_lab_subscription, defina o tipo de entrega como Pull e clique em Criar.
Clique em Verificar meu progresso para conferir o objetivo.
adicionar uma assinatura do Pub/Sub
Tarefa 6: adicionar as permissões necessárias para a instância do Cloud Data Fusion
- No console do Google Cloud, no Menu de navegação, clique em Ver todos os produtos. Na seção "Análise", clique em Data Fusion > Instâncias.
Observação: a criação da instância leva cerca de 20 minutos. Aguarde até que ela fique pronta.
Em seguida, conceda permissões à conta de serviço associada à instância seguindo estas etapas:
-
No console do Google Cloud, acesse IAM e admin > IAM.
-
Confirme se a conta de serviço padrão do Compute Engine {project-number}-compute@developer.gserviceaccount.com está presente. Copie a conta de serviço para a área de transferência.
-
Na página de permissões do IAM, clique em +Conceder acesso.
-
No campo "Novos principais", cole a conta de serviço.
-
Clique no campo Selecionar um papel, comece a digitar Agente de serviço da API Cloud Data Fusion e selecione essa opção.
-
Clique em ADICIONAR OUTRO PAPEL.
-
Adicione o papel Administrador do Dataproc.
-
Clique em Salvar.
Clique em Verificar meu progresso para conferir o objetivo.
Adicionar um papel de agente de serviço da API Cloud Data Fusion à conta de serviço
Conceder permissão do usuário para a conta de serviço
-
No console, acesse o Menu de navegação e clique em IAM e admin > IAM.
-
Marque a caixa de seleção Incluir concessões do papel fornecidas pelo Google.
-
Role a lista para baixo até encontrar a conta de serviço do Cloud Data Fusion gerenciada pelo Google com esta estrutura: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com e copie o nome da conta de serviço para a área de transferência.

-
Em seguida, acesse IAM e admin > Contas de serviço.
-
Clique na conta padrão do Compute Engine com esta estrutura: {project-number}-compute@developer.gserviceaccount.com. Depois disso, selecione a guia Principais com acesso na parte de cima do menu de navegação.
-
Clique no botão Permitir acesso.
-
No campo Novos principais, cole a conta de serviço que você copiou mais cedo.
-
No menu suspenso Papel, selecione Usuário da conta de serviço.
-
Clique em Salvar.
Tarefa 7: navegar pela interface do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o console do Cloud e a interface separada do Cloud Data Fusion. No console do Cloud, é possível criar um projeto do console do Cloud e criar e excluir instâncias do Cloud Data Fusion. Na interface do Cloud Data Fusion, é possível usar as várias páginas, como o Pipeline Studio ou o Wrangler, para acessar os recursos.
Para navegar na interface do Cloud Data Fusion, siga estas etapas:
- No console do Cloud, retorne ao Data Fusion e clique no link Visualizar instância ao lado da instância do Data Fusion. Selecione suas credenciais do laboratório para fazer login. Se o serviço oferecer um tour, clique em Agora não. Agora você está usando a interface do Cloud Data Fusion.
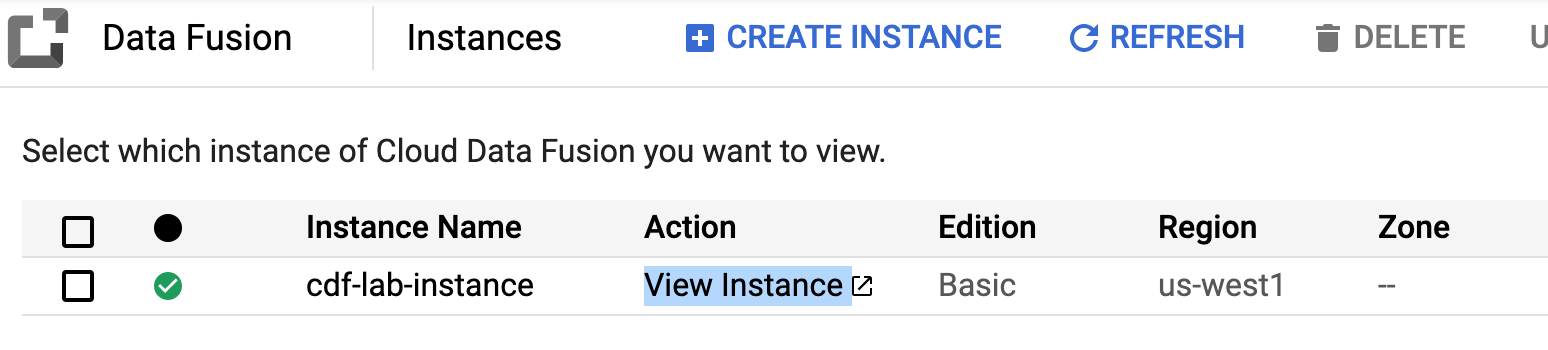
-
Na central de controle do Cloud Data Fusion, use o Menu de navegação para abrir o menu à esquerda e escolha Pipeline > Studio.
