Ringkasan
Integrasi data sepenuhnya berfokus pada data Anda. Saat menangani data, sangatlah membantu jika Anda dapat melihat tampilan data mentah, sehingga dapat digunakan sebagai titik awal untuk melakukan transformasi. Dengan Wrangler, Anda dapat menerapkan pendekatan yang mengutamakan data dalam alur kerja integrasi data Anda.
Sumber data yang paling umum untuk aplikasi ETL (Extract-Transform-Load) biasanya adalah data yang disimpan dalam file teks berformat CSV (comma-separated value), karena banyak sistem basis data yang mengekspor dan mengimpor data dengan mode ini. Untuk keperluan lab ini, Anda akan menggunakan file CSV. Namun, teknik yang sama dapat diterapkan pada sumber database dan sumber data lainnya yang tersedia di Cloud Data Fusion.
Tujuan
Di lab ini, Anda akan mempelajari cara melakukan tugas-tugas berikut:
- Membuat pipeline untuk menyerap data dari file CSV.
- Menggunakan Wrangler untuk menerapkan transformasi melalui antarmuka tunjuk dan klik serta CLI.
Di sebagian besar lab ini, Anda akan bekerja dengan Wrangler Transformation Steps yang digunakan oleh plugin Wrangler. Dengan demikian, transformasi Anda akan terenkapsulasi di satu tempat dan memudahkan Anda untuk mengelompokkan tugas-tugas transformasi ke dalam block yang mudah dikelola. Melalui pendekatan yang mengutamakan data ini, Anda dapat memvisualisasikan transformasi secara cepat.
Penyiapan
Untuk setiap lab, Anda akan memperoleh project Google Cloud baru serta serangkaian resource selama jangka waktu tertentu, tanpa biaya.
-
Login ke Google Skills menggunakan jendela samaran.
-
Perhatikan waktu akses lab (misalnya, 02:00:00), dan pastikan Anda dapat menyelesaikannya dalam waktu tersebut.
Tidak ada fitur jeda. Bila perlu, Anda dapat memulai ulang lab, tetapi Anda harus memulai dari awal.
-
Jika sudah siap, klik Start lab.
Catatan: Setelah Anda mengklik Start lab, perlu waktu sekitar 15 - 20 menit agar resource yang diperlukan disediakan dan instance Data Fusion dibuat.
Selama waktu ini, Anda dapat membaca langkah-langkah di bawah untuk mengetahui sasaran lab.
Jika Anda melihat kredensial lab (Nama pengguna dan Sandi) di panel kiri, artinya instance telah dibuat dan Anda dapat melanjutkan dengan login ke konsol.
-
Catat kredensial lab (Nama pengguna dan Sandi) Anda. Anda akan menggunakannya untuk login ke Konsol Google Cloud.
-
Klik Open Google console.
-
Klik Use another account, lalu salin/tempel kredensial lab ini ke perintah yang muncul.
Jika menggunakan kredensial lain, Anda akan menerima pesan error atau dikenai biaya.
-
Setujui ketentuan dan lewati halaman resource pemulihan.
Catatan: Jangan klik End lab kecuali Anda sudah menyelesaikan lab atau ingin mengulanginya. Tindakan ini akan membersihkan pekerjaan Anda dan menghapus project.
Cara memulai lab dan login ke Google Cloud Console
-
Klik tombol Start Lab. Jika Anda perlu membayar lab, dialog akan terbuka untuk memilih metode pembayaran.
Di sebelah kiri ada panel Lab Details yang berisi hal-hal berikut:
- Tombol Open Google Cloud console
- Waktu tersisa
- Kredensial sementara yang harus Anda gunakan untuk lab ini
- Informasi lain, jika diperlukan, untuk menyelesaikan lab ini
-
Klik Open Google Cloud console (atau klik kanan dan pilih Open Link in Incognito Window jika Anda menjalankan browser Chrome).
Lab akan menjalankan resource, lalu membuka tab lain yang menampilkan halaman Sign in.
Tips: Atur tab di jendela terpisah secara berdampingan.
Catatan: Jika Anda melihat dialog Choose an account, klik Use Another Account.
-
Jika perlu, salin Username di bawah dan tempel ke dialog Sign in.
{{{user_0.username | "Username"}}}
Anda juga dapat menemukan Username di panel Lab Details.
-
Klik Next.
-
Salin Password di bawah dan tempel ke dialog Welcome.
{{{user_0.password | "Password"}}}
Anda juga dapat menemukan Password di panel Lab Details.
-
Klik Next.
Penting: Anda harus menggunakan kredensial yang diberikan lab. Jangan menggunakan kredensial akun Google Cloud Anda.
Catatan: Menggunakan akun Google Cloud sendiri untuk lab ini dapat dikenai biaya tambahan.
-
Klik halaman berikutnya:
- Setujui persyaratan dan ketentuan.
- Jangan tambahkan opsi pemulihan atau autentikasi 2 langkah (karena ini akun sementara).
- Jangan mendaftar uji coba gratis.
Setelah beberapa saat, Konsol Google Cloud akan terbuka di tab ini.
Catatan: Untuk mengakses produk dan layanan Google Cloud, klik Navigation menu atau ketik nama layanan atau produk di kolom Search.

Mengaktifkan Cloud Shell
Cloud Shell adalah mesin virtual dengan beberapa alat pengembangan. Mesin virtual ini menawarkan direktori beranda persisten berkapasitas 5 GB dan berjalan di Google Cloud. Cloud Shell memberikan akses command line ke resource Google Cloud Anda. gcloud adalah alat command line untuk Google Cloud. Fitur ini sudah terinstal di Cloud Shell dan mendukung penyelesaian tab.
-
Di Google Cloud Console, pada panel navigasi, klik Activate Cloud Shell ( ).
).
-
Klik Continue.
Perlu waktu beberapa saat untuk menyediakan dan menghubungkan ke lingkungan. Setelah terhubung, Anda juga diautentikasi, dan project ditetapkan ke PROJECT_ID Anda. Contoh:

Contoh perintah
gcloud auth list
(Output)
Akun berkredensial:
- <myaccount>@<mydomain>.com (active)
(Contoh output)
Akun berkredensial:
- google1623327_student@qwiklabs.net
gcloud config list project
(Output)
[core]
project = <project_ID>
(Contoh output)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Memeriksa izin project
Sebelum mulai bekerja di Google Cloud, Anda harus memastikan project Anda memiliki izin yang tepat dalam Identity and Access Management (IAM).
-
Di Konsol Google Cloud, pada Navigation menu ( ), klik IAM & Admin > IAM.
), klik IAM & Admin > IAM.
-
Pastikan Akun Layanan komputasi default {project-number}-compute@developer.gserviceaccount.com tersedia dan peran editor telah ditetapkan. Prefiks akun adalah nomor project yang dapat Anda temukan di Navigation menu > Cloud overview.

