GSP808

Übersicht
Neben Batchpipelines können Sie mit Data Fusion auch Echtzeitpipelines erstellen, die Ereignisse verarbeiten, sobald sie generiert werden. Derzeit werden Echtzeitpipelines mit Apache Spark Streaming auf Cloud Dataproc-Clustern ausgeführt. In diesem Lab erfahren Sie, wie Sie mit Data Fusion eine Streamingpipeline erstellen.
Sie erstellen eine Pipeline, die aus einem Cloud Pub/Sub-Thema liest, die Ereignisse verarbeitet, einige Transformationen ausführt und die Ausgabe in BigQuery schreibt.
Ziele
- Echtzeitpipeline erstellen
- Pub/Sub-Quell-Plug-in in Data Fusion konfigurieren
- Mit Wrangler Transformationen für Daten in nicht unterstützten Verbindungen definieren
Einrichtung und Anforderungen
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
-
Melden Sie sich über ein Inkognitofenster bei Google Skills an.
-
Beachten Sie die Zugriffszeit (z. B. 02:00:00) und achten Sie darauf, dass Sie das Lab innerhalb dieser Zeit abschließen.
Es gibt keine Pausenfunktion. Sie können bei Bedarf neu starten, müssen dann aber von vorn beginnen.
-
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Hinweis: Nachdem Sie auf Lab starten geklickt haben, dauert es etwa 15 bis 20 Minuten, bis die erforderlichen Ressourcen für das Lab bereitgestellt und eine Data Fusion-Instanz erstellt wurden.
In der Zwischenzeit können Sie sich anhand der unten aufgeführten Schritte mit den Zielen des Labs vertraut machen.
Wenn im linken Bereich Lab-Anmeldedaten (Nutzername und Passwort) angezeigt werden, ist die Instanz erstellt und Sie können sich in der Console anmelden.
-
Notieren Sie sich Ihre Anmeldedaten (Nutzername und Passwort). Mit diesen Daten melden Sie sich in der Google Cloud Console an.
-
Klicken Sie auf Google Console öffnen.
-
Klicken Sie auf Anderes Konto verwenden. Kopieren Sie den Nutzernamen und das Passwort für dieses Lab und fügen Sie beides in die entsprechenden Felder ein.
Wenn Sie andere Anmeldedaten verwenden, tritt ein Fehler auf oder es fallen Kosten an.
-
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen.
Hinweis: Über den Button Lab beenden wird Ihre Arbeit gelöscht und das Projekt entfernt. Sie sollten daher nur darauf klicken, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten.
Bei der Google Cloud Console anmelden
- Kopieren Sie im Browsertab oder Fenster für diese Lab-Sitzung im Bereich Verbindungsdetails den Nutzernamen und klicken Sie auf den Button Google Console öffnen.
Hinweis: Wenn die Eingabeaufforderung „Konto auswählen“ angezeigt wird, klicken Sie auf Anderes Konto verwenden.
- Fügen Sie den Nutzernamen und das Passwort ein, wenn Sie dazu aufgefordert werden.
- Klicken Sie auf Weiter.
- Akzeptieren Sie die Nutzungsbedingungen.
Da es sich um ein temporäres Konto handelt, das nur für die Dauer dieses Labs verfügbar ist, beachten Sie bitte Folgendes:
- Fügen Sie keine Wiederherstellungsoptionen hinzu.
- Melden Sie sich nicht für kostenlose Testversionen an.
- Wenn die Console geöffnet wurde, klicken Sie oben links auf das Navigationsmenü (
 ), um die Liste der Dienste aufzurufen.
), um die Liste der Dienste aufzurufen.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Cloud Shell bietet Ihnen Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen. gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
-
Klicken Sie in der Google Cloud Console im Navigationsbereich auf Cloud Shell aktivieren ( ).
).
-
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:

Beispielbefehle
gcloud auth list
(Ausgabe)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Beispielausgabe)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Ausgabe)
[core]
project = <project_ID>
(Beispielausgabe)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Aufgabe 1: Projektberechtigungen
Projektberechtigungen prüfen
Bevor Sie mit der Arbeit in Google Cloud beginnen, müssen Sie sicherstellen, dass für Ihr Projekt im Rahmen von Identity and Access Management (IAM) die nötigen Berechtigungen vorliegen.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf IAM und Verwaltung > IAM.
-
Prüfen Sie, ob das standardmäßige Compute-Dienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden und ihm die Rolle Bearbeiter zugewiesen ist. Das Kontopräfix ist die Projektnummer. Sie finden sie im Navigationsmenü unter Cloud-Übersicht.

Wenn das Konto nicht in IAM vorhanden ist oder nicht über die Bearbeiter-Rolle verfügt, weisen Sie die erforderliche Rolle so zu:
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf Cloud-Übersicht.
-
Kopieren Sie auf der Karte Projektinformationen die Projektnummer.
-
Klicken Sie im Navigationsmenü auf IAM und Verwaltung > IAM.
-
Klicken Sie oben auf der Seite IAM auf Hinzufügen.
-
Geben Sie unter Neue Hauptkonten ein:
{project-number}-compute@developer.gserviceaccount.com
Ersetzen Sie {project-number} durch die entsprechende Projektnummer.
-
Wählen Sie unter Rolle auswählen die Option Basic (oder „Projekt“) > Editor aus.
-
Klicken Sie auf Speichern.
Aufgabe 2: Dataflow API neu aktivieren
Damit Sie Zugriff auf die erforderliche API haben, starten Sie die Verbindung zur Dataflow API neu.
-
Geben Sie in der Cloud Console oben in der Suchleiste „Dataflow API“ ein. Klicken Sie auf das Ergebnis für Dataflow API.
-
Klicken Sie auf Verwalten.
-
Klicken Sie auf API deaktivieren.
Wenn Sie zur Bestätigung aufgefordert werden, klicken Sie auf Deaktivieren.
- Klicken Sie auf Aktivieren.
Aufgabe 3: Daten laden
- Laden Sie zuerst die Beispiel-Tweets auf Ihren Computer herunter. Sie laden diese später mit Wrangler hoch, um Transformationsschritte zu erstellen.
Außerdem müssen Sie die Datei mit den Beispiel-Tweets in Ihrem Cloud Storage-Bucket bereitstellen. Später in diesem Lab streamen Sie die Daten aus Ihrem Bucket in ein Pub/Sub-Thema.
- Führen Sie in Cloud Shell die folgenden Befehle aus, um einen neuen Bucket zu erstellen:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gsutil mb gs://$BUCKET
Der Name des erstellten Buckets entspricht der Projekt-ID.
- Führen Sie den folgenden Befehl aus, um die Datei mit den Tweets in den Bucket zu kopieren:
gsutil cp gs://cloud-training/OCBL164/pubnub_tweets_2019-06-09-05-50_part-r-00000 gs://$BUCKET
- Prüfen Sie, ob die Datei in Ihren Cloud Storage-Bucket kopiert wurde.
Klicken Sie auf Fortschritt prüfen.
Daten laden
Aufgabe 4: Pub/Sub-Thema einrichten
Um Pub/Sub zu verwenden, müssen Sie ein Thema, das die Daten enthalten soll, und ein Abo erstellen, über das auf die unter diesem Thema veröffentlichten Daten zugegriffen werden kann.
-
Klicken Sie in der Cloud Console im Navigationsmenü auf Alle Produkte ansehen. Klicken Sie im Abschnitt „Analytics“ auf Pub/Sub und wählen Sie dann Themen aus.
