Übersicht
Bei der Datenintegration dreht sich alles um Ihre Daten. Und wenn Sie mit Daten arbeiten, ist es hilfreich, die Rohdaten zu sehen. Dann können Sie sie als Ausgangspunkt für die Transformation verwenden. Mit Wrangler können Sie einen datenorientierten Ansatz für Ihren Datenintegrations-Workflow wählen.
Die häufigste Datenquelle für ETL-Anwendungen (Extrahieren, Transformieren und Laden) sind in der Regel Daten, die in Textdateien im CSV-Format (Comma Separated Value) gespeichert sind. Viele Datenbanksysteme exportieren und importieren Daten auf diese Weise. In diesem Lab verwenden Sie eine CSV-Datei, aber die gleichen Techniken können auch auf Datenbankquellen sowie auf jede andere in Cloud Data Fusion verfügbare Datenquelle angewendet werden.
Ziele
Aufgaben in diesem Lab:
- Pipeline zur Aufnahme von Daten aus einer CSV-Datei erstellen
- Mit Wrangler Transformationen über die Point-and-Click-Schnittstellen und Befehlszeilen anwenden
In diesem Lab arbeiten Sie hauptsächlich mit Wrangler-Transformationsschritten, die vom Wrangler-Plug-in verwendet werden. So sind Ihre Transformationen an einem Ort zusammengefasst und Sie können Transformationsaufgaben in überschaubare Blöcke gruppieren. Mit diesem datenorientierten Ansatz visualisieren Sie Ihre Transformationen schnell.
Einrichtung
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
-
Melden Sie sich über ein Inkognitofenster bei Google Skills an.
-
Beachten Sie die Zugriffszeit (z. B. 02:00:00) und achten Sie darauf, dass Sie das Lab innerhalb dieser Zeit abschließen.
Es gibt keine Pausenfunktion. Sie können bei Bedarf neu starten, müssen dann aber von vorn beginnen.
-
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Hinweis: Nachdem Sie auf Lab starten geklickt haben, dauert es etwa 15 bis 20 Minuten, bis die erforderlichen Ressourcen für das Lab bereitgestellt und eine Data Fusion-Instanz erstellt wurden.
In der Zwischenzeit können Sie sich anhand der unten aufgeführten Schritte mit den Zielen des Labs vertraut machen.
Wenn im linken Bereich Lab-Anmeldedaten (Nutzername und Passwort) angezeigt werden, ist die Instanz erstellt und Sie können sich in der Console anmelden.
-
Notieren Sie sich Ihre Anmeldedaten (Nutzername und Passwort). Mit diesen Daten melden Sie sich in der Google Cloud Console an.
-
Klicken Sie auf Google Console öffnen.
-
Klicken Sie auf Anderes Konto verwenden. Kopieren Sie den Nutzernamen und das Passwort für dieses Lab und fügen Sie beides in die entsprechenden Felder ein.
Wenn Sie andere Anmeldedaten verwenden, tritt ein Fehler auf oder es fallen Kosten an.
-
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen.
Hinweis: Über den Button Lab beenden wird Ihre Arbeit gelöscht und das Projekt entfernt. Sie sollten daher nur darauf klicken, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
- Schaltfläche „Google Cloud Console öffnen“
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Cloud Shell bietet Ihnen Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen. gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
-
Klicken Sie in der Google Cloud Console im Navigationsbereich auf Cloud Shell aktivieren ( ).
).
-
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:

Beispielbefehle
gcloud auth list
(Ausgabe)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Beispielausgabe)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Ausgabe)
[core]
project = <project_ID>
(Beispielausgabe)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Projektberechtigungen prüfen
Bevor Sie mit der Arbeit in Google Cloud beginnen, müssen Sie sicherstellen, dass für Ihr Projekt im Rahmen von Identity and Access Management (IAM) die nötigen Berechtigungen vorliegen.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü ( ) auf IAM und Verwaltung > IAM.
) auf IAM und Verwaltung > IAM.
-
Prüfen Sie, ob das standardmäßige Compute-Dienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden und ihm die Rolle Bearbeiter zugewiesen ist. Das Kontopräfix ist die Projektnummer. Sie finden sie im Navigationsmenü unter Cloud-Übersicht.