Jika akun tersebut tidak ada di IAM atau tidak memiliki peran editor, ikuti langkah-langkah di bawah untuk menetapkan peran yang diperlukan.
-
Di Konsol Google Cloud, pada Navigation menu, klik Cloud overview.
-
Dari kartu Project info, salin Project number.
-
Pada Navigation menu, klik IAM & Admin > IAM.
-
Di bagian atas halaman IAM, klik Add.
-
Untuk New principals, ketik:
{project-number}-compute@developer.gserviceaccount.com
Ganti {project-number} dengan nomor project Anda.
-
Untuk Select a role, pilih Basic (atau Project) > Editor.
-
Klik Save.
Tugas 1. Menambahkan izin yang diperlukan untuk instance Cloud Data Fusion
-
Di kolom judul Konsol Google Cloud, di kolom Search, ketik Data Fusion, klik Search, lalu klik Data Fusion.
-
Klik ikon Pin di samping Data Fusion.
Catatan: Pembuatan instance memerlukan waktu sekitar 15-20 menit. Harap tunggu sampai prosesnya selesai.
Selanjutnya, Anda akan memberikan izin ke akun layanan yang terkait dengan instance tersebut, menggunakan langkah-langkah berikut.
-
Dari Konsol Google Cloud, buka IAM & Admin > IAM.
-
Pastikan akun layanan default Compute Engine {project-number}-compute@developer.gserviceaccount.com ada, lalu salin Akun Layanan tersebut ke papan klip Anda.
-
Di halaman IAM, klik +Grant Access.
-
Di kolom New principals, tempelkan akun layanan tadi.
-
Klik kolom Select a role dan mulai ketik "Cloud Data Fusion API Service Agent", lalu pilih peran tersebut.
-
Klik ADD ANOTHER ROLE.
-
Tambahkan peran Managed Service for Spark Administrator.
-
Klik Save.
Klik Periksa progres saya untuk memverifikasi tujuan.
Menambahkan peran Agen Layanan Cloud Data Fusion API ke akun layanan
Memberikan izin pengguna kepada akun layanan
-
Di konsol, pada Navigation menu, klik IAM & admin > IAM.
-
Pilih kotak centang Include Google-provided role grants.
-
Scroll ke bawah dalam daftar untuk menemukan akun layanan Cloud Data Fusion yang dikelola Google yang terlihat seperti service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com, lalu salin nama akun layanan tersebut ke papan klip Anda.

-
Selanjutnya, buka IAM & admin > Service Accounts.
-
Klik akun compute engine default yang terlihat seperti {project-number}-compute@developer.gserviceaccount.com, lalu pilih tab Principals with access di menu navigasi bagian atas.
-
Klik tombol Grant Access.
-
Di kolom New Principals, tempel akun layanan yang telah Anda salin sebelumnya.
-
Pada menu dropdown Role, pilih Service Account User.
-
Klik Save.
Tugas 2. Memuat data
Selanjutnya, Anda akan membuat bucket Cloud Storage di dalam project Anda agar dapat memuat beberapa data sampel untuk proses Wrangling. Cloud Data Fusion nantinya akan membaca data dari bucket Storage ini.
- Di Cloud Shell, jalankan perintah berikut untuk membuat bucket baru:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
Nama bucket yang dibuat akan sama dengan Project ID Anda.
- Jalankan perintah berikut untuk menyalin file data (file CSV) ke dalam bucket Anda:
gcloud storage cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Klik Periksa progres saya untuk memverifikasi tujuan.
Memuat data
Sekarang Anda siap untuk melanjutkan proses ke tahap berikutnya.
Tugas 3. Menavigasi UI Cloud Data Fusion
Di dalam UI Cloud Data Fusion, Anda dapat menggunakan berbagai halaman, seperti Pipeline Studio atau Wrangler, untuk menggunakan fitur Cloud Data Fusion.
Untuk menavigasi UI Cloud Data Fusion, ikuti langkah-langkah berikut:
- Di Konsol, kembali ke Navigation menu > Data Fusion.
- Kemudian klik link View Instance di samping instance Data Fusion Anda.
- Pilih kredensial lab Anda untuk login.
Catatan: Jika Anda melihat pesan error 500, tutup tab Anda dan ulangi langkah 2-3.
UI web Cloud Data Fusion dilengkapi dengan panel navigasinya sendiri (di sebelah kiri) untuk berpindah ke halaman yang Anda butuhkan.
- Di UI Cloud Data, klik Navigation menu di pojok kiri atas untuk menampilkan panel navigasi.
- Selanjutnya pilih Wrangler.
Tugas 4. Bekerja dengan Wrangler
Wrangler adalah alat visual interaktif yang dapat Anda gunakan untuk melihat efek transformasi pada sebagian kecil data sebelum menjalankan tugas pemrosesan paralel skala besar pada seluruh set data.
-
Saat Wrangler dimuat, di sisi kiri terdapat panel dengan koneksi data yang telah dikonfigurasi sebelumnya, termasuk koneksi Cloud Storage.
-
Di GCS, pilih Cloud Storage Default.
-
Klik bucket yang sesuai dengan Project ID Anda.