-
Klicken Sie auf Thema erstellen.
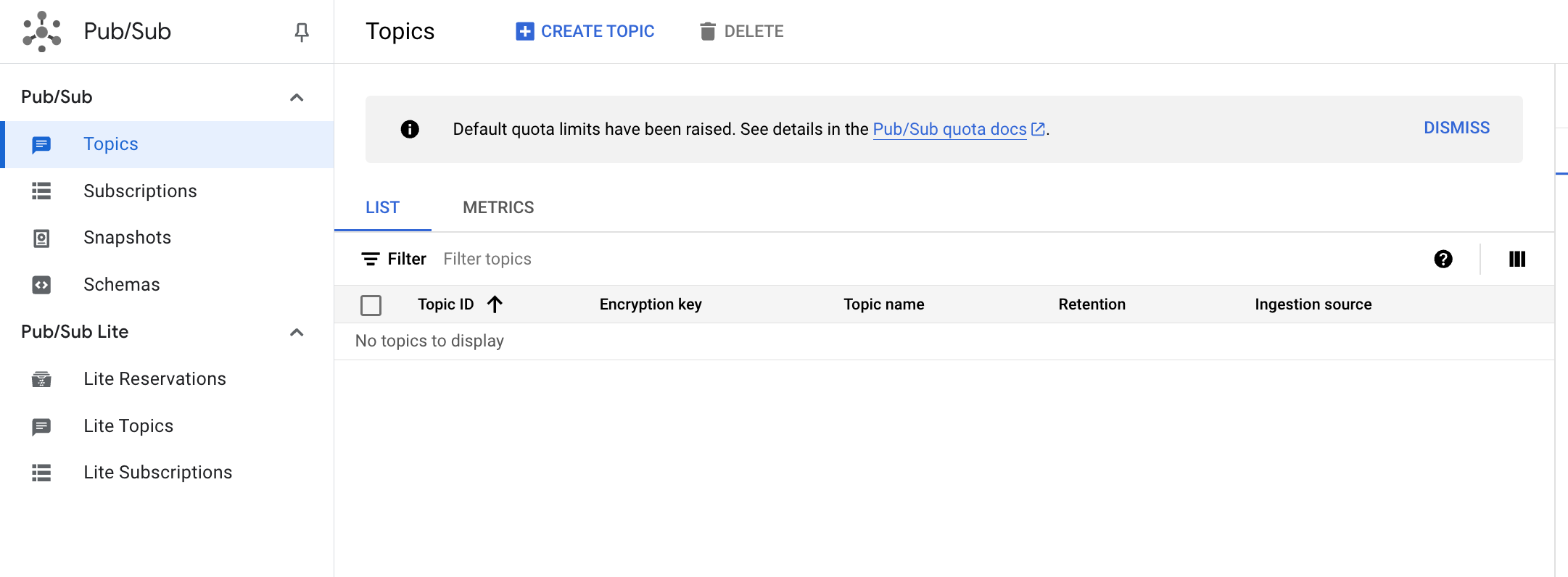
- Das Thema muss einen eindeutigen Namen haben. Geben Sie für dieses Lab den Namen
cdf_lab_topic ein und klicken Sie dann auf ERSTELLEN.
Klicken Sie auf Fortschritt prüfen.
Pub/Sub-Thema einrichten
Aufgabe 5: Pub/Sub-Abo hinzufügen
Sie arbeiten weiter auf der Themenseite. Jetzt richten Sie ein Abo ein, um auf das Thema zuzugreifen.
- Klicken Sie auf Abo erstellen.
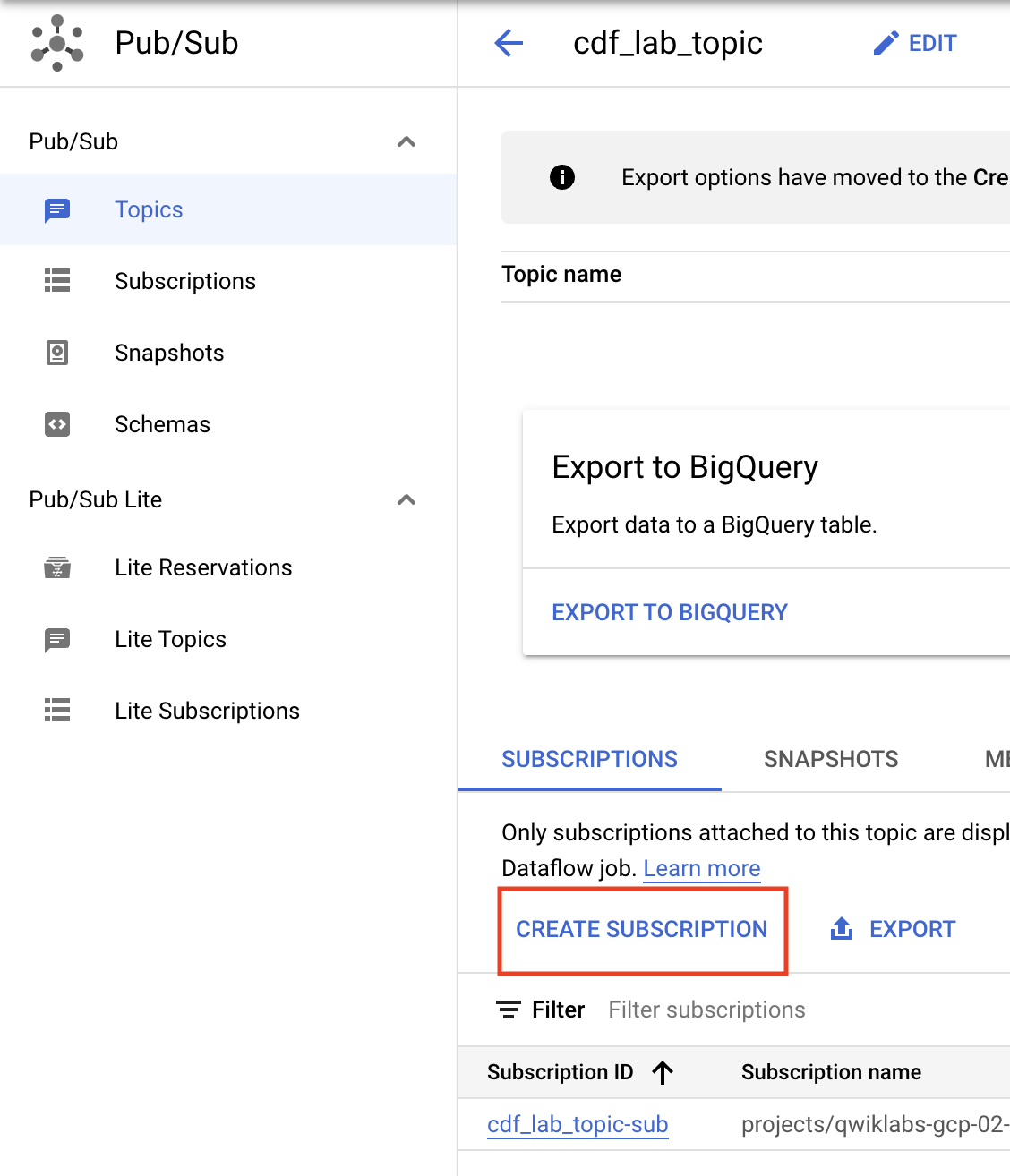
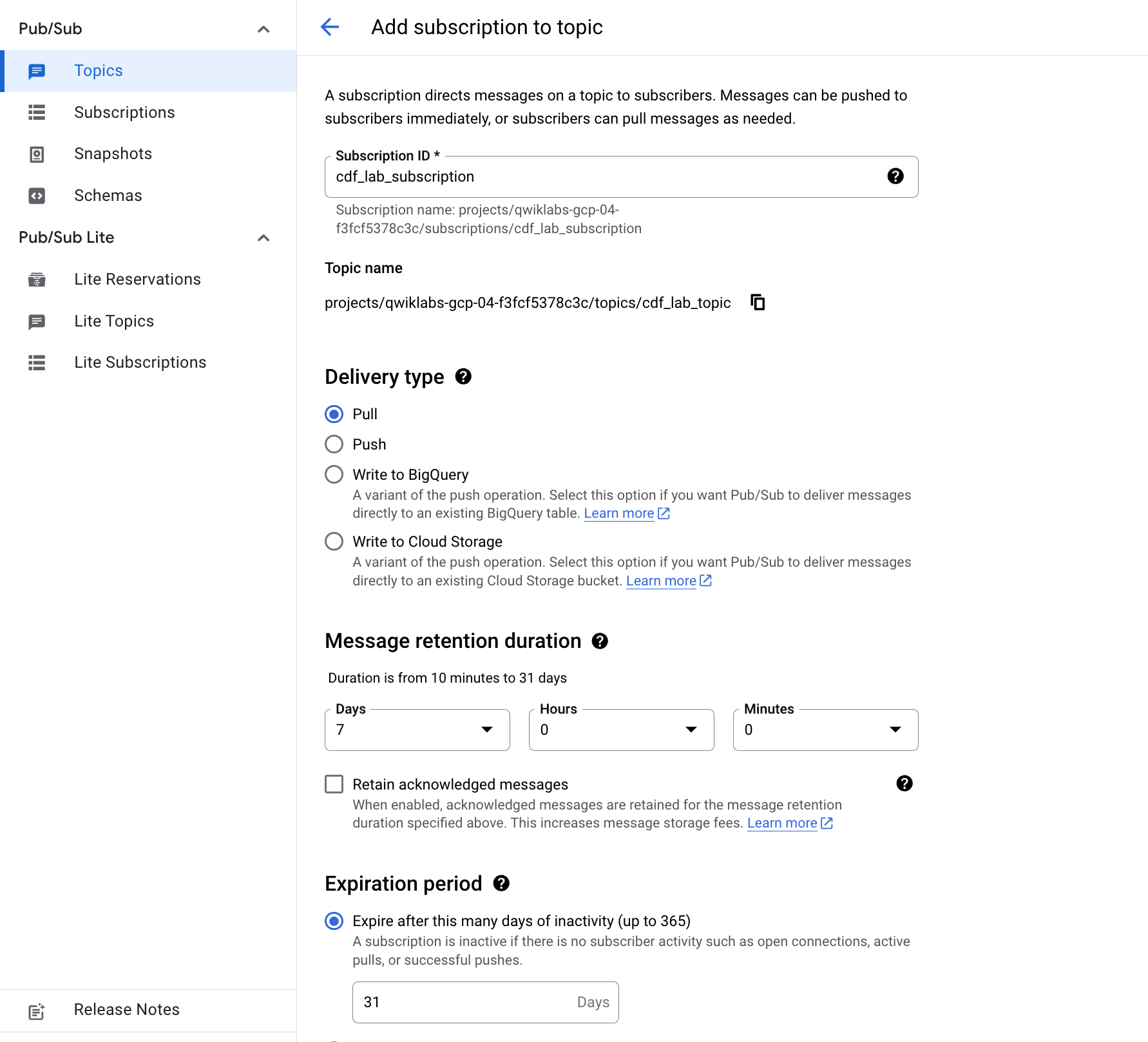
- Geben Sie einen Namen für das Abo ein, z. B.
cdf_lab_subscription, legen Sie den Zustellungstyp auf Pull fest und klicken Sie auf Erstellen.
Klicken Sie auf Fortschritt prüfen.
Pub/Sub-Abo hinzufügen
Aufgabe 6: Erforderliche Berechtigungen für Ihre Cloud Data Fusion-Instanz hinzufügen
- Klicken Sie in der Google Cloud Console im Navigationsmenü auf Alle Produkte ansehen. Klicken Sie im Abschnitt „Analytics“ auf Data Fusion > Instanzen.
Hinweis: Das Erstellen der Instanz kann bis zu 20 Minuten dauern. Bitte warten Sie, bis der Vorgang abgeschlossen ist.
Als Nächstes gewähren Sie dem Dienstkonto, das der Instanz zugeordnet ist, Berechtigungen. Gehen Sie dazu so vor:
-
Rufen Sie in der Google Cloud Console IAM und Verwaltung > IAM auf.
-
Prüfen Sie, ob das Compute Engine-Standarddienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden ist, und kopieren Sie das Dienstkonto in die Zwischenablage.
-
Klicken Sie auf der Seite „IAM-Berechtigungen“ auf Zugriff erlauben.
-
Fügen Sie im Feld „Neue Hauptkonten“ das Dienstkonto ein.
-
Klicken Sie in das Feld Rolle auswählen und geben Sie Cloud Data Fusion API-Dienst-Agent ein. Wählen Sie dann die Rolle aus.