Wenn das Konto nicht in IAM vorhanden ist oder nicht über die Bearbeiter-Rolle verfügt, weisen Sie die erforderliche Rolle so zu:
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf Cloud-Übersicht.
-
Kopieren Sie auf der Karte Projektinformationen die Projektnummer.
-
Klicken Sie im Navigationsmenü auf IAM und Verwaltung > IAM.
-
Klicken Sie oben auf der Seite IAM auf Hinzufügen.
-
Geben Sie unter Neue Hauptkonten ein:
{project-number}-compute@developer.gserviceaccount.com
Ersetzen Sie {project-number} durch die entsprechende Projektnummer.
-
Wählen Sie unter Rolle auswählen die Option Basic (oder „Projekt“) > Editor aus.
-
Klicken Sie auf Speichern.
Aufgabe 1: Erforderliche Berechtigungen für Ihre Cloud Data Fusion-Instanz hinzufügen
-
Geben Sie in der Titelleiste der Google Cloud Console im Feld Suchen Data Fusion ein, klicken Sie auf Suchen und dann auf Data Fusion.
-
Klicken Sie neben Data Fusion auf das Symbol Anpinnen.
Hinweis: Das Erstellen der Instanz kann bis zu 15–20 Minuten dauern. Bitte warten Sie, bis der Vorgang abgeschlossen ist.
Als Nächstes gewähren Sie dem Dienstkonto, das der Instanz zugeordnet ist, Berechtigungen. Gehen Sie dazu so vor:
-
Rufen Sie in der Google Cloud Console IAM und Verwaltung > IAM auf.
-
Prüfen Sie, ob das Compute Engine-Standarddienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden ist, und kopieren Sie das Dienstkonto in die Zwischenablage.
-
Klicken Sie auf der Seite „IAM-Berechtigungen“ auf + Zugriff erlauben.
-
Fügen Sie im Feld „Neue Hauptkonten“ das Dienstkonto ein.
-
Klicken Sie in das Feld Rolle auswählen und geben Sie „Cloud Data Fusion API-Dienst-Agent“ ein. Wählen Sie dann die Rolle aus.
-
Klicken Sie auf WEITERE ROLLE HINZUFÜGEN.
-
Fügen Sie die Rolle Managed Service for Spark-Administrator hinzu.
-
Klicken Sie auf Speichern.
Klicken Sie auf Fortschritt prüfen.
Rolle „Cloud Data Fusion API-Dienst-Agent“ zum Dienstkonto hinzufügen
Dienstkontonutzerin/Dienstkontonutzer die Berechtigung erteilen
-
Klicken Sie in der Console im Navigationsmenü auf IAM & Verwaltung > IAM.
-
Klicken Sie auf das Kästchen Von Google bereitgestellte Rollenzuweisungen einschließen.
-
Suchen Sie in der Liste nach dem von Google verwalteten Cloud Data Fusion-Dienstkonto, das so aussieht: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Kopieren Sie dann den Namen des Dienstkontos in die Zwischenablage.

-
Rufen Sie als Nächstes IAM & Verwaltung > Dienstkonten auf.
-
Klicken Sie auf das Compute Engine-Standardkonto, das so aussieht: {project-number}-compute@developer.gserviceaccount.com, und wählen Sie in der oberen Navigationsleiste den Tab Hauptkonten mit Zugriff aus.
-
Klicken Sie auf den Button Zugriff gewähren.
-
Fügen Sie im Feld Neue Hauptkonten das zuvor kopierte Dienstkonto ein.
-
Wählen Sie im Drop‑down-Menü Rolle die Option Dienstkontonutzer aus.
-
Klicken Sie auf Speichern.
Aufgabe 2: Daten laden
Als Nächstes erstellen Sie in Ihrem Projekt einen Cloud Storage-Bucket, damit Sie einige Beispieldaten für die Datenaufbereitung laden können. Cloud Data Fusion liest später Daten aus diesem Storage-Bucket.
- Führen Sie in Cloud Shell die folgenden Befehle aus, um einen neuen Bucket zu erstellen:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
Der erstellte Bucket-Name ist Ihre Projekt-ID.
- Führen Sie den Befehl aus, um die Datendatei (eine CSV-Datei) in Ihren Bucket zu kopieren:
gcloud storage cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Klicken Sie auf Fortschritt prüfen.
Daten laden
Jetzt können Sie fortfahren.
Aufgabe 3: Benutzeroberfläche von Cloud Data Fusion verwenden
In der Benutzeroberfläche von Cloud Data Fusion können Sie auf verschiedenen Seiten wie Pipeline Studio oder Wrangler die Funktionen von Cloud Data Fusion nutzen.
So verwenden Sie die Benutzeroberfläche von Cloud Data Fusion:
- Kehren Sie in der Console zum Navigationsmenü > Data Fusion zurück.
- Klicken Sie dann auf den Link Instanz ansehen neben Ihrer Data Fusion-Instanz.
- Wählen Sie die Anmeldedaten des Labs aus, um sich anzumelden.
Hinweis: Wenn Sie eine Fehlermeldung mit dem Code 500 erhalten, schließen Sie die Tabs und wiederholen die Schritte 2 und 3.
Die Web-Benutzeroberfläche von Cloud Data Fusion hat einen eigenen Navigationsbereich (links), über den Sie die gewünschte Seite aufrufen können.
- Klicken Sie in der Cloud Data-Benutzeroberfläche links oben auf das Navigationsmenü, um den Navigationsbereich einzublenden