-
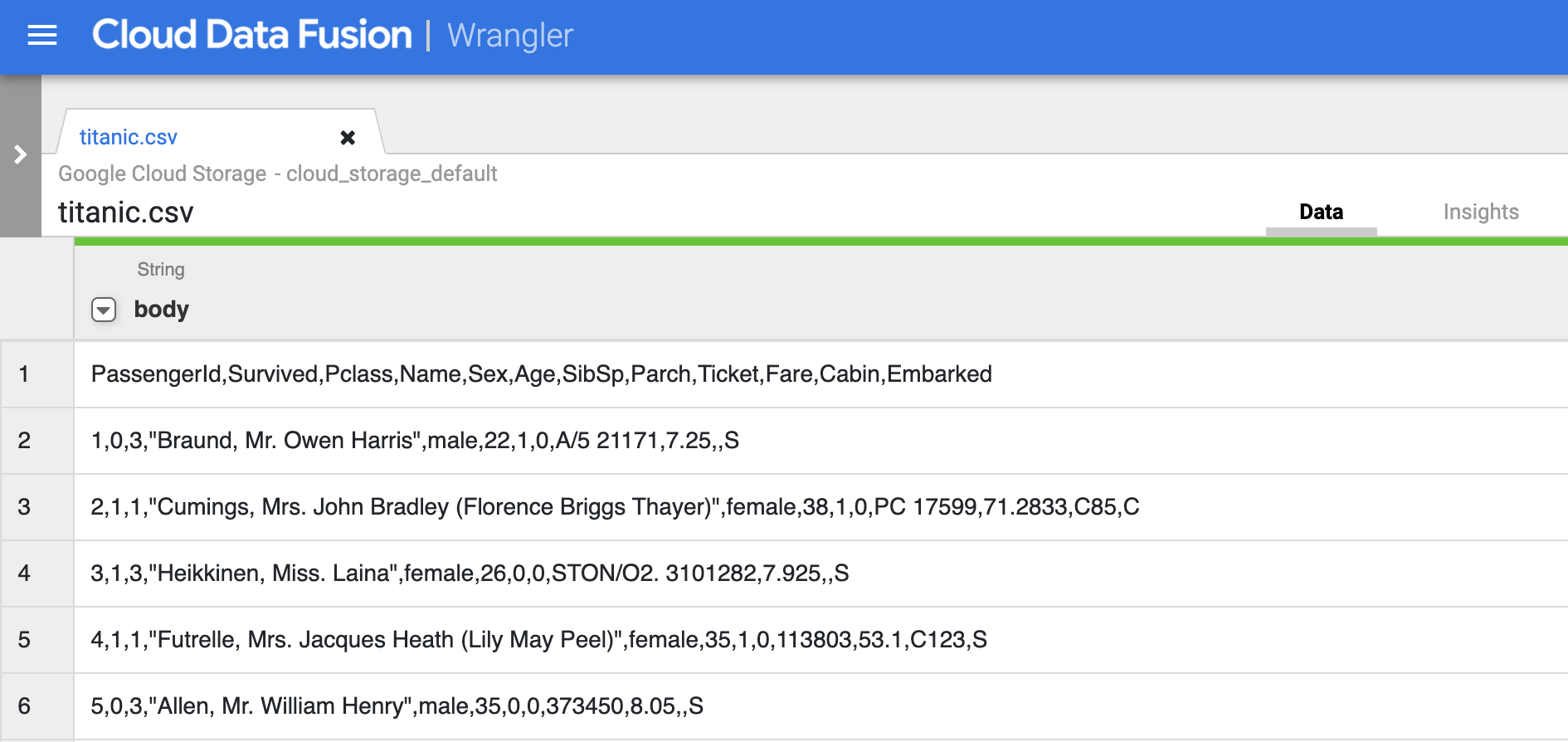
Klik titanic.csv.
-
Pada opsi parsing, pilih format text dari drop-down.
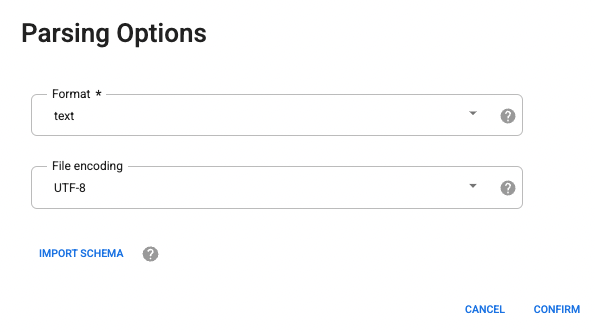
- Klik Confirm. Data akan dimuat ke dalam Wrangler.
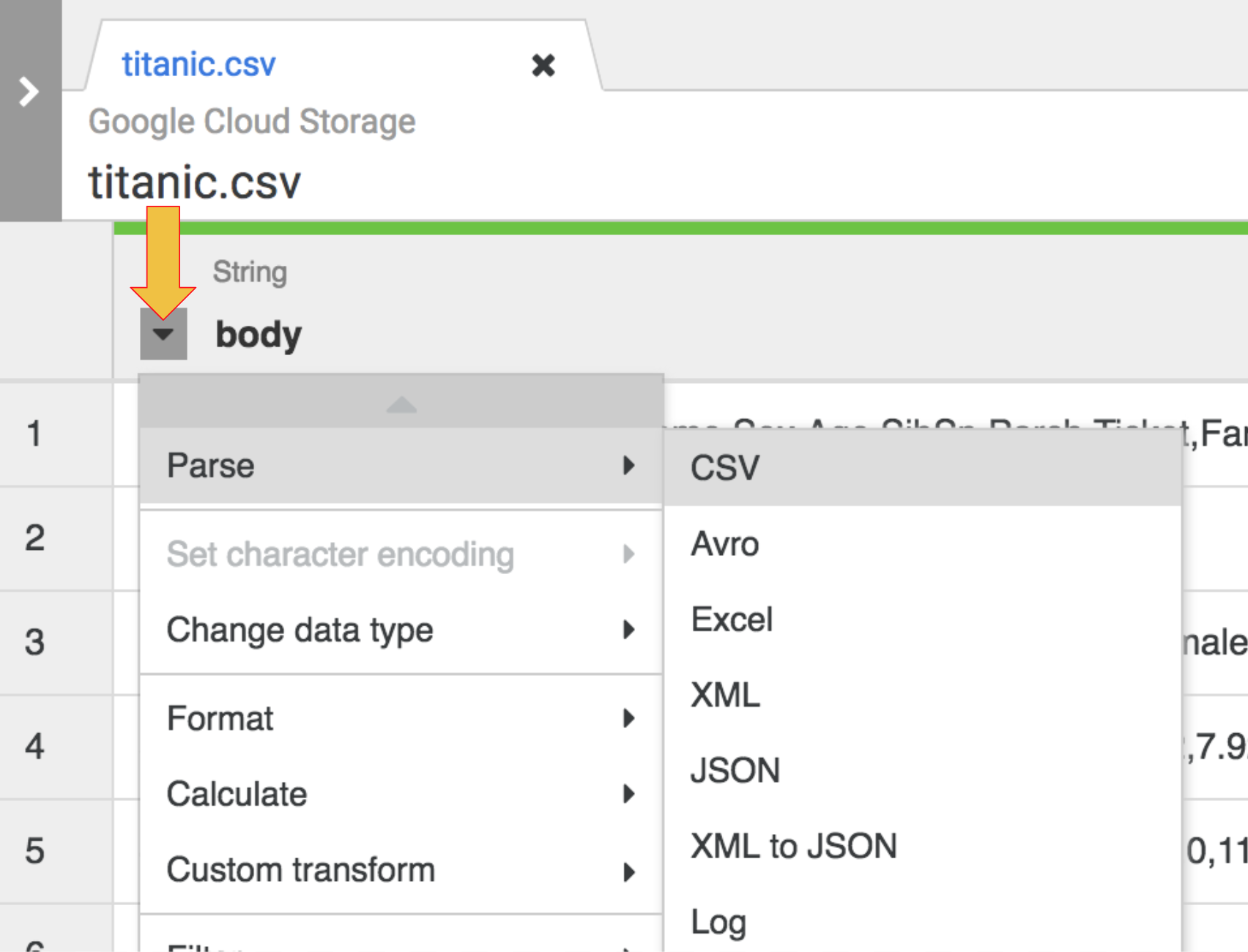
- Operasi pertama adalah mengurai data CSV mentah menjadi representasi tabular yang terbagi menjadi baris dan kolom. Untuk melakukannya, pilih ikon drop-down dari header kolom pertama, lalu pilih item menu Parse, dan CSV dari submenu yang muncul.