-
Klicken Sie auf + Weitere Rolle hinzufügen.
-
Fügen Sie die Rolle Dataproc-Administrator hinzu.
-
Klicken Sie auf Speichern.
Klicken Sie auf Fortschritt prüfen.
Rolle „Cloud Data Fusion API-Dienst-Agent“ zum Dienstkonto hinzufügen
Dienstkontonutzerin/Dienstkontonutzer die Berechtigung erteilen
-
Klicken Sie in der Console im Navigationsmenü auf IAM & Verwaltung > IAM.
-
Klicken Sie auf das Kästchen Von Google bereitgestellte Rollenzuweisungen einschließen.
-
Suchen Sie in der Liste nach dem von Google verwalteten Cloud Data Fusion-Dienstkonto, das so aussieht: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Kopieren Sie dann den Namen des Dienstkontos in die Zwischenablage.

-
Rufen Sie als Nächstes IAM & Verwaltung > Dienstkonten auf.
-
Klicken Sie auf das Compute Engine-Standardkonto, das so aussieht: {project-number}-compute@developer.gserviceaccount.com, und wählen Sie in der oberen Navigationsleiste den Tab Hauptkonten mit Zugriff aus.
-
Klicken Sie auf den Button Zugriff gewähren.
-
Fügen Sie im Feld Neue Hauptkonten das zuvor kopierte Dienstkonto ein.
-
Wählen Sie im Drop‑down-Menü Rolle die Option Dienstkontonutzer aus.
-
Klicken Sie auf Speichern.
Aufgabe 7: Benutzeroberfläche von Cloud Data Fusion verwenden
Wenn Sie mit Cloud Data Fusion arbeiten, verwenden Sie sowohl die Cloud Console als auch die separate Benutzeroberfläche von Cloud Data Fusion. In der Cloud Console können Sie ein Cloud Console-Projekt erstellen sowie Cloud Data Fusion-Instanzen erstellen und löschen. In der Benutzeroberfläche von Cloud Data Fusion können Sie auf verschiedenen Seiten wie Pipeline Studio oder Wrangler die Funktionen von Cloud Data Fusion nutzen.