-
No canto superior esquerdo, use o menu suspenso para selecionar Pipeline de dados – tempo real.
Tarefa 8: criar um pipeline em tempo real
Ao trabalhar com dados, é útil conferir como são os dados brutos para que seja possível usá-los como ponto de partida para a transformação. Você vai usar o Wrangler para preparar e limpar os dados. Essa abordagem focada em dados permite visualizar rapidamente as transformações, enquanto o feedback em tempo real garante que você esteja no caminho certo.
-
Na seção Transformação da paleta de plug-ins, selecione Wrangler. O nó do Wrangler vai aparecer na tela. Clique no botão Propriedades para abri-lo.
-
Clique no botão WRANGLE na seção Diretivas.
-
Depois que carregar, clique em Fazer upload no menu à esquerda. Em seguida, clique no ícone de upload para enviar o arquivo de tweets de exemplo que você baixou anteriormente.
- Os dados são carregados na tela do Wrangler, no formato de linhas e colunas. Essa operação vai levar alguns minutos.
Observação: considere que esse é um exemplo dos eventos que você vai receber no Pub/Sub e representa cenários reais, em que você não tem acesso a dados de produção durante o desenvolvimento do pipeline.
Porém, o admin pode dar acesso a uma pequena amostra, ou você pode trabalhar com dados simulados que aderem ao contrato da API. Nesta seção, você vai aplicar transformações ao exemplo de forma iterativa, recebendo feedback em cada etapa. Em seguida, você vai aprender a reproduzir as transformações em dados reais.
-
A primeira operação é analisar os dados JSON brutos em uma representação tabular dividida em linhas e colunas. Para fazer isso, selecione o ícone do menu suspenso no cabeçalho da primeira coluna (body) e, em seguida, selecione o item de menu Analisar e JSON no submenu. Na janela pop-up, defina a Profundidade como 1 e clique em Aplicar.
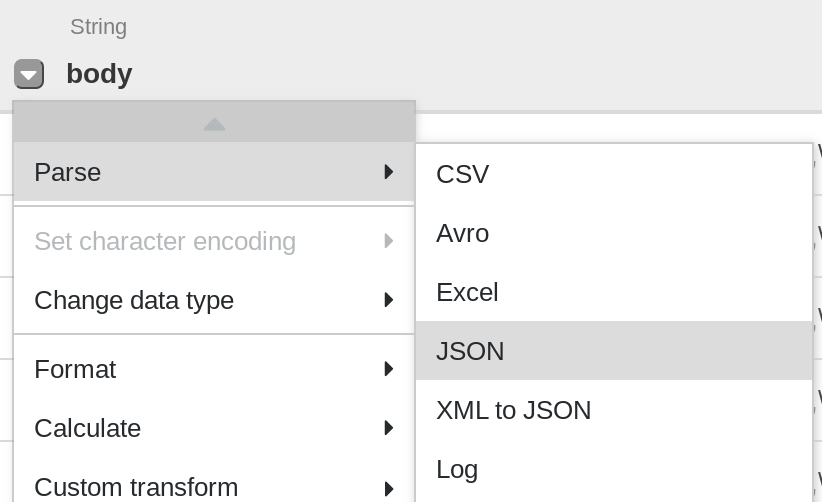
-
Repita a etapa anterior para ver uma estrutura de dados mais significativa para as próximas transformações. Clique no ícone do menu suspenso da coluna body, selecione Analisar > JSON e defina a Profundidade como 1. Depois, clique em Aplicar.