-
Pada data mentah, kita dapat melihat bahwa baris pertama terdiri atas header kolom. Jadi, Anda perlu memilih opsi Set first row as header di kotak dialog Parse as CSV yang ditampilkan, lalu klik Apply.
-
Di tahap ini, data mentah akan terurai dan Anda dapat melihat kolom yang dihasilkan oleh operasi ini di sebelah kanan kolom body
-
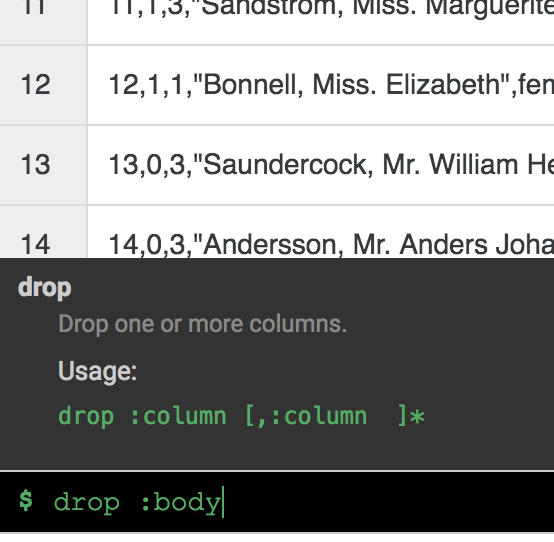
Karena kolom body tidak lagi diperlukan, hapus kolom tersebut dengan memilih ikon drop-down di samping header kolom body, lalu pilih item menu Delete column.
Catatan: Untuk menerapkan transformasi, Anda juga dapat menggunakan antarmuka command line (CLI). CLI adalah baris hitam di bagian bawah layar (dengan prompt $ berwarna hijau). Saat Anda mulai mengetik perintah, fitur isi otomatis akan aktif dan menampilkan opsi yang sesuai. Misalnya, untuk menghapus kolom body, Anda dapat menggunakan perintah alternatif: drop: body.
- Klik tab Transformation steps di ujung kanan UI Wrangler Anda. Anda akan melihat dua transformasi yang telah Anda terapkan sejauh ini.
Catatan:
Baik pilihan menu maupun CLI akan menghasilkan perintah yang terlihat di tab Transformation steps
di sebelah kanan layar. Perintah adalah transformasi individual yang secara kolektif disebut sebagai urutan langkah.
Di bagian lab selanjutnya, Anda akan menambahkan lebih banyak langkah transformasi menggunakan CLI.
Saat Anda menerapkan Transformation Steps ke set data, transformasi tersebut akan memengaruhi sampel data dan memberikan petunjuk visual yang dapat dieksplorasi melalui browser Insights.
- Klik tab Insights di bagian tengah atas untuk melihat cara data didistribusikan di berbagai kolom.
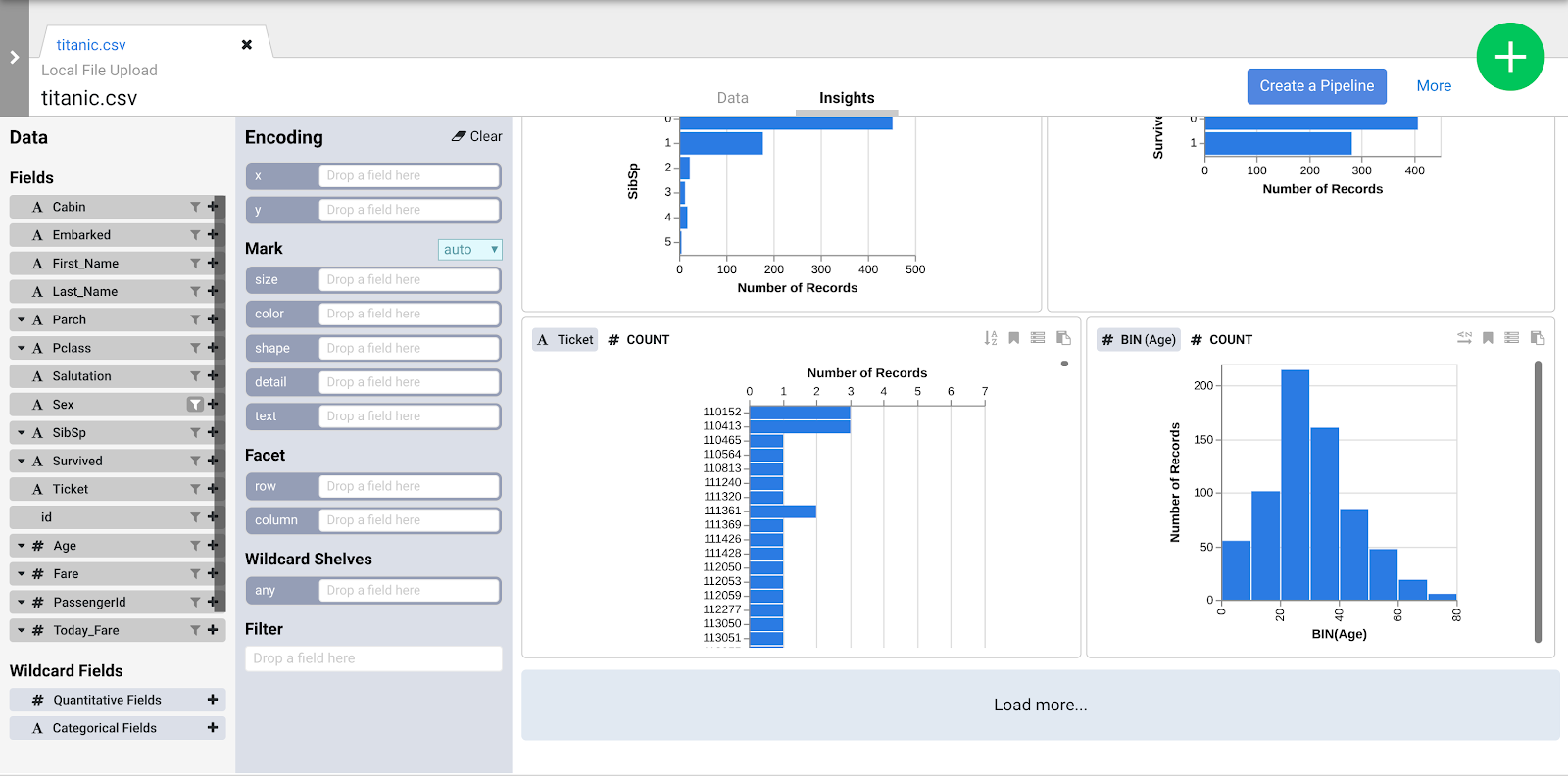
- Jelajahi antarmuka tersebut untuk menemukan cara baru dalam menganalisis data Anda. Tarik lalu lepas kolom Age ke encoding x untuk melihat perubahan perspektif data Anda.
