





准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Load the data
/ 25
Ingestion into BigQuery
/ 50
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Load the data
/ 25
Ingestion into BigQuery
/ 50
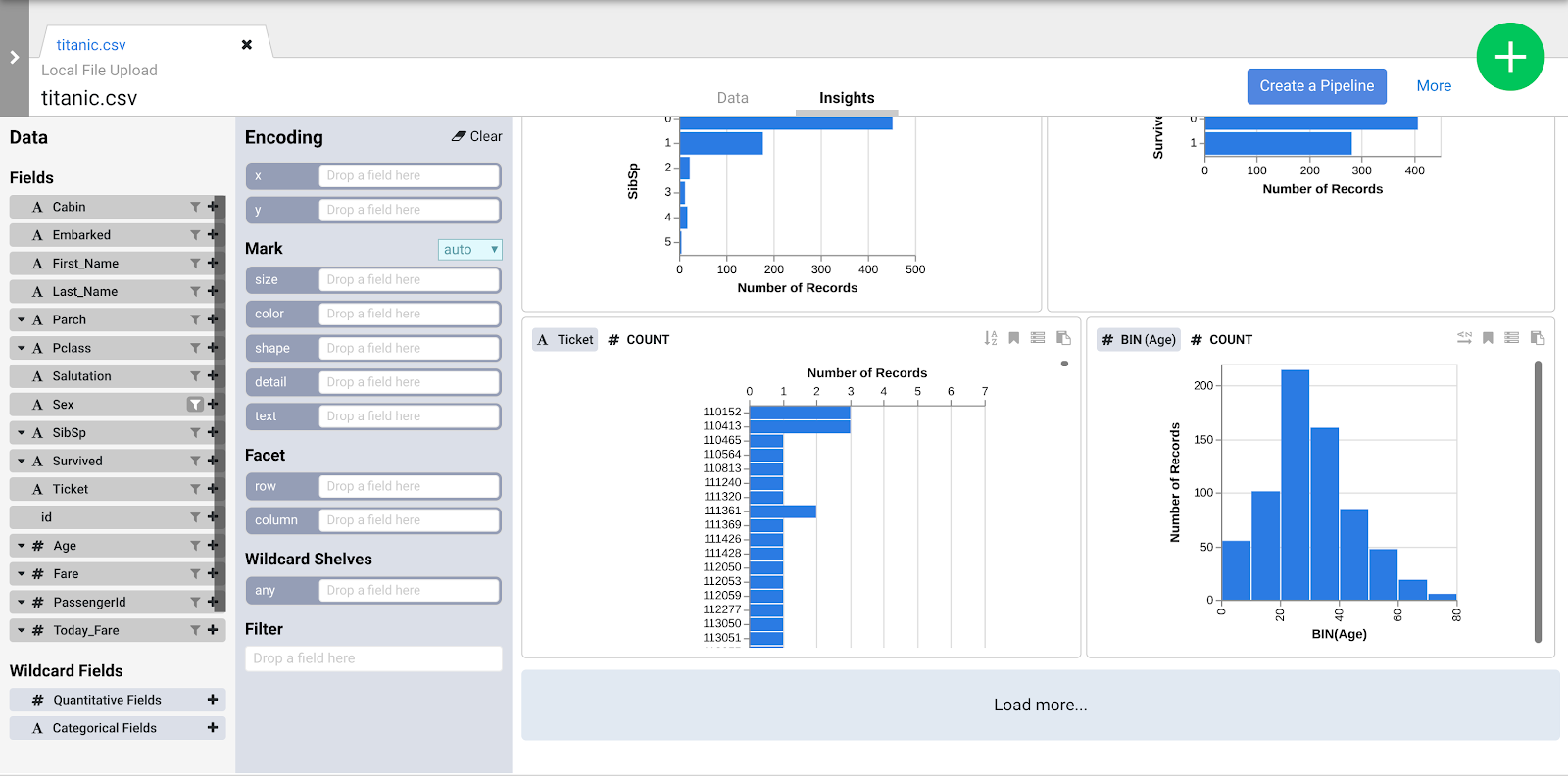
数据集成的核心在于数据。在处理数据时,如果能直观地查看原始数据的样貌会非常方便,这能为您后续的转换工作提供基础。借助 Wrangler,您可以采用数据优先的方法来处理数据集成工作流。
对于 ETL(提取、转换、加载)应用,最常见的数据来源通常是以逗号分隔值 (CSV) 格式存储在文本文件中的数据,因为许多数据库系统都以这种方式导出和导入数据。在本实验中,您将使用 CSV 文件,但同样的技术也适用于数据库源以及 Cloud Data Fusion 中提供的任何其他数据源。
在本实验中,您将学习如何执行以下任务:
在本实验的大部分时间里,您将使用由 Wrangler 插件调用的“Wrangler 转换步骤”,以便将所有转换操作封装在一个地方,并将转换任务分组为易于管理的模块。这种数据为先的方法可让您快速直观地了解转换情况。
对于每个实验,您都会免费获得一个新的 Google Cloud 项目及一组资源,它们都有固定的使用时限。
使用无痕式窗口登录 Google Skills。
留意实验的访问时限(例如 02:00:00)并确保能在此时限内完成实验。
系统不提供暂停功能。如有需要,您可以重新开始实验,不过必须从头开始。
准备就绪时,点击开始实验。