So verwenden Sie die Benutzeroberfläche von Cloud Data Fusion:
- Kehren Sie in der Cloud Console zu Data Fusion zurück und klicken Sie neben Ihrer Data Fusion-Instanz auf den Link Instanz anzeigen. Wählen Sie die Anmeldedaten des Labs aus, um sich anzumelden. Wenn Ihnen eine Tour zum Dienst angeboten wird, klicken Sie auf Nein danke. Sie sollten sich jetzt in der Cloud Data Fusion-Benutzeroberfläche befinden.
-
Öffnen Sie im Cloud Data Fusion Control Center über das Navigationsmenü das Menü auf der linken Seite und wählen Sie Pipeline > Studio aus.
-
Wählen Sie links oben im Drop-down-Menü Data Pipeline – Realtime aus.
Aufgabe 8: Echtzeitpipeline erstellen
Bei der Arbeit mit Daten ist es hilfreich, die Rohdaten zu sehen, um sie als Ausgangspunkt für die Transformation zu verwenden. Dazu bereiten Sie die Daten mit Wrangler vor und bereinigen sie. Mit diesem datenorientierten Ansatz können Sie Ihre Transformationen schnell visualisieren. Durch das Feedback in Echtzeit sehen Sie, ob Sie auf dem richtigen Weg sind.
-
Wählen Sie im Abschnitt Transform der Plug-in-Palette die Option Wrangler aus. Der Wrangler-Knoten wird auf dem Canvas angezeigt. Klicken Sie auf den Button „Properties“, um ihn zu öffnen.
-
Klicken Sie im Abschnitt Directives auf den Button WRANGLE.
-
Klicken Sie nach dem Laden im Menü auf der linken Seite auf Upload. Klicken Sie dann auf das Upload-Symbol, um die Datei mit den Beispiel-Tweets hochzuladen, die Sie zuvor auf Ihren Computer heruntergeladen haben.
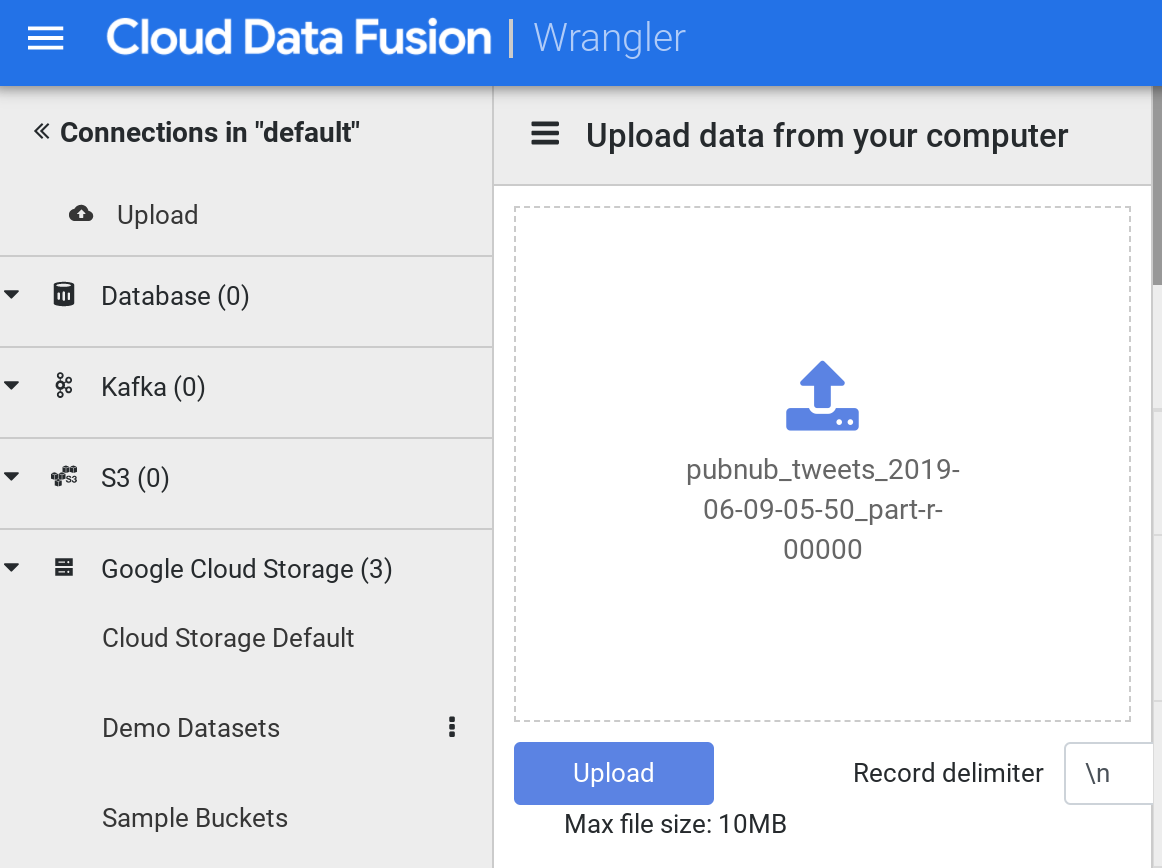
- Die Daten werden in Zeilen-/Spaltenform in den Wrangler-Bildschirm geladen. Das dauert ein paar Minuten.
Hinweis: Betrachten Sie dies als Stichprobe der Ereignisse, die Sie später in Pub/Sub erhalten. Dies entspricht realen Szenarien, in denen Sie während der Entwicklung Ihrer Pipeline in der Regel keinen Zugriff auf Produktionsdaten haben.
Ihr Administrator kann Ihnen jedoch Zugriff auf eine kleine Stichprobe gewähren oder Sie arbeiten mit simulierten Daten, die dem Vertrag einer API entsprechen. In diesem Abschnitt wenden Sie Transformationen iterativ auf diese Stichprobe an und erhalten in jedem Schritt Feedback. Anschließend erfahren Sie, wie Sie die Transformationen auf reale Daten anwenden.
-
Im ersten Schritt werden die JSON-Daten in eine tabellarische Darstellung geparst, die in Zeilen und Spalten aufgeteilt ist. Klicken Sie dazu auf das Drop-down-Symbol in der Spaltenüberschrift der ersten Spalte („body“), wählen Sie den Menüpunkt Parse und dann im Untermenü JSON aus. Legen Sie im Pop-up-Fenster Depth auf 1 fest und klicken Sie auf Apply.
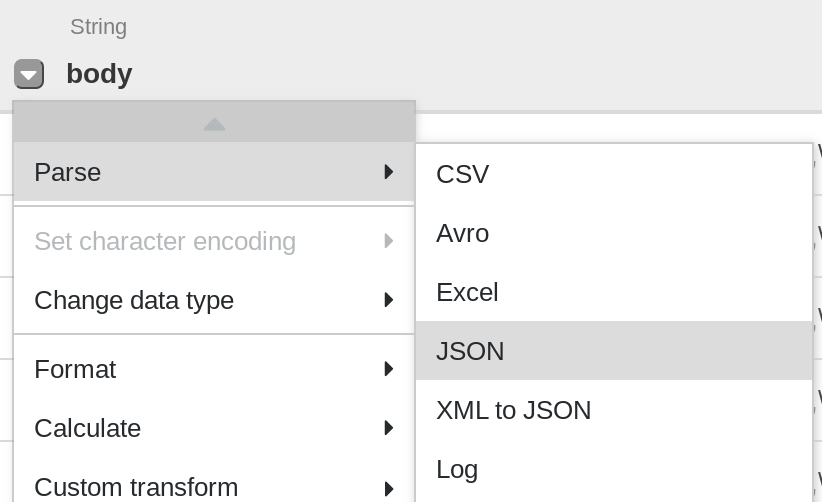
-
Wiederholen Sie den vorherigen Schritt, um eine aussagekräftigere Datenstruktur für die weitere Transformation zu erhalten. Klicken Sie auf das Drop-down-Symbol der Spalte body und wählen Sie Parse > JSON aus. Legen Sie Depth auf 1 fest und klicken Sie auf Apply.