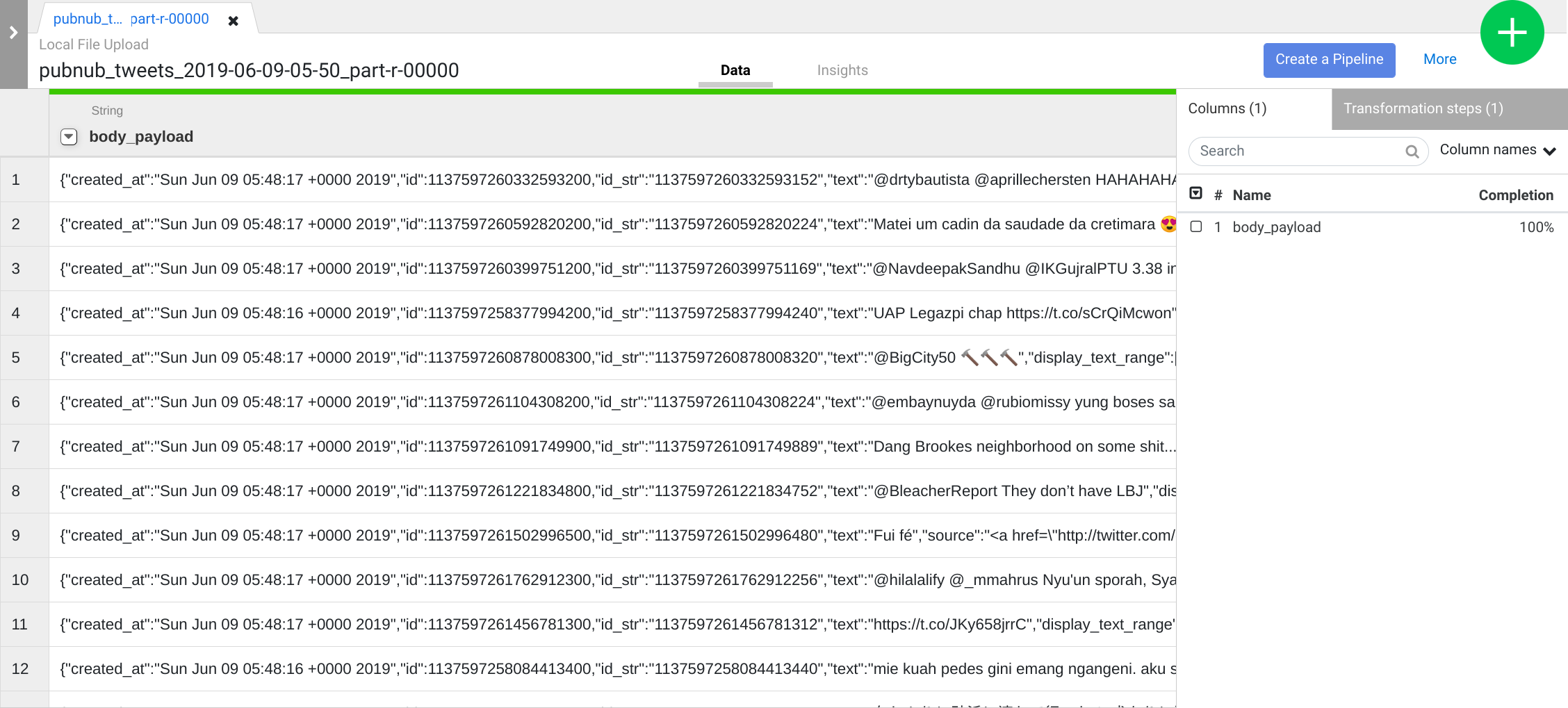
Além de usar a interface, você também pode escrever etapas de transformação na caixa da linha de comando das diretivas do Wrangler. A caixa aparece na parte inferior da interface do wrangler (procure o console de comandos com um $ verde).
Na próxima etapa, você vai usar o console de comandos para colar um conjunto de etapas de transformação.
-
Copie as etapas de transformação abaixo e cole-as na caixa da linha de comando da diretiva do Wrangler:
columns-replace s/^body_payload_//g
drop id_str
parse-as-simple-date :created_at EEE MMM dd HH:mm:ss Z yyyy
drop display_text_range
drop truncated
drop in_reply_to_status_id_str
drop in_reply_to_user_id_str
parse-as-json :user 1
drop coordinates
set-type :place string
drop geo,place,contributors,is_quote_status,favorited,retweeted,filter_level,user_id_str,user_url,user_description,user_translator_type,user_protected,user_verified,user_followers_count,user_friends_count,user_statuses_count,user_favourites_count,user_listed_count,user_is_translator,user_contributors_enabled,user_lang,user_geo_enabled,user_time_zone,user_utc_offset,user_created_at,user_profile_background_color,user_profile_background_image_url,user_profile_background_image_url_https,user_profile_background_tile,user_profile_link_color,user_profile_sidebar_border_color,user_profile_sidebar_fill_color,user_profile_text_color,user_profile_use_background_image
drop user_following,user_default_profile_image,user_follow_request_sent,user_notifications,extended_tweet,quoted_status_id,quoted_status_id_str,quoted_status,quoted_status_permalink
drop user_profile_image_url,user_profile_image_url_https,user_profile_banner_url,user_default_profile,extended_entities
fill-null-or-empty :possibly_sensitive 'false'
set-type :possibly_sensitive boolean
drop :entities
drop :user_location
Observação: se aparecer a mensagem "Não há dados. Tente remover algumas etapas de transformação", remova uma das etapas de transformação clicando em X. Quando os dados aparecerem, você poderá continuar.