请记好您的实验凭据(用户名和密码)。您需要使用这组凭据来登录 Google Cloud 控制台。
点击打开 Google 控制台。
点击使用其他账号,然后将此实验的凭据复制并粘贴到相应提示框中。
如果您使用其他凭据,将会收到错误消息或产生费用。
接受条款并跳过恢复资源页面。
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

Cloud Shell 是一种包含开发工具的虚拟机。它提供了一个 5 GB 的永久性主目录,并且在 Google Cloud 上运行。Cloud Shell 可让您通过命令行访问 Google Cloud 资源。gcloud 是 Google Cloud 的命令行工具。它会预先安装在 Cloud Shell 上,且支持 Tab 键自动补全功能。
在 Google Cloud Console 的导航窗格中,点击激活 Cloud Shell (
点击继续。
预配和连接到环境需要一些时间。若连接成功,也就表明您已通过身份验证,且相关项目的 ID 会被设为您的 PROJECT_ID。例如:
列出有效的帐号名称:
(输出)
(输出示例)
列出项目 ID:
(输出)
(输出示例)
在开始在 Google Cloud 中工作之前,您必须确保您的项目在 Identity and Access Management (IAM) 中拥有正确的权限。
在 Google Cloud 控制台的导航菜单 (
确认默认计算服务账号 {project-number}-compute@developer.gserviceaccount.com 已存在且被授予了 editor 角色。账号前缀是项目编号,您可以在导航菜单 > Cloud 概览中找到此编号。
如果该账号在 IAM 中不存在或不具有 editor 角色,请按照以下步骤向其分配所需的角色。