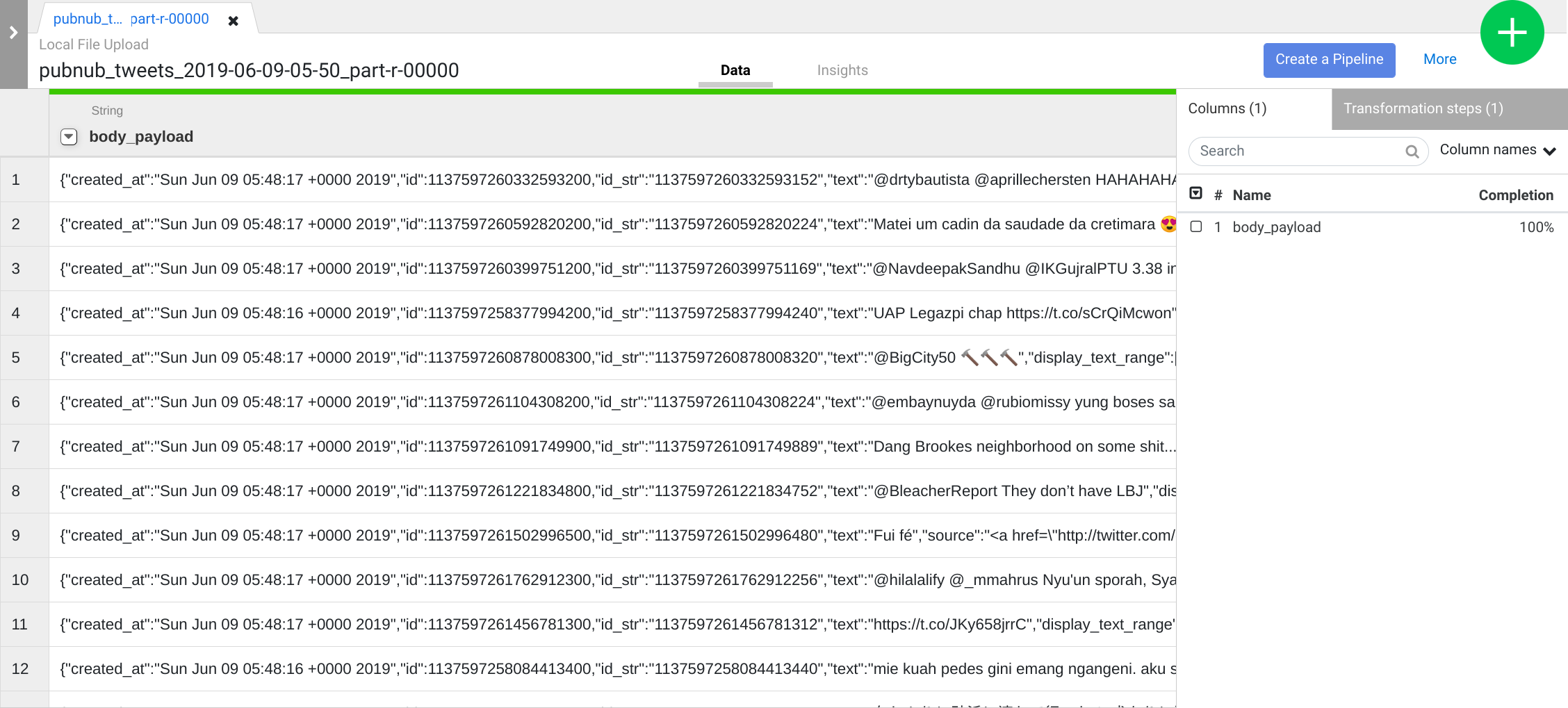
Anstatt die Benutzeroberfläche zu verwenden, können Sie Transformationsschritte auch in das Befehlszeilenfeld für Wrangler-Anweisungen schreiben. Dieses Feld wird im unteren Bereich der Wrangler-Benutzeroberfläche angezeigt (suchen Sie nach der Befehlskonsole mit der grünen Aufforderung $).
Im nächsten Schritt verwenden Sie die Befehlskonsole zum Einfügen einer Reihe von Transformationsschritten.
-
Fügen Sie die folgenden Transformationsschritte hinzu, indem Sie sie kopieren und in das Befehlszeilenfeld für Wrangler-Anweisungen einfügen:
columns-replace s/^body_payload_//g
drop id_str
parse-as-simple-date :created_at EEE MMM dd HH:mm:ss Z yyyy
drop display_text_range
drop truncated
drop in_reply_to_status_id_str
drop in_reply_to_user_id_str
parse-as-json :user 1
drop coordinates
set-type :place string
drop geo,place,contributors,is_quote_status,favorited,retweeted,filter_level,user_id_str,user_url,user_description,user_translator_type,user_protected,user_verified,user_followers_count,user_friends_count,user_statuses_count,user_favourites_count,user_listed_count,user_is_translator,user_contributors_enabled,user_lang,user_geo_enabled,user_time_zone,user_utc_offset,user_created_at,user_profile_background_color,user_profile_background_image_url,user_profile_background_image_url_https,user_profile_background_tile,user_profile_link_color,user_profile_sidebar_border_color,user_profile_sidebar_fill_color,user_profile_text_color,user_profile_use_background_image
drop user_following,user_default_profile_image,user_follow_request_sent,user_notifications,extended_tweet,quoted_status_id,quoted_status_id_str,quoted_status,quoted_status_permalink
drop user_profile_image_url,user_profile_image_url_https,user_profile_banner_url,user_default_profile,extended_entities
fill-null-or-empty :possibly_sensitive 'false'
set-type :possibly_sensitive boolean
drop :entities
drop :user_location
Hinweis: Wenn eine Nachricht wie No data. Try removing some transformation steps. angezeigt wird, entfernen Sie einen der Transformationsschritte, indem Sie auf X klicken. Sobald die Daten angezeigt werden, können Sie fortfahren.
- Klicken Sie rechts oben auf den Button Apply. Klicken Sie dann rechts oben auf das X, um das Attributfeld zu schließen.
Sie befinden sich wieder in Pipeline Studio. Auf dem Canvas wurde ein einzelner Knoten platziert, der die Transformationen darstellt, die Sie gerade in Wrangler definiert haben. Allerdings ist keine Quelle mit dieser Pipeline verbunden, da Sie, wie oben beschrieben, diese Transformationen auf eine repräsentative Stichprobe der Daten auf Ihrem Laptop angewendet haben und nicht auf Daten an ihrem tatsächlichen Produktionsspeicherort.
Im nächsten Schritt legen wir fest, wo sich die Daten tatsächlich befinden sollen.
-
Wählen Sie im Bereich Source der Plug-in-Palette die Option PubSub aus. Der Pub/Sub-Quellknoten wird auf dem Canvas angezeigt. Klicken Sie auf den Button Properties, um ihn zu öffnen.