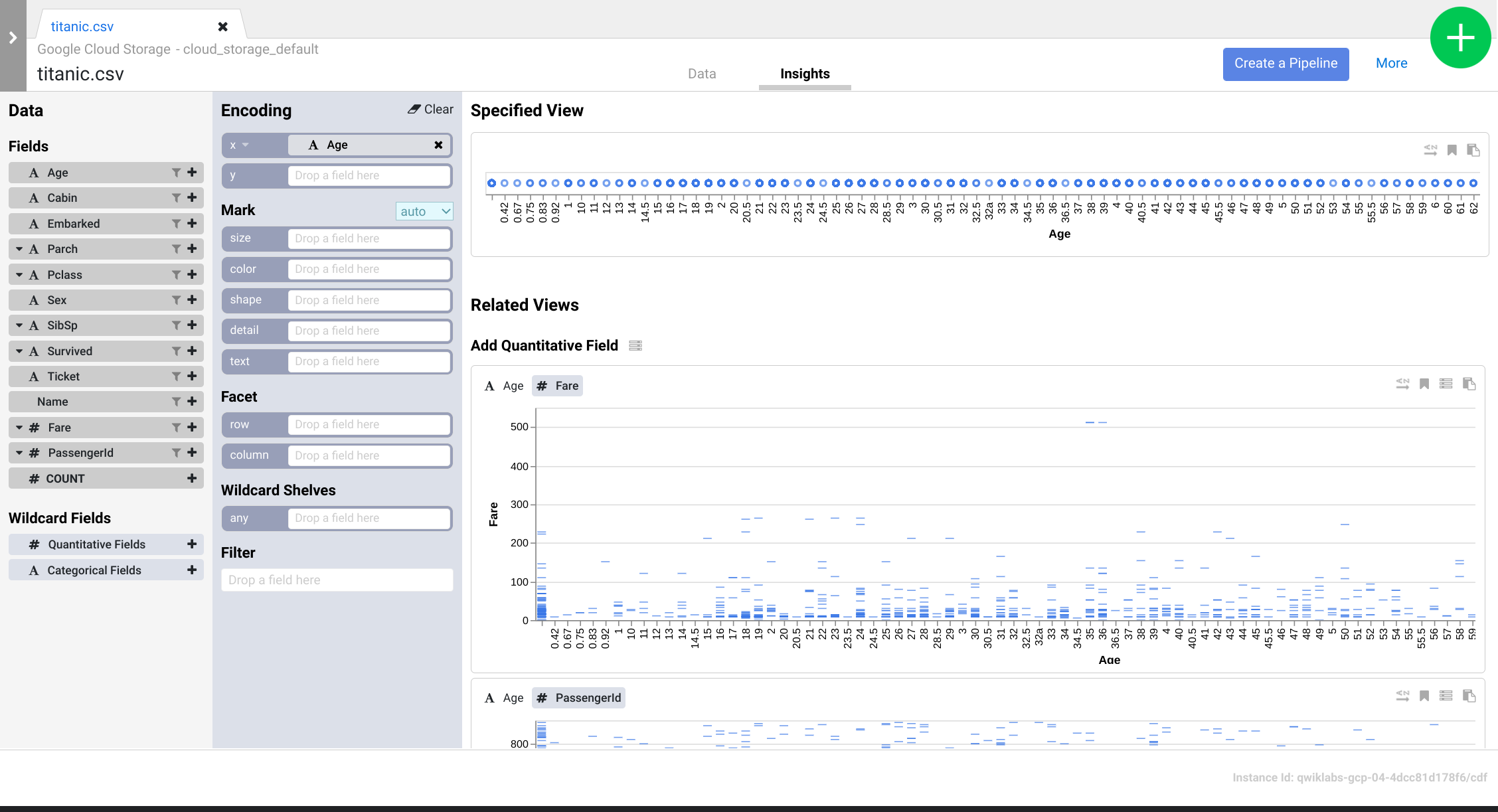
- Anda dapat mengklik tombol Create a Pipeline untuk beralih ke mode pengembangan pipeline. Di sini Anda dapat memeriksa perintah yang Anda buat dalam plugin Wrangler.

- Saat muncul kotak dialog berikutnya, pilih Batch pipeline untuk melanjutkan.
-
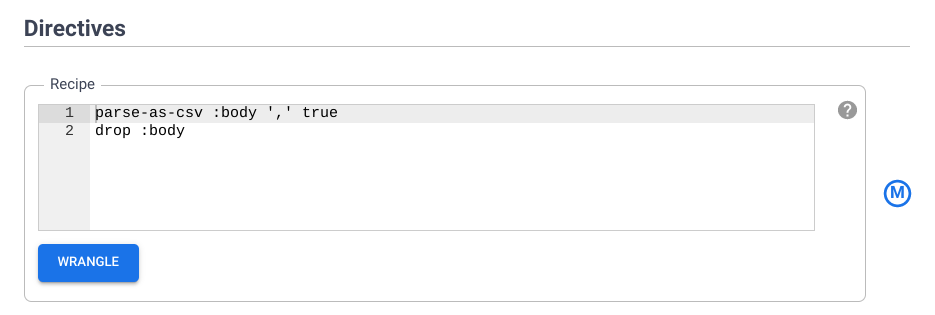
Setelah Pipeline Studio terbuka, arahkan kursor ke node Wrangler, lalu klik Properties
-
Di bagian Directives, tinjau kembali urutan langkah perintah yang telah Anda tambahkan sebelumnya. Di bagian berikutnya, Anda akan menambahkan langkah transformasi lainnya menggunakan CLI.
Tugas 5. Bekerja dengan Langkah Transformasi
Di bagian ini, Anda akan melanjutkan pekerjaan di UI Wrangler untuk menjelajahi set data CSV dan menerapkan transformasi melalui CLI.
-
Klik tombol Wrangler di bagian Directives pada kotak Properties node Wrangler Anda. Anda akan kembali ke UI Wrangler.
-
Klik Transformation steps di sisi paling kanan UI Wrangler Anda untuk menampilkan perintah yang ada. Pastikan Anda saat ini memiliki dua langkah transformasi.
Sekarang Anda akan menambahkan langkah transformasi lainnya menggunakan CLI dan melihat cara langkah tersebut memodifikasi data. CLI adalah baris hitam di bagian bawah layar (dengan prompt $ berwarna hijau).