- Clique no botão Aplicar no canto superior direito. Em seguida, clique em X no canto superior direito para fechar a caixa de propriedades.
Veja que você está de volta ao Pipeline Studio, em que um único nó foi colocado na tela, representando as transformações que você acabou de definir no Wrangler. No entanto, não há nenhuma fonte conectada ao pipeline. Como explicado acima, você aplicou as transformações em uma amostra dos dados no seu notebook, e não nos dados no local de produção real.
Na próxima etapa, vamos especificar onde ficam os dados.
-
Na seção Origem da paleta de plug-ins, selecione PubSub. O nó de origem do Pub/Sub vai aparecer na tela. Clique no botão Propriedades para abri-lo.
-
Especifique as várias propriedades da fonte do Pub/Sub desta forma:
a. Em Nome de referência, digite Twitter_Input_Stream
b. Em Assinatura, insira cdf_lab_subscription. Esse é o nome da assinatura do Pub/Sub que você criou anteriormente.
Observação: a origem do Pub/Sub não aceita o nome de assinatura totalmente qualificado, somente o último componente após a parte ".../subscriptions/".
c. Clique em Validar para garantir que não haja nenhum erro.
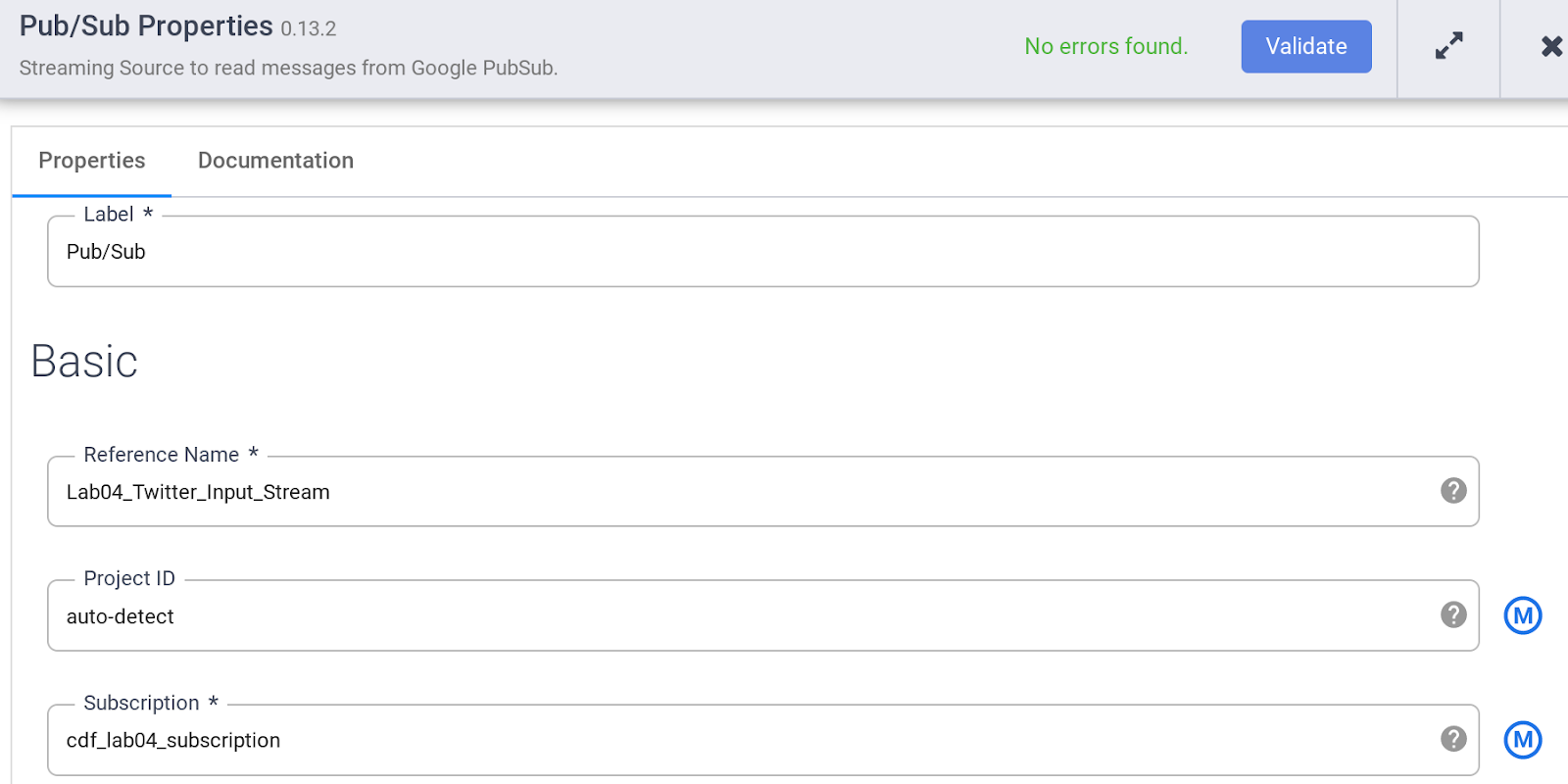
d. Clique em X no canto superior direito para fechar a caixa de propriedades.
- Agora conecte o nó de origem do Pub/Sub ao nó do Wrangler que você adicionou anteriormente.
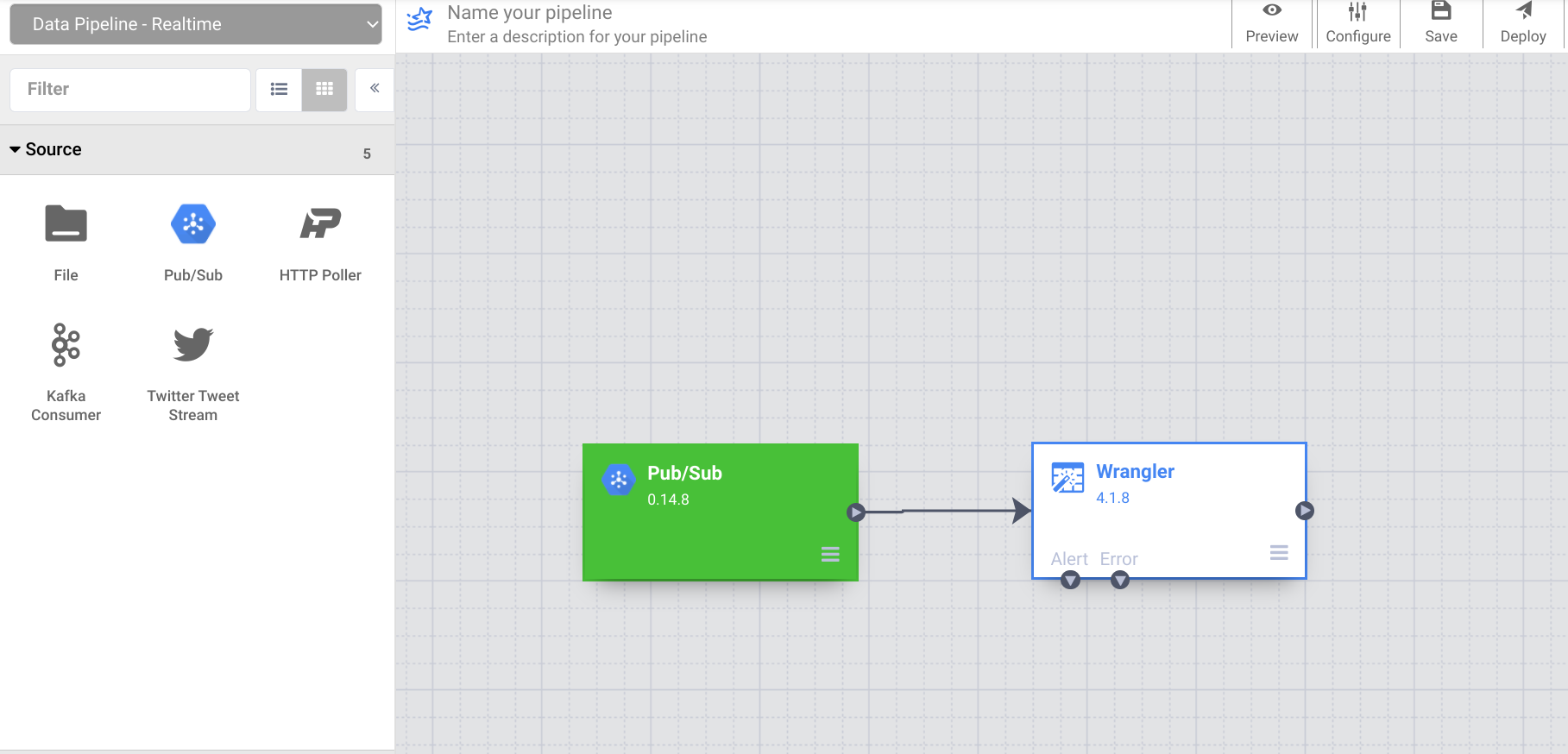
Como você usou uma amostra dos dados no Wrangler, a coluna de origem apareceu como "body" nele. No entanto, a origem do PubSub emite esse valor em um campo com o nome "message". Você vai corrigir essa discrepância na próxima etapa.