-
Geben Sie die verschiedenen Attribute der Pub/Sub-Quelle so an:
a. Geben Sie unter Reference name den Wert Twitter_Input_Stream ein.
b. Geben Sie unter Subscription den Namen cdf_lab_subscription ein (das ist der Name des Pub/Sub-Abos, das Sie zuvor erstellt haben).
Hinweis: Die Pub/Sub-Quelle akzeptiert nicht den vollständig qualifizierten Namen des Abos, sondern nur die letzte Komponente nach dem Teil „.../subscriptions/“.
c. Klicken Sie auf Validate, um sicherzustellen, dass keine Fehler vorliegen.
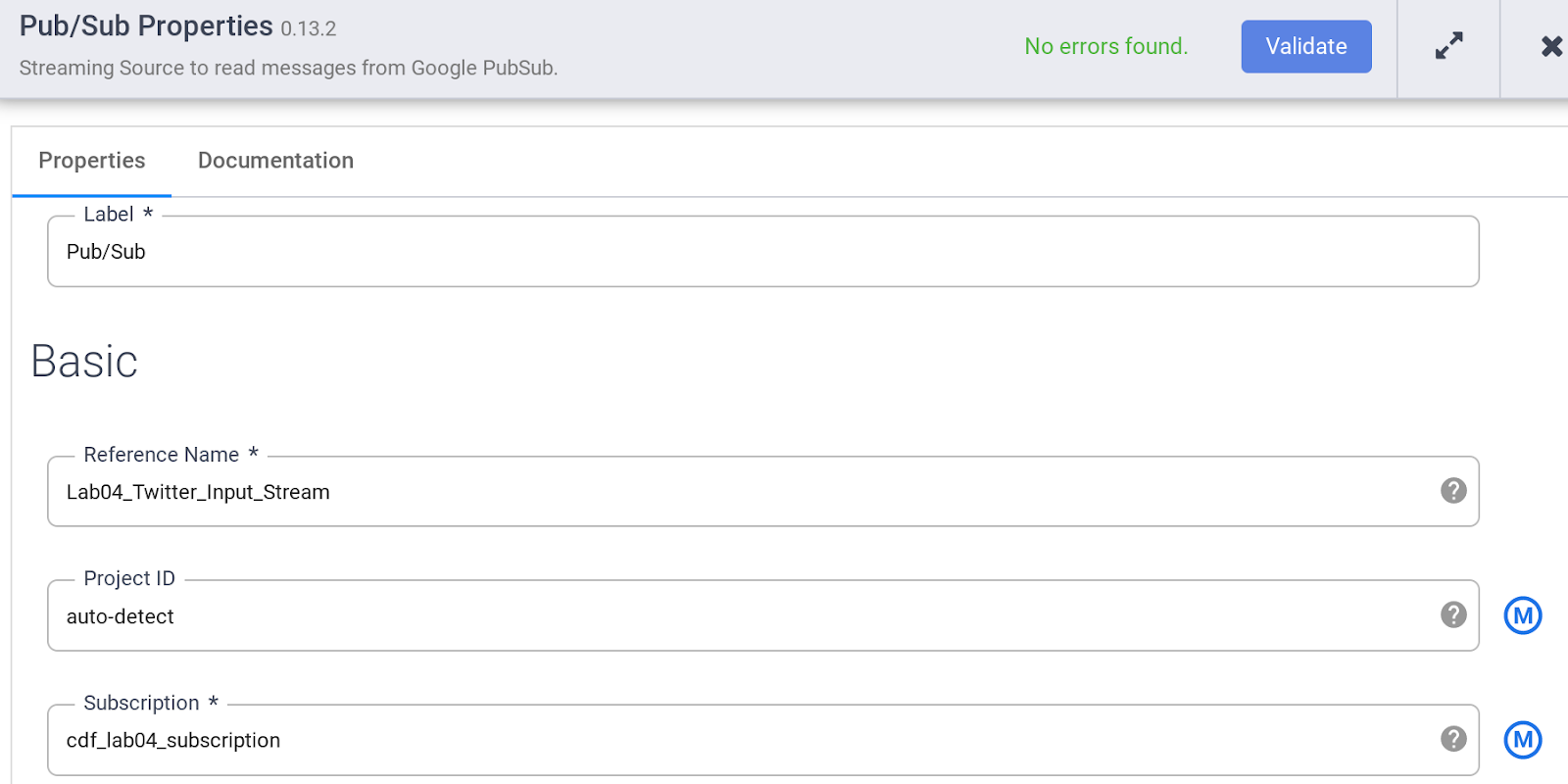
d. Klicken Sie rechts oben auf das X, um das Attributfenster zu schließen.
- Verbinden Sie nun den PubSub-Quellknoten mit dem Wrangler-Knoten, den Sie zuvor hinzugefügt haben.
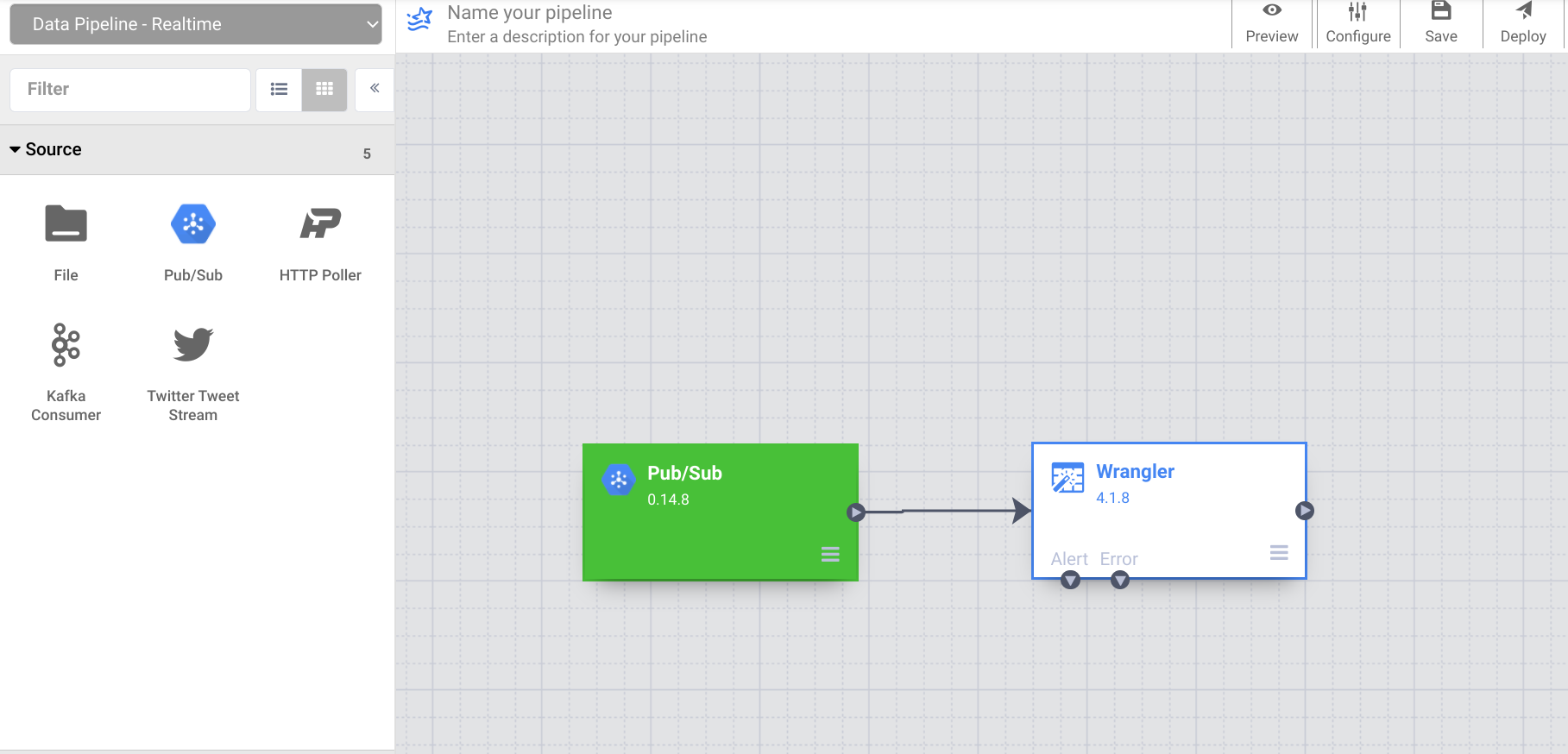
Da Sie zuvor eine Stichprobe der Daten in Wrangler verwendet haben, wurde die Quellspalte in Wrangler als „body“ angezeigt. Die PubSub-Quelle gibt sie jedoch in ein Feld mit dem Namen „message“ aus. Im nächsten Schritt beheben Sie diese Diskrepanz.