在 Google Cloud 控制台的导航菜单中,点击 Cloud 概览。
从项目信息卡片中复制项目编号。
在导航菜单中,点击 IAM 和管理 > IAM。
在 IAM 页面顶部,点击添加。
在新的主账号字段中,输入:
将 {project-number} 替换为您的项目编号。
在选择角色部分,依次选择基本(或“项目”)> Editor。
点击保存。
在 Google Cloud 控制台标题栏的搜索字段中,输入 Data Fusion,点击搜索,然后点击 Data Fusion。
点击 Data Fusion 旁边的图钉图标。
接下来,您将按照以下步骤向与实例关联的服务账号授予权限。
在 Google Cloud 控制台中,找到 IAM 和管理 > IAM。
确认 Compute Engine 默认服务账号 {project-number}-compute@developer.gserviceaccount.com 已存在,并将服务账号复制到剪贴板中。
在“IAM 权限”页面上,点击 +授予访问权限。
在“新的主账号”字段中,粘贴刚刚复制的服务账号。
点击进入选择角色字段,输入“Cloud Data Fusion API Service Agent”,然后选择该角色。
点击添加其他角色
添加 Managed Service for Spark Administrator 角色。
点击保存。
点击“检查我的进度”以验证是否完成了以下目标:
在控制台中,点击导航菜单下的 IAM 和管理 > IAM。
选中包括 Google 提供的角色授权复选框。
在列表中向下滚动,找到由 Google 管理的 Cloud Data Fusion 服务账号(其形式类似于 service-{项目编号}@gcp-sa-datafusion.iam.gserviceaccount.com),随后将该服务账号名称复制到剪贴板。