- Abra as propriedades do nó do Wrangler e adicione a diretiva abaixo na parte de cima das etapas de transformação atuais:
keep :message
set-charset :message 'utf-8'
rename :message :body
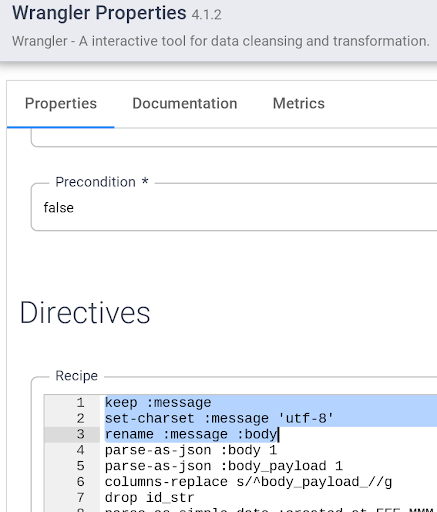
Clique em X no canto superior direito para fechar a caixa de propriedades.
-
Agora que você conectou uma origem e uma transformação ao pipeline, pode adicionar um coletor para concluí-lo. Na seção Coletor do painel lateral esquerdo, selecione BigQuery. Um nó do coletor do BigQuery aparece na tela.
-
Arraste o nó do Wrangler para o nó do BigQuery para conectá-los. Em seguida, você vai configurar as propriedades do nó do BigQuery.

-
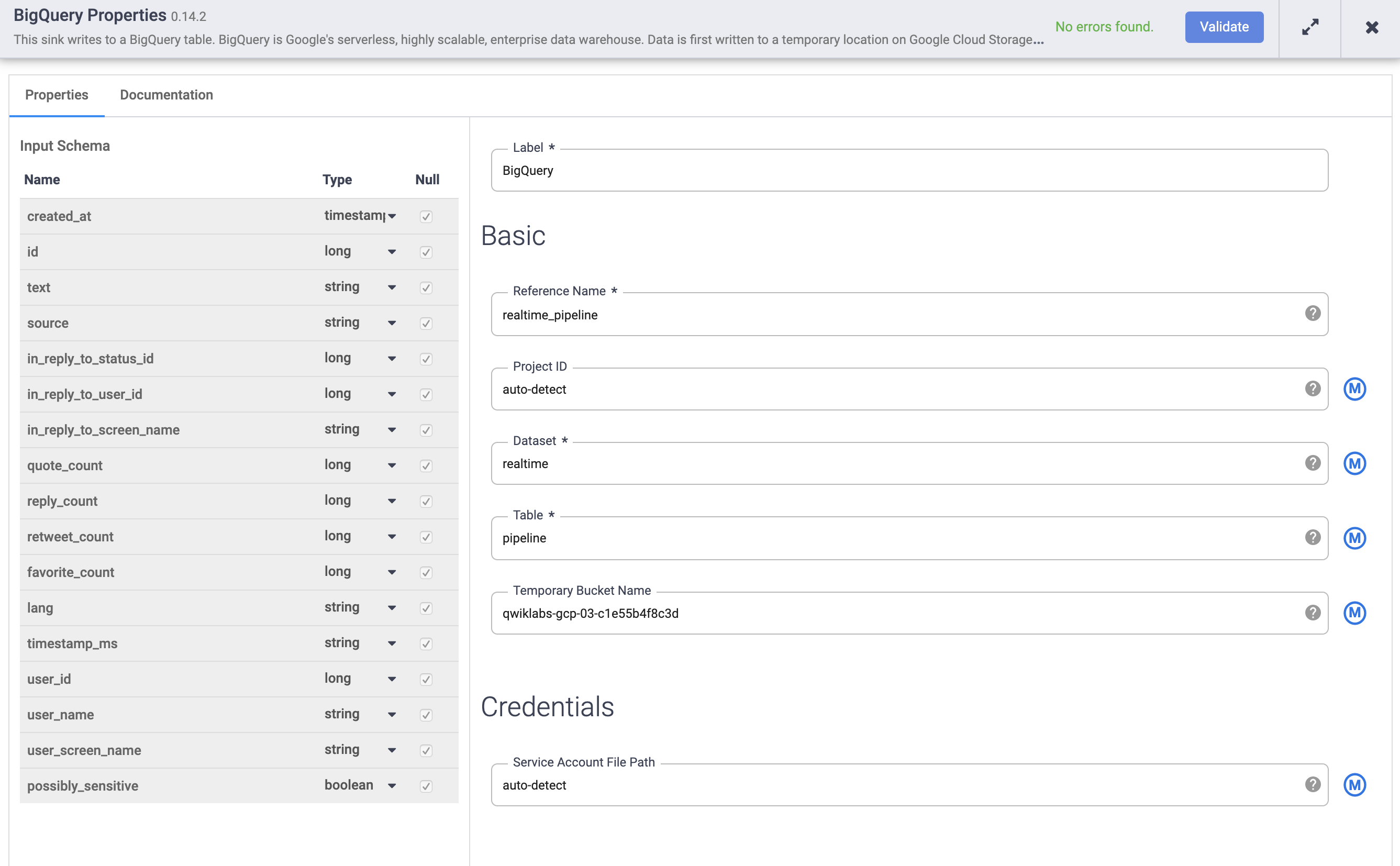
Passe o cursor sobre o nó do BigQuery e clique em Propriedades.
a. Em Nome de referência, digite realtime_pipeline
b. Em Conjunto de dados, digite realtime
c. Em Tabela, insira tweets
d. Clique em Validar para garantir que não haja nenhum erro.
-
Clique em X no canto superior direito para fechar a caixa de propriedades.
-
Clique em Nomear pipeline, digite Realtime_Pipeline e clique em Salvar.
-
Clique no ícone Implantar e inicie o pipeline.
-
Depois da implantação, clique em Executar. Aguarde até que o Status do pipeline mude para Em execução. Essa operação vai levar alguns minutos.
Tarefa 9: enviar mensagens para o Cloud Pub/Sub
Carregue os eventos em massa na assinatura usando o modelo do Dataflow para enviá-los.
Agora você vai criar um job do Dataflow com base em um modelo para processar várias mensagens do arquivo tweets e publicá-las no tópico do Pub/Sub criado anteriormente. Use o modelo Text Files on Cloud Storage to Pub/Sub em Processar dados continuamente (stream) na página de criação de jobs do Dataflow.
-
No console do Cloud, acesse o Menu de navegação, clique em Ver todos os produtos. Na seção "Análise", clique em Dataflow.