- Öffnen Sie Properties für den Wrangler-Knoten und fügen Sie die folgende Anweisung über den vorhandenen Transformationsschritten ein:
keep :message
set-charset :message 'utf-8'
rename :message :body
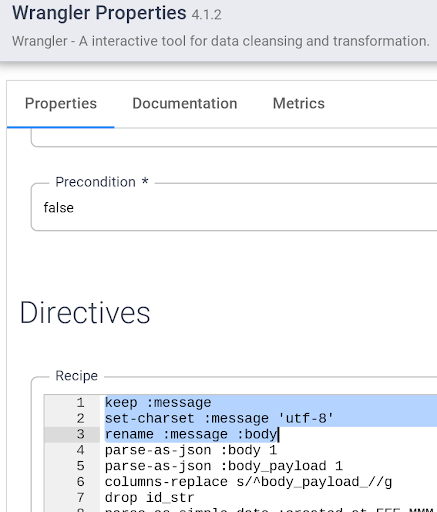
Klicken Sie rechts oben auf das X, um das Attributfenster zu schließen.
-
Nachdem Sie eine Quelle und eine Transformation mit der Pipeline verbunden haben, können Sie sie durch Hinzufügen einer Senke vervollständigen. Wählen Sie im Bereich Sink der linken Seitenleiste die Option BigQuery aus. Auf dem Canvas wird ein BigQuery-Senkenknoten angezeigt.
-
Verbinden Sie den Wrangler-Knoten mit dem BigQuery-Knoten, indem Sie den Pfeil vom Wrangler-Knoten zum BigQuery-Knoten ziehen. Als Nächstes konfigurieren Sie die Attribute des BigQuery-Knotens.

-
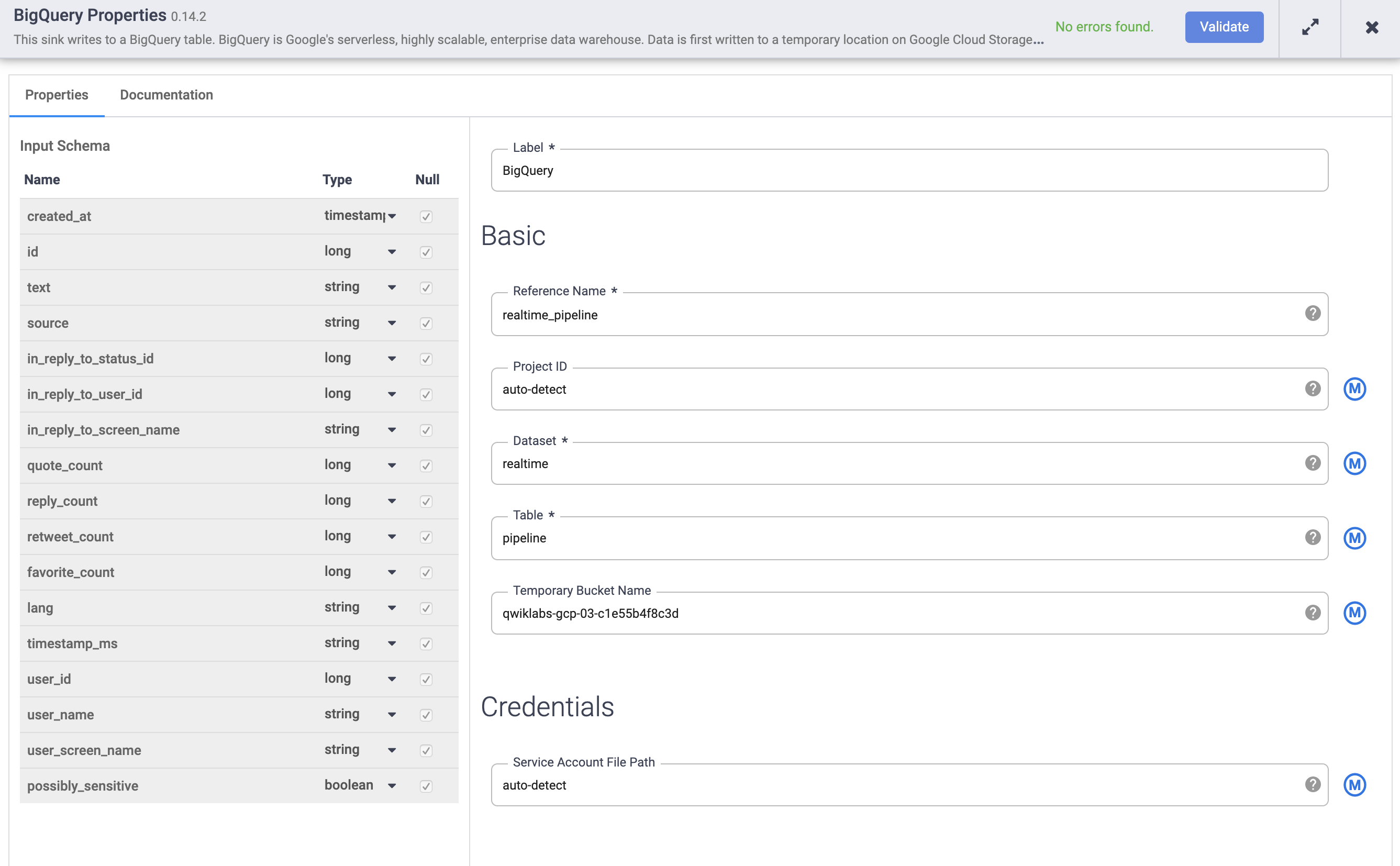
Bewegen Sie den Mauszeiger auf den Knoten BigQuery und klicken Sie auf Properties.
a. Geben Sie unter Reference name den Wert realtime_pipeline ein.
b. Geben Sie unter Dataset den Wert realtime ein.
c. Geben Sie unter Table den Wert tweets ein.
d. Klicken Sie auf Validate, um sicherzustellen, dass keine Fehler vorliegen.