然后前往 IAM 和管理 > 服务账号。
点击默认 Compute Engine 账号(其形式类似于 {项目编号}-compute@developer.gserviceaccount.com),然后选择顶部导航栏中的具有访问权限的主账号标签页。
点击授予访问权限按钮。
将您先前复制的服务账号粘贴到新的主账号字段中。
在角色下拉菜单中,选择 Service Account User。
点击保存。
接下来,您将在项目中创建一个 Cloud Storage 存储桶,以便加载一些用于整理的示例数据。Cloud Data Fusion 稍后将从该存储桶中读取数据
您的项目 ID 即为新建存储桶的名称。
点击“检查我的进度”以验证是否完成了以下目标:
现在,您可以继续进行下一步了。
在 Cloud Data Fusion 界面中,您可以通过各种页面(例如 Pipeline Studio 或 Wrangler)来使用 Cloud Data Fusion 功能。
若要浏览 Cloud Data Fusion 界面,请按以下步骤操作:
Cloud Data Fusion 网页界面自带导航面板(位于左侧),可用于进入所需页面。
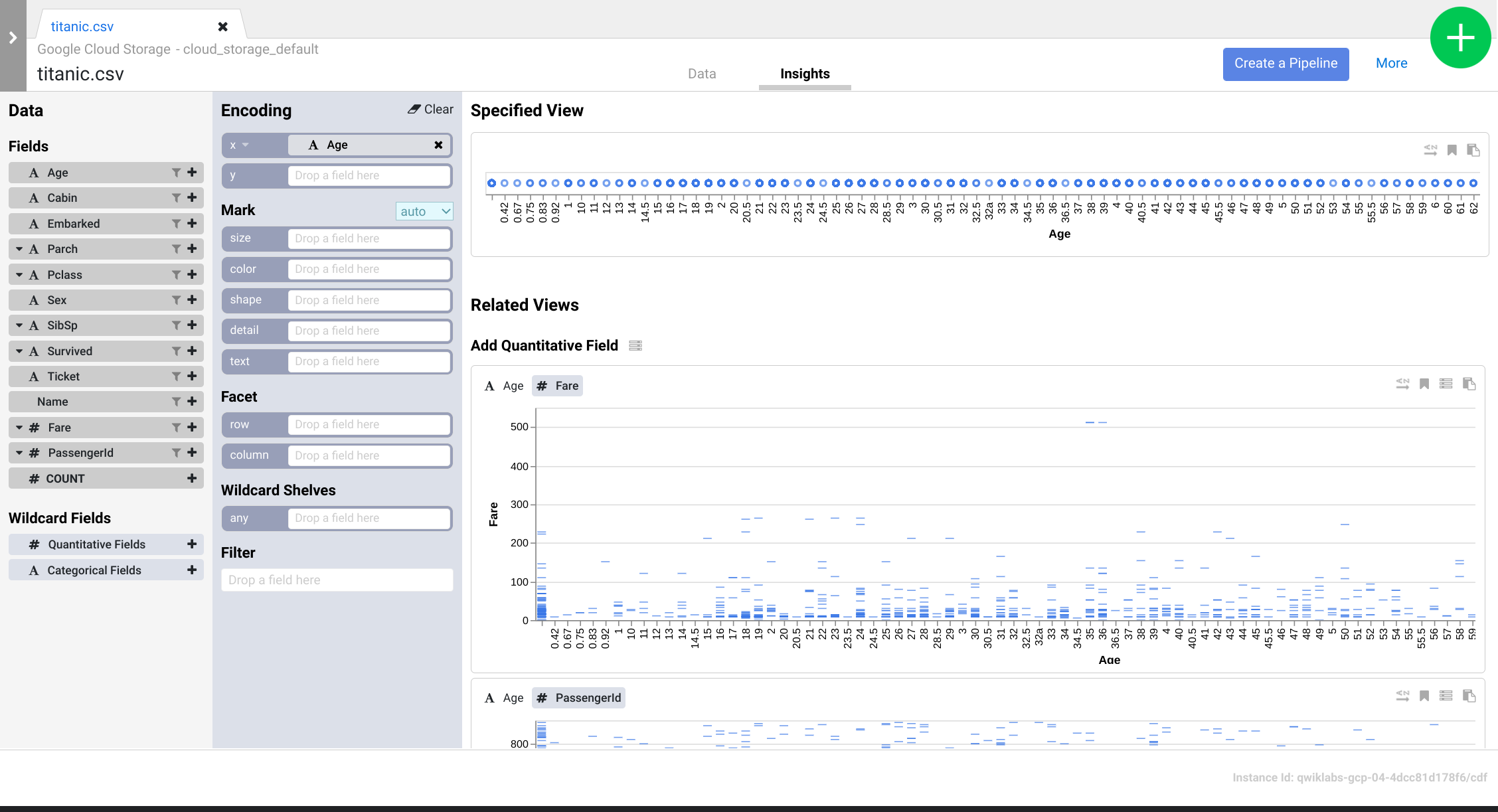
Wrangler 是一款交互式直观显示工具。借助此工具,您可以先查看小型数据子集的转换效果,然后再针对整个数据集调度并行处理的大型作业。
Wrangler 加载后,左侧会显示一个面板,其中有预先配置的数据连接,包括 Cloud Storage 连接。
在 GCS 中,选择 Cloud Storage Default(Cloud Storage 默认存储桶)。
点击与您的项目 ID 对应的存储桶。