- Salin perintah, lalu tempelkan ke CLI Anda di prompt $. Anda akan melihat Transformation Steps di sisi kanan layar Anda diperbarui.
fill-null-or-empty :Cabin 'none'
send-to-error empty(Age)
parse-as-csv :Name ',' false
drop Name
fill-null-or-empty :Name_2 'none'
rename Name_1 Last_Name
rename Name_2 First_Name
set-type :PassengerId integer
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125)
set-type :Age integer
set-type :Fare double
set-column Today_Fare (Fare * 23.4058)+1
generate-uuid id
mask-shuffle First_Name
Berikut adalah penjelasan mengenai fungsi masing-masing perintah terhadap data Anda. JANGAN memasukkan kembali perintah ini ke dalam CLI karena Anda baru saja melakukannya pada langkah sebelumnya.
a. fill-null-or-empty :Cabin 'none' memperbaiki kolom Cabin sehingga datanya menjadi 100% lengkap.
b. send-to-error empty(Age) memperbaiki kolom Age sehingga tidak ada sel yang kosong
c. parse-as-csv :Name ',' false memisahkan kolom Name menjadi dua kolom terpisah yang berisi nama depan dan nama belakang
d. rename Name_1 Last_Name dan rename Name_2 First_Name mengganti nama kolom yang baru dibuat, Name_1 dan Name_2, menjadi Last_Name dan First_Name
e. drop Name menghapus kolom Name karena tidak diperlukan lagi
f. set-type :PassengerId integer mengonversi kolom PassengerId menjadi bilangan bulat
g. Perintah ini akan mengekstrak sapaan dari kolom First_Name, menghapus kolom yang berlebihan, dan mengganti nama kolom yang baru dibuat sesuai dengan fungsinya:
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
h. Perintah send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125) melakukan pemeriksaan kualitas data pada kolom Age, sementara set-type :Age integer menetapkannya sebagai kolom bertipe bilangan bulat
i. set-type :Fare double mengonversi kolom Fare menjadi Double sehingga Anda dapat melakukan operasi aritmatika dengan nilai kolom
j. set-column Today_Fare (Fare * 23.4058)+1 mengalikan kolom Fare dengan tingkat inflasi Dolar sejak tahun 1912 untuk mendapatkan nilai Dolar yang telah disesuaikan
k. generate-uuid id membuat kolom identitas untuk mengidentifikasi tiap kumpulan data secara unik
l. mask-shuffle First_Name akan menyamarkan kolom Last_Name untuk melakukan de-identifikasi seseorang, yang dikategorikan sebagai PII
-
Klik link More di pojok kanan persis di bagian atas Transformation steps, lalu klik View Schema untuk memeriksa skema yang dihasilkan transformasi, dan klik ikon download untuk mendownloadnya ke komputer Anda.
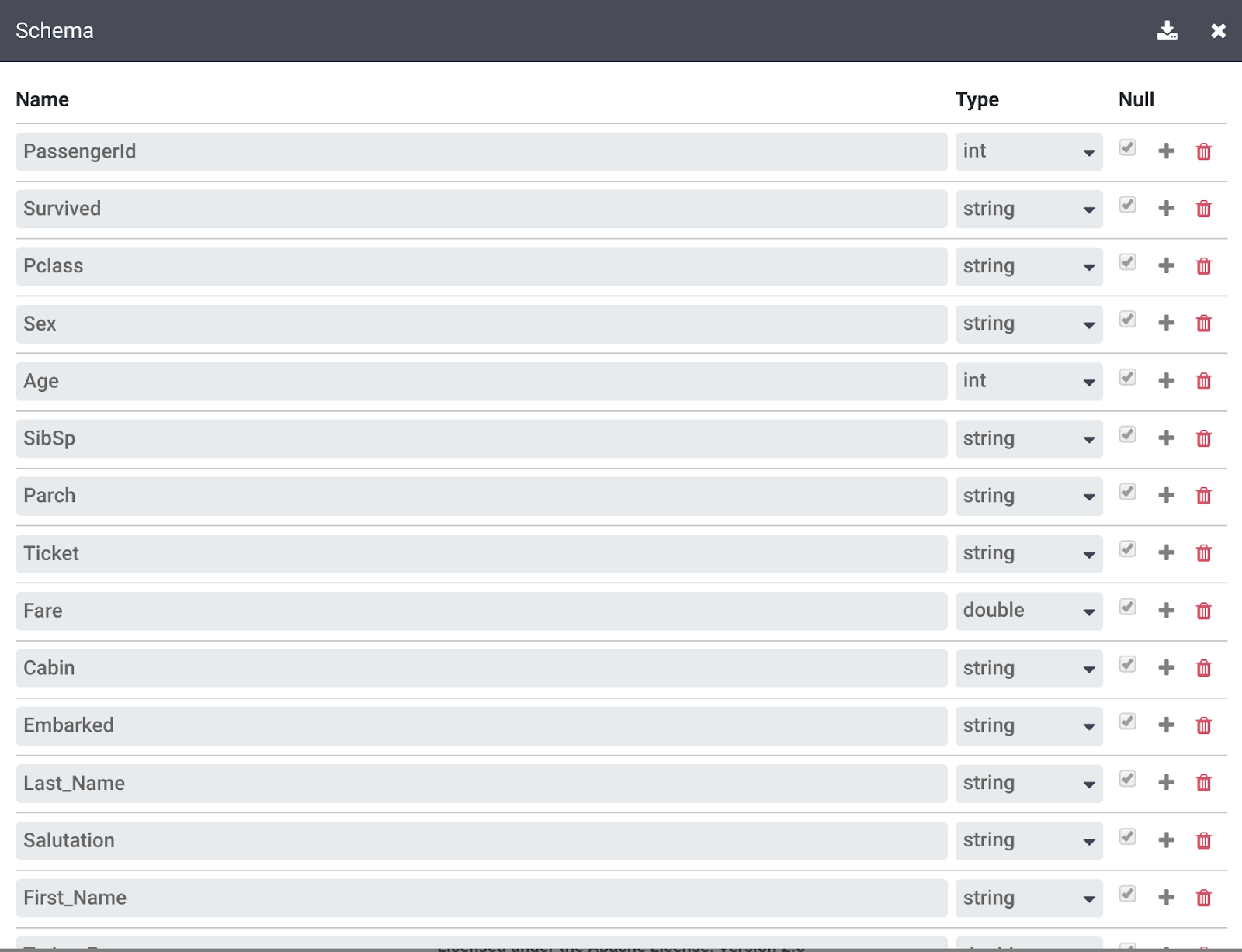
-
Klik X untuk menutup halaman Schema.
-
Anda dapat mengklik ikon download di bagian Transformation steps untuk mendownload urutan langkah perintah ke komputer Anda guna menyimpan salinan langkah transformasi untuk penggunaan pada masa mendatang.

-
Klik tombol Apply di pojok kanan atas untuk memastikan semua langkah transformasi yang baru dimasukkan telah ditambahkan ke konfigurasi node Wrangler. Anda kemudian akan dialihkan kembali ke kotak properti node Wrangler.
-
Klik X untuk menutupnya. Sekarang Anda telah kembali ke Pipeline Studio.
Tugas 6. Penyerapan ke BigQuery
Untuk menyerap data ke BigQuery, buat set data terlebih dahulu.