-
Klicken Sie rechts oben auf das X, um das Attributfenster zu schließen.
-
Klicken Sie auf Name your pipeline, geben Sie Realtime_Pipeline als Namen ein und klicken Sie auf Save.
-
Klicken Sie auf das Symbol Deploy und starten Sie dann die Pipeline.
-
Klicken Sie nach der Bereitstellung auf Run. Warten Sie, bis sich der Status der Pipeline in Running ändert. Das dauert ein paar Minuten.
Aufgabe 9: Nachrichten in Cloud Pub/Sub senden
Senden Sie Ereignisse, indem Sie sie mithilfe der Dataflow-Vorlage in einem Bulk-Vorgang in das Abo laden.
Sie erstellen jetzt einen Dataflow-Job basierend auf einer Vorlage, um mehrere Nachrichten aus der Datei „tweets“ zu verarbeiten und sie in dem zuvor erstellten Pub/Sub-Thema zu veröffentlichen. Verwenden Sie die Vorlage Text Files on Cloud Storage to Pub/Sub unter Process Data Continuously (Stream) auf der Seite zum Erstellen eines Dataflow-Jobs.
-
Klicken Sie in der Cloud Console im Navigationsmenü auf Alle Produkte ansehen und wählen Sie unter „Analytics“ die Option Dataflow aus.
-
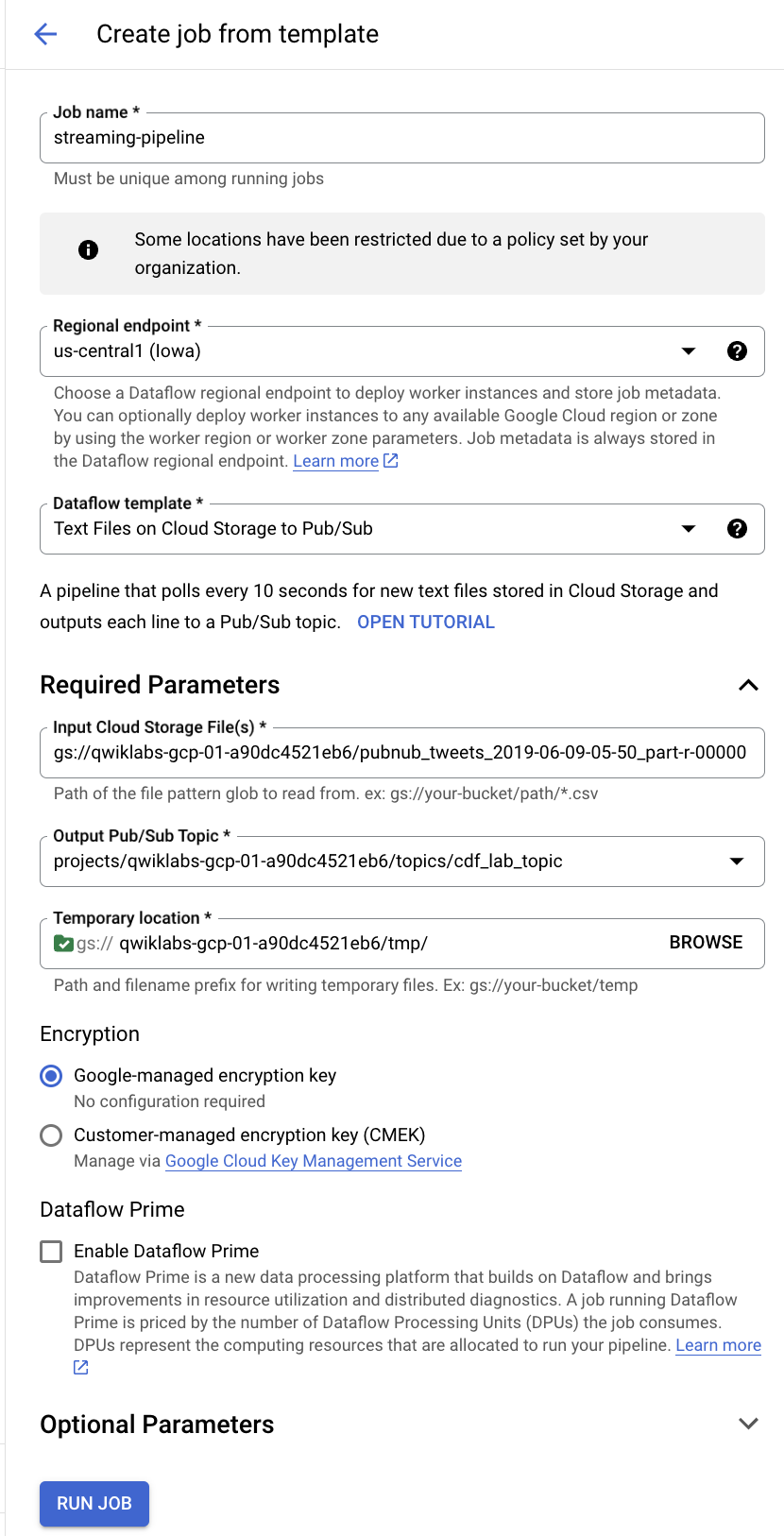
Klicken Sie in der oberen Menüleiste auf JOB AUS VORLAGE ERSTELLEN.
-
Geben Sie streaming-pipeline als Jobnamen für Ihren Cloud Dataflow-Job ein.
-
Wählen Sie unter Dataflow-Vorlage die Vorlage Text Files on Cloud Storage to Pub/Sub aus.
-
Geben Sie unter Cloud Storage-Datei(en) eingeben gs://<YOUR-BUCKET-NAME>/<FILE-NAME> ein. Ersetzen Sie <YOUR-BUCKET-NAME> durch den Namen Ihres Buckets und <FILE-NAME> durch den Namen der Datei, die Sie zuvor auf Ihren Computer heruntergeladen haben.
Beispiel: gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
- Geben Sie unter Pub/Sub-Thema für Ausgabe
projects/<PROJECT-ID>/topics/cdf_lab_topic ein.
Ersetzen Sie PROJECT-ID durch Ihre tatsächliche Projekt-ID.
- Geben Sie unter Temporärer Speicherort
<YOUR-BUCKET-NAME>/tmp/ ein.
Ersetzen Sie dabei <YOUR-BUCKET-NAME> durch den Namen Ihres Buckets.
-
Klicken Sie auf Job ausführen.
-
Führen Sie den Dataflow-Job aus und warten Sie ein paar Minuten. Sie können Nachrichten im Pub/Sub-Abo sehen und dann beobachten, wie sie über eine CDF-Pipeline in Echtzeit verarbeitet werden.
Klicken Sie auf Fortschritt prüfen.
Laufzeitpipeline erstellen und ausführen
Aufgabe 10: Pipelinemesswerte ansehen
Sobald Ereignisse in das Pub/Sub-Thema geladen wurden, sollten Sie sehen können, wie sie von der Pipeline verarbeitet werden. Achten Sie darauf, wie die Messwerte für jeden Knoten aktualisiert werden.
Glückwunsch!
In diesem Lab haben Sie gelernt, wie Sie in Data Fusion eine Echtzeitpipeline einrichten, die eingehende Streamingnachrichten aus Cloud Pub/Sub liest, die Daten verarbeitet und sie in BigQuery schreibt.
Anleitung zuletzt am 6. Februar 2025 aktualisiert
Lab zuletzt am 6. Februar 2025 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.