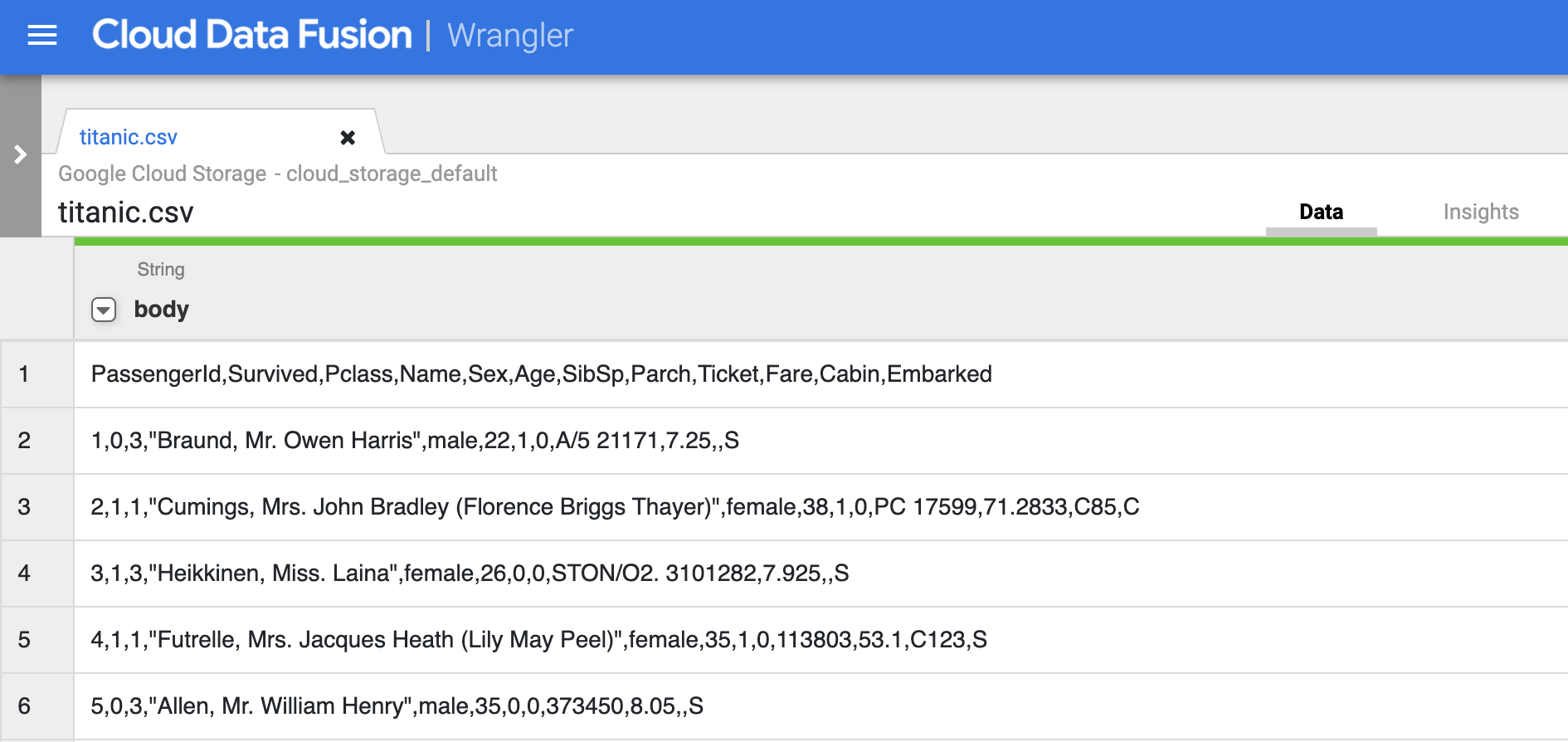
点击 titanic.csv。
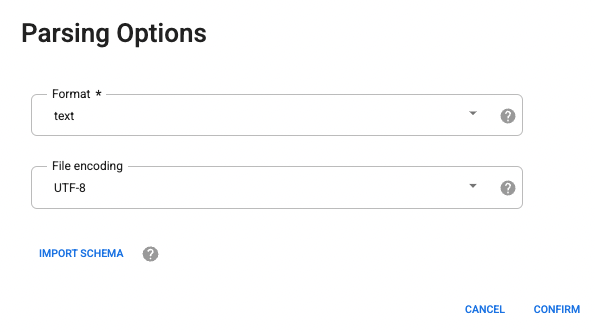
在解析选项中,从下拉菜单中选择文本格式。
在原始数据中,我们可以看到第一行由列标题组成,因此您需要在显示的解析为 CSV 对话框中选择将第一行设置为标题选项,然后点击应用。
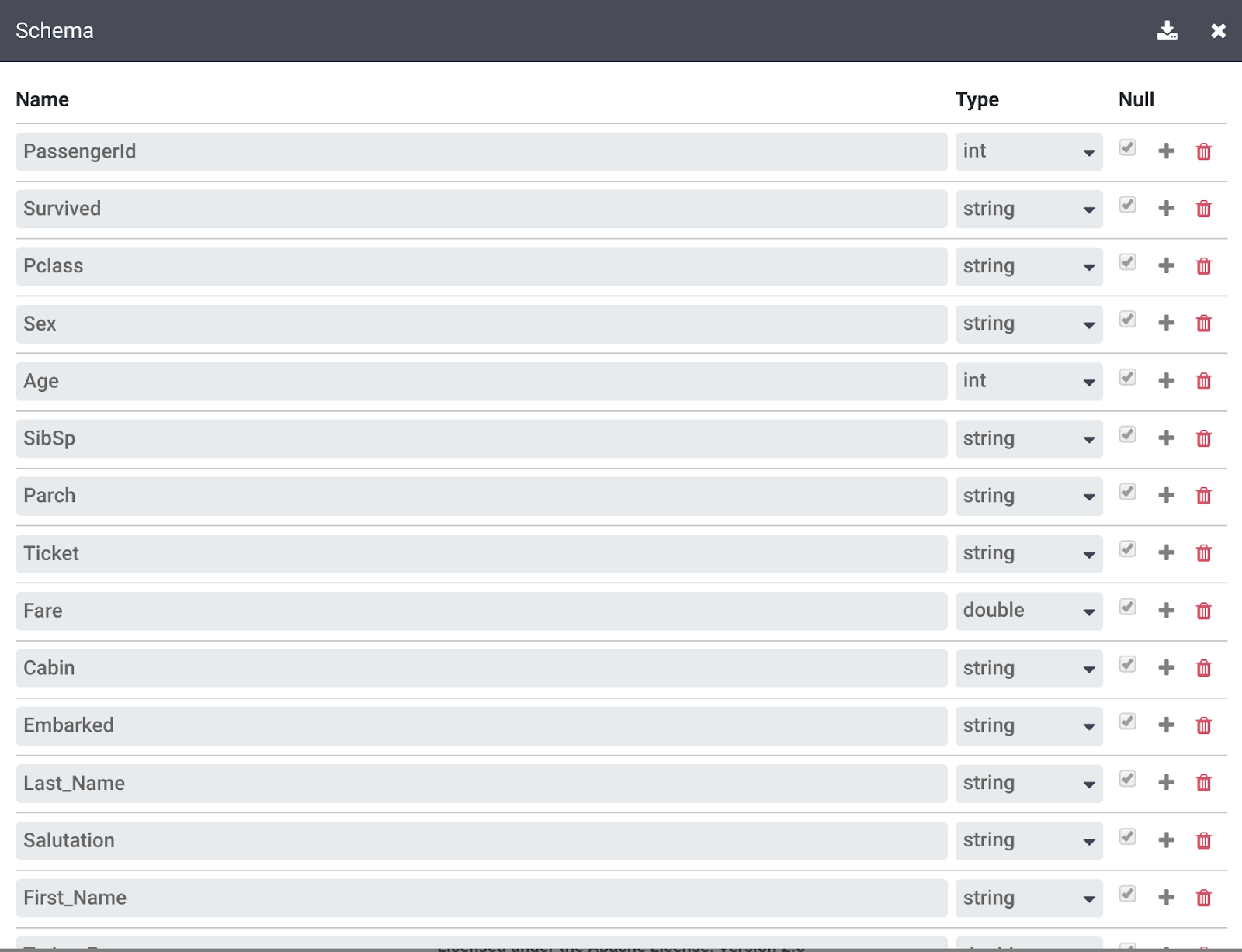
至此,原始数据已解析完毕,您可以在 body 列的右侧看到此操作生成的列。
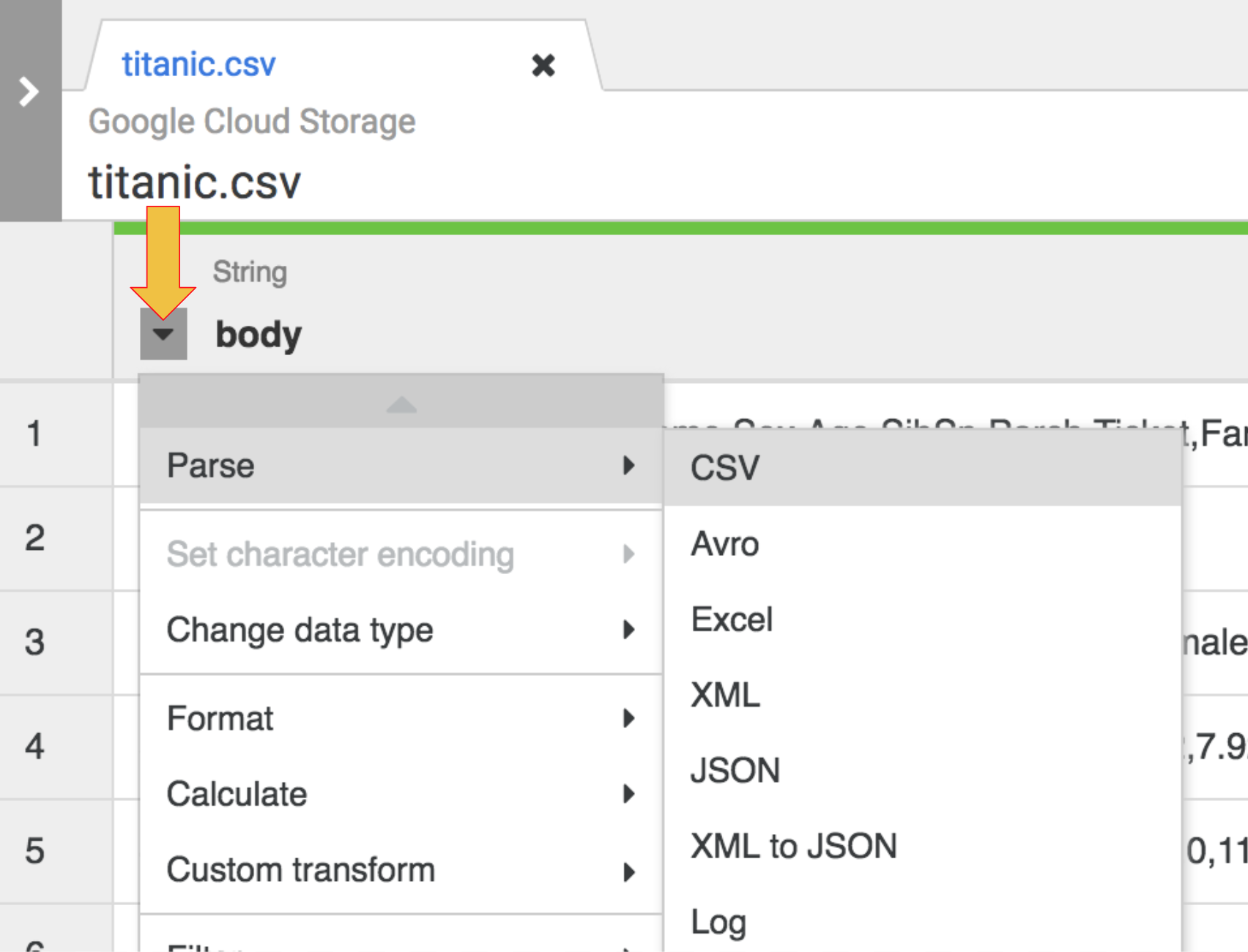
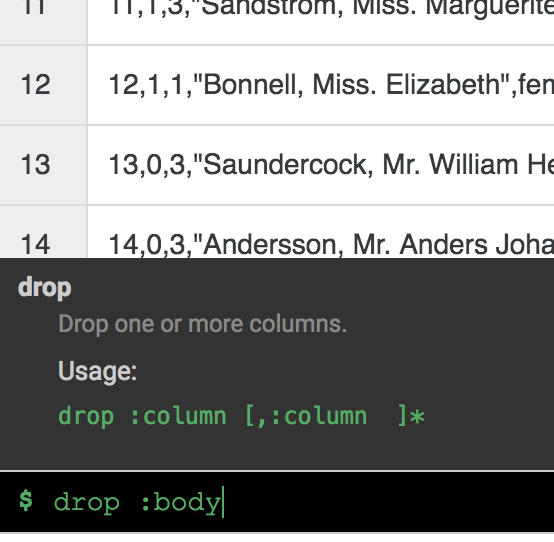
您不再需要 body 列,因此请点击 body 列标题旁的下拉图标,并点击删除列菜单项将其删除。
在本实验的后面部分,您将使用 CLI 添加更多转换步骤。
在对数据集应用转换步骤时,这些转换会影响抽样数据,并提供可通过 Insights 浏览器探索的视觉提示。
Pipeline Studio 打开后,将光标指向 Wrangler 节点并点击属性
按照指令查看您之前添加的指令 recipe。在下一部分中,您将使用 CLI 添加更多转换步骤。
在本部分中,您将继续在 Wrangler 界面中操作,探索 CSV 数据集并通过 CLI 应用转换。
在 Wrangler 节点“属性”框的指令部分下,点击 Wrangle 按钮。系统会返回 Wrangler 界面。
点击 Wrangler 界面最右侧的转换步骤,以显示指令。验证您目前是否有两个转换步骤。
接下来,您将使用 CLI 添加更多转换步骤,并了解这些步骤如何修改数据。CLI 是屏幕底部的黑条(带有绿色 $ 提示)。