-
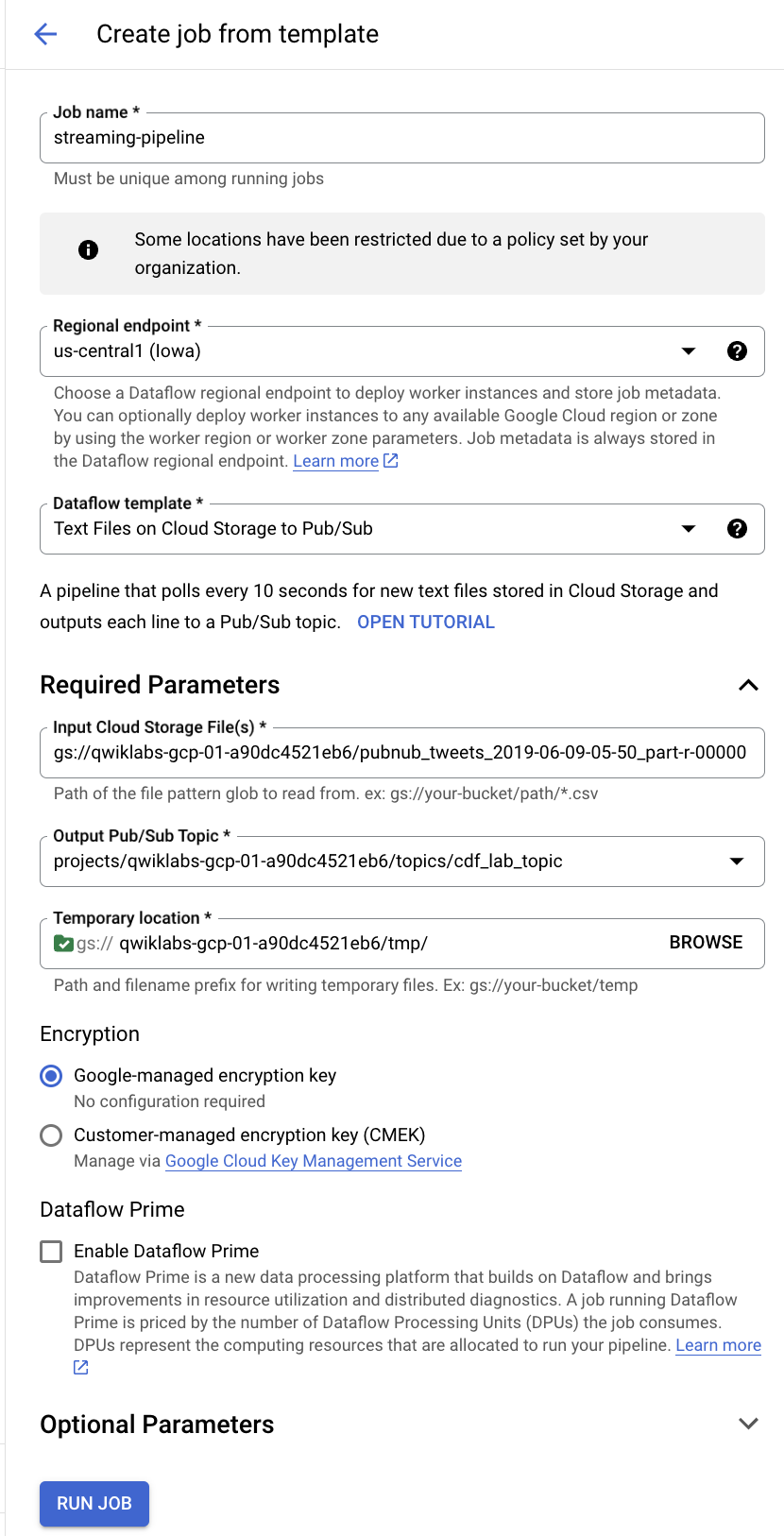
Na barra do menu superior, clique em CRIAR JOB A PARTIR DE UM MODELO.
-
Digite streaming-pipeline como o nome do job do Cloud Dataflow.
-
Em modelo Dataflow no Cloud, selecione o modelo Text Files on Cloud Storage to Pub/Sub.
-
Em Arquivos de entrada do Cloud Storage, insira gs://<YOUR-BUCKET-NAME>/<FILE-NAME>
Substitua <YOUR-BUCKET-NAME> pelo nome do bucket e <FILE-NAME> pelo nome do arquivo que você baixou no seu computador.
Por exemplo: gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
- Em Tópico de saída do Pub/Sub, insira
projects/<PROJECT-ID>/topics/cdf_lab_topic
Substitua PROJECT-ID pelo ID do projeto.
- Em Local temporário, insira
<YOUR-BUCKET-NAME>/tmp/
Substitua <YOUR-BUCKET-NAME> pelo nome do bucket.
-
Clique no botão Executar job.
-
Execute o job do Dataflow e aguarde alguns minutos. Você pode ver as mensagens na assinatura do Pub/Sub e, em seguida, ver o processamento pelo pipeline CDF em tempo real.
Clique em Verificar meu progresso para conferir o objetivo.
Criar e executar o pipeline do ambiente de execução
Tarefa 10: visualizar as métricas do pipeline
Quando os eventos forem carregados no tópico do Pub/Sub, você os verá sendo consumidos pelo pipeline. Observe as métricas em cada nó sendo atualizadas.
Parabéns!
Neste laboratório, você aprendeu a configurar um pipeline em tempo real no Data Fusion que lê mensagens de streaming recebidas do Cloud Pub/Sub, processa os dados e os grava no BigQuery.
Manual atualizado em 6 de fevereiro de 2025
Laboratório testado em 6 de fevereiro de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.