-
Di tab baru, buka BigQuery di Konsol Google Cloud atau klik kanan tab konsol Google Cloud dan pilih Duplicate, lalu gunakan Navigation menu untuk memilih BigQuery. Jika diminta, klik Done.
-
Di panel Explorer, klik ikon View actions di samping Project ID Anda (akan dimulai dengan qwiklabs), lalu pilih Create dataset.
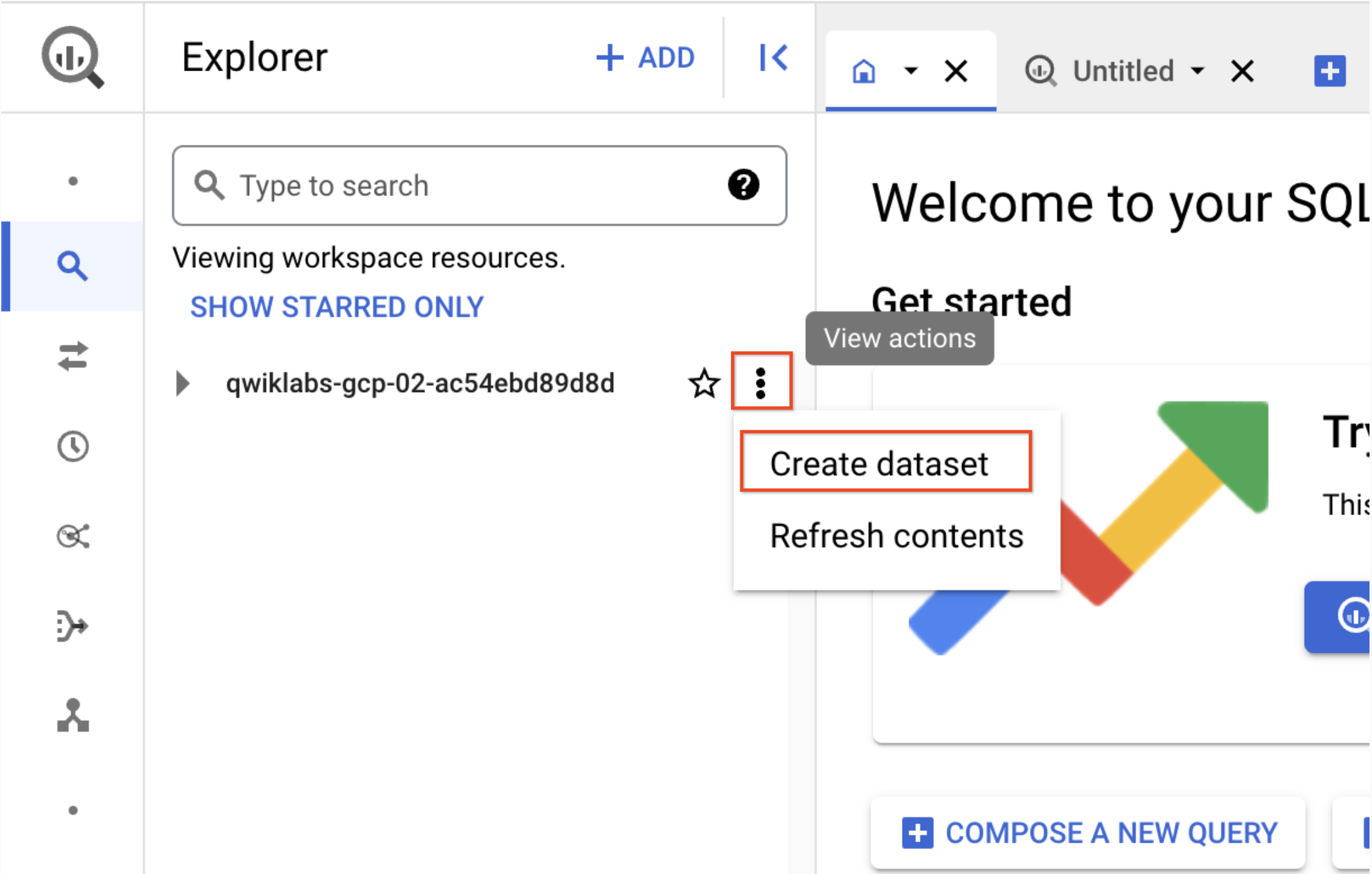
a. ID Set data: demo_cdf
b. Klik Create dataset. Catat nama ini untuk digunakan nanti di lab.
- Kembali ke tab UI Cloud Data Fusion
a. Untuk menambahkan sink BigQuery ke pipeline, buka bagian Sink di panel sebelah kiri, lalu klik ikon BigQuery untuk menempatkannya di canvas.
b. Setelah sink BigQuery muncul di canvas, hubungkan node Wrangler dengan node BigQuery. Caranya, tarik tanda panah dari node Wrangler dan hubungkan ke node BigQuery seperti yang diilustrasikan.