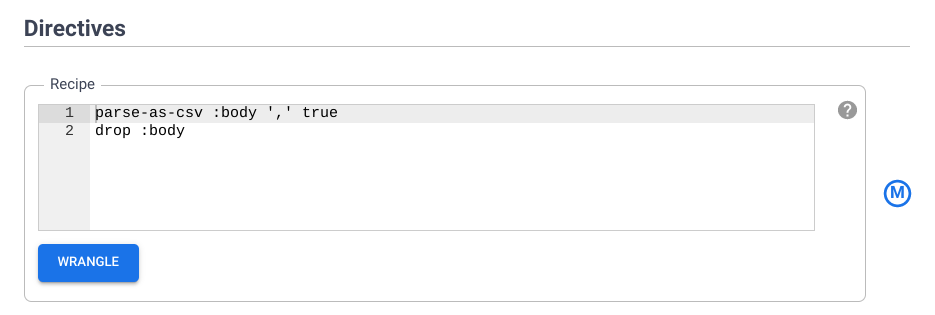
下面说明了这些指令对数据的作用。切勿在 CLI 中再次输入这些指令,因为您刚刚已经输入过了。
a. fill-null-or-empty :Cabin 'none' 会修复 Cabin 列,使其 100% 完整
b. send-to-error empty(Age) 会修复 Age 列,确保没有空单元格
c. parse-as-csv :Name ',' false 会将 Name 列拆分为两个单独的列,分别包含名字和姓氏
d. rename Name_1 Last_Name 和 rename Name_2 First_Name 会将新创建的列 Name_1 和 Name_2 重命名为 Last_Name 和 First_Name
e. drop Name 会移除不再需要的 Name 列
f. set-type :PassengerId integer 会将 PassengerId 列转换为整数
g. 这些指令会从 First_Name 列中提取称谓,删除冗余列,并相应地重命名新建的列:
h. send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125) 指令会对 Age 列执行数据质量检查,而 set-type :Age integer 指令则会将其设置为整数列
i. set-type :Fare double 会将 Fare 列转换为双精度浮点数,以便对列值执行一些算术运算
j. set-column Today_Fare (Fare * 23.4058)+1 会将 Fare 列乘以自 1912 年以来的美元通货膨胀率,以获得调整后的美元价值
k. generate-uuid id 会创建一个身份列,用于唯一标识每条记录