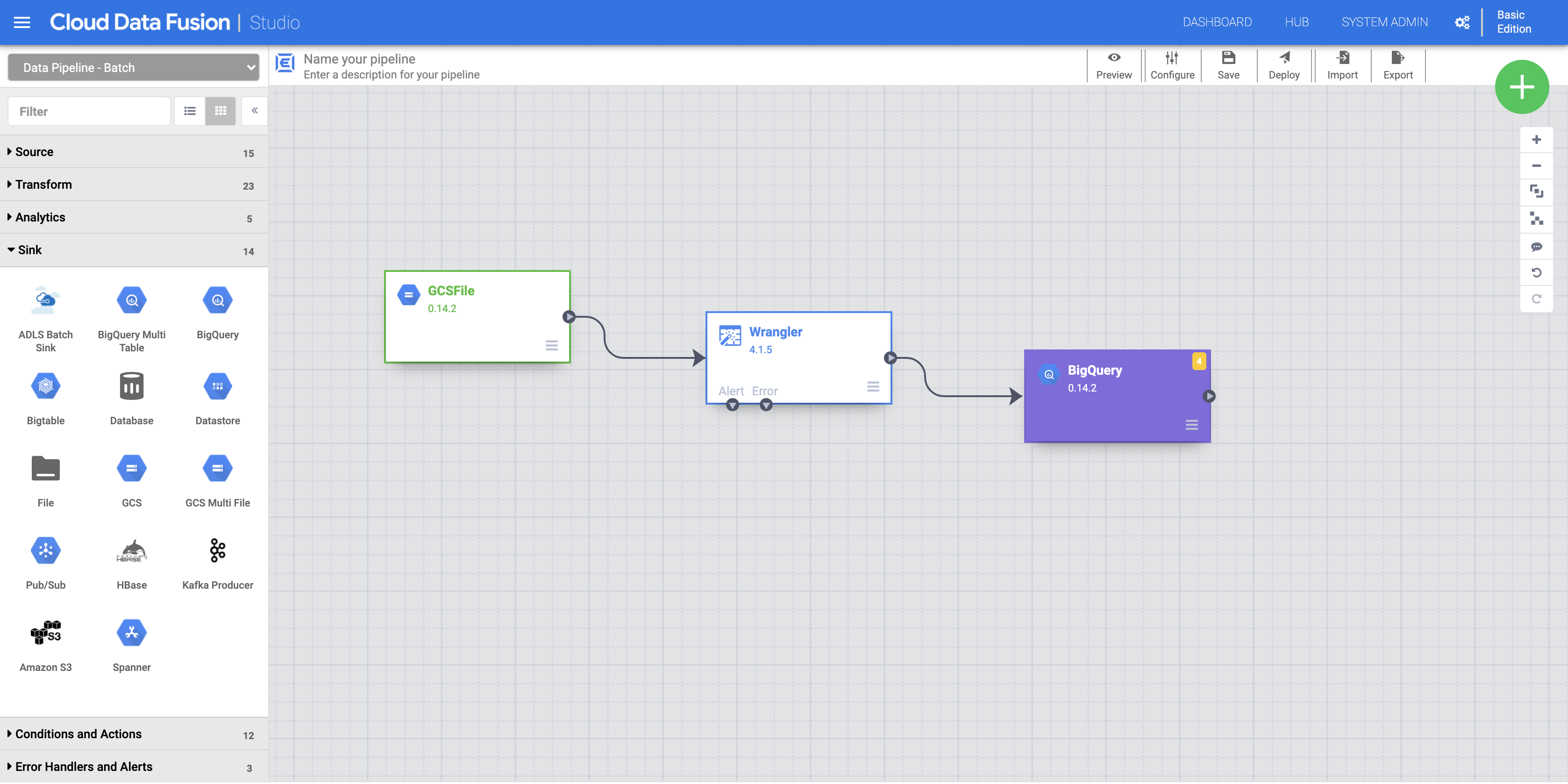
c. Arahkan mouse ke node BigQuery Anda, klik Properties, lalu masukkan setelan konfigurasi berikut:
| Kolom |
Nilai |
| Reference Name |
DemoSink |
| Dataset Project ID |
Project ID Anda. |
| Dataset |
demo_cdf (set data yang Anda buat di langkah sebelumnya) |
| Table |
Masukkan nama yang sesuai (misalnya titanic) |
Tabel akan dibuat secara otomatis oleh sistem.
d. Klik tombol Validate untuk memeriksa apakah semuanya sudah diatur dengan benar atau belum.
e. Klik X untuk menutupnya. Dan Anda telah kembali ke Pipeline Studio.
- Sekarang Anda siap untuk menjalankan pipeline Anda.
a. Beri nama untuk pipeline Anda (misalnya DemoBQ)
b. Klik Save, lalu klik Deploy di pojok kanan atas untuk men-deploy pipeline.
c. Klik Run untuk memulai eksekusi pipeline. Anda dapat mengklik ikon Summary untuk melihat beberapa statistik.
Catatan: Jika pipeline gagal, jalankan kembali
Setelah eksekusi selesai, statusnya akan berubah menjadi Succeeded. Kembali ke Konsol BigQuery untuk mengkueri hasil Anda.
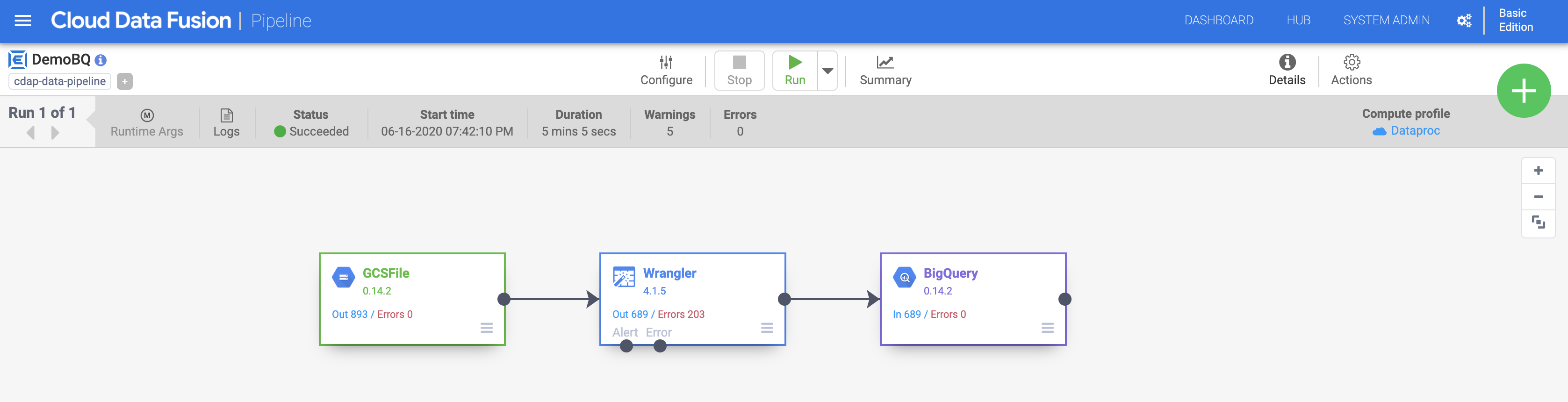
Klik Periksa progres saya untuk memverifikasi tujuan.
Penyerapan ke BigQuery
Selamat!
Di lab ini, Anda telah mempelajari UI Wrangler. Anda telah mempelajari cara menambahkan langkah-langkah transformasi (perintah) melalui menu serta menggunakan CLI. Dengan Wrangler, Anda dapat menerapkan berbagai transformasi data yang mumpuni secara iteratif, dan Anda dapat menggunakan UI Wrangler untuk meninjau pengaruhnya terhadap skema data sebelum men-deploy serta menjalankan pipeline Anda.
Mengakhiri lab Anda
Setelah Anda menyelesaikan lab, klik End Lab. Google Skills akan menghapus resource yang telah Anda gunakan dan membersihkan akun.
Anda akan diberi kesempatan untuk menilai pengalaman menggunakan lab. Pilih jumlah bintang yang sesuai, ketik komentar, lalu klik Submit.
Makna jumlah bintang:
- 1 bintang = Sangat tidak puas
- 2 bintang = Tidak puas
- 3 bintang = Netral
- 4 bintang = Puas
- 5 bintang = Sangat puas
Anda dapat menutup kotak dialog jika tidak ingin memberikan masukan.
Untuk masukan, saran, atau koreksi, gunakan tab Support.
Hak cipta 2026 Google LLC. Semua hak dilindungi undang-undang. Google dan logo Google adalah merek dagang dari Google LLC. Semua nama perusahaan dan produk lain mungkin adalah merek dagang dari tiap-tiap perusahaan yang bersangkutan.