l. mask-shuffle First_Name 会遮盖 Last_Name 列,以对用户(即个人身份信息)进行去标识化
点击转换步骤右上方的更多链接,然后点击查看架构,检查转换生成的架构,并点击下载图标将其下载到您的计算机。
点击 X 关闭“架构”页面。
您可以点击转换步骤下方的下载图标,将指令 recipe 下载到您的计算机,以保留转换步骤副本供日后使用。
点击右上角的应用按钮,确保所有新输入的转换步骤都添加到 Wrangler 节点的配置中。然后,系统会跳转至 Wrangler 节点的属性框。
点击 X 将其关闭。您将返回 Pipeline Studio。
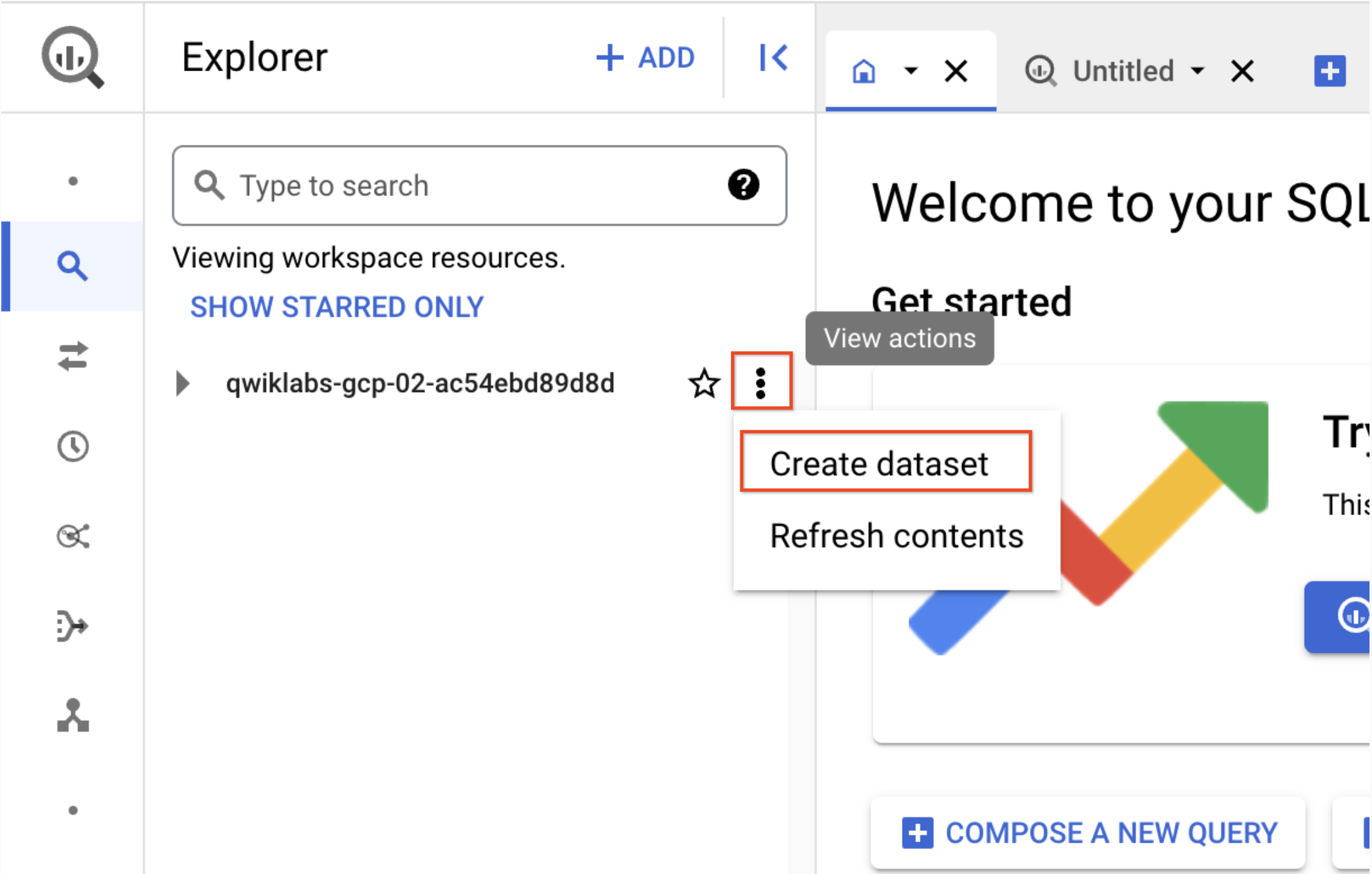
创建一个数据集,以便将数据注入 BigQuery。
在新标签页中,打开 Google Cloud 控制台中的 BigQuery,或右键点击 Google Cloud 控制台标签页并选择复制,然后使用导航菜单选择 BigQuery。如果出现提示,请点击完成。
在“探索器”窗格中,点击项目 ID(以 qwiklabs 开头)旁边的查看操作图标,然后选择创建数据集。
a. 数据集 ID:demo_cdf
b. 点击创建数据集。记下该名称,以便稍后在本实验中使用。
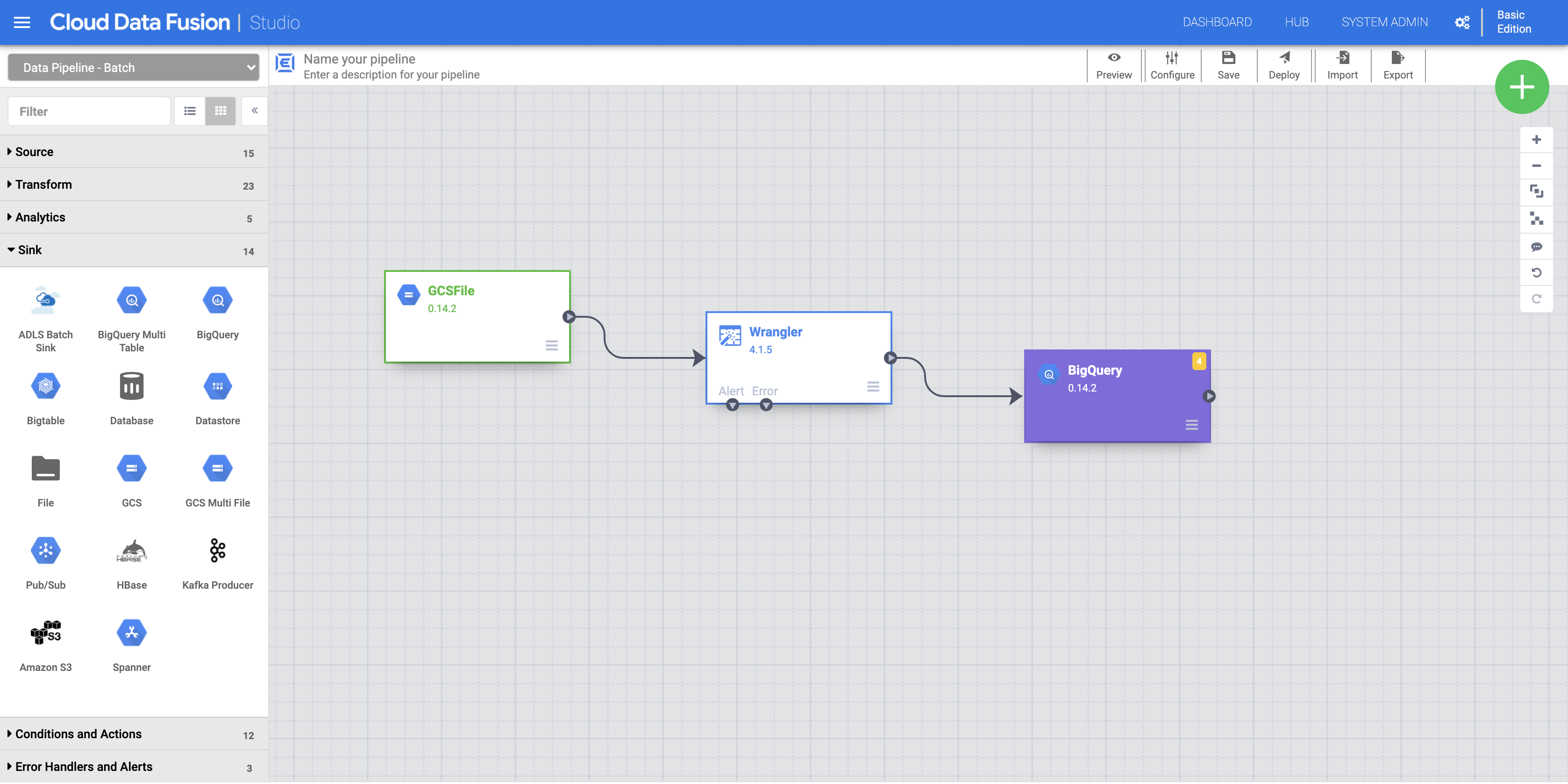
a. 要将 BigQuery 接收器添加到流水线,请前往左侧面板上的接收器部分,然后点击 BigQuery 图标,将其放置在画布上。
b. 将 BigQuery 接收器放置在画布上后,再将 Wrangler 节点与 BigQuery 节点连接起来。具体做法是:按照图示,将箭头从 Wrangler 节点拖至 BigQuery 节点进行连接。
c. 将鼠标悬停在 BigQuery 节点上,点击属性,然后输入以下配置设置:
| 字段 | 值 |
|---|---|
| 参考名称 | DemoSink |
| 数据集项目 ID | 您的项目 ID |
| 数据集 |
demo_cdf(您在上一步中创建的数据集) |
| 表 | 输入适当的名称(例如 titanic) |
系统会自动创建该表。
d. 点击验证按钮,检查所有设置是否正确。
e. 点击 X 将其关闭。您将返回到 Pipeline Studio。
a. 为流水线命名(例如 DemoBQ)
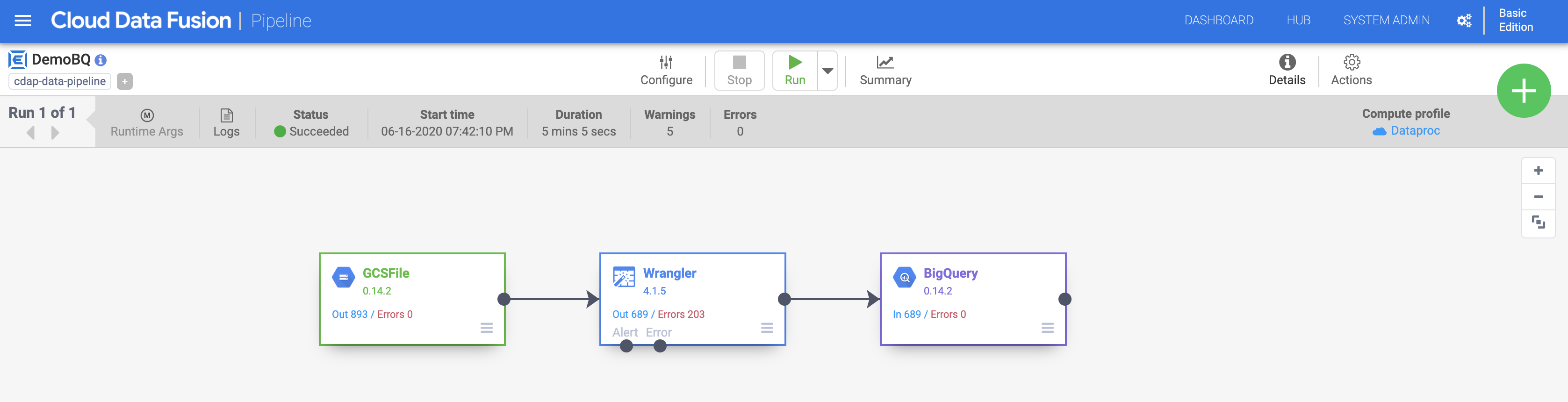
b. 点击保存,然后点击右上角的部署以部署流水线。
c. 点击运行以开始执行流水线。您可以点击摘要图标查看一些统计信息。
执行完成后,状态会变为成功。返回 BigQuery 控制台,查询运行结果。
点击“检查我的进度”以验证是否完成了以下目标:
在本实验中,您探索了 Wrangler 界面。您了解了如何通过菜单以及使用 CLI 添加转换步骤(指令)。借助 Wrangler,您能够以迭代方式对数据应用许多强大的转换,您也可以通过 Wrangler 界面查看这些转换在部署和运行流水线之前如何影响数据架构。
完成实验后,请点击结束实验。Google Skills 会移除您使用过的资源并为您清理账号。
系统会提示您为实验体验评分。请选择相应的评分星级,输入评论,然后点击提交。
星级的含义如下:
如果您不想提供反馈,可以关闭该对话框。
如果要留言反馈、提出建议或做出更正,请使用支持标签页。
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名称和产品名称可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验
完成此快速步骤即可开始实验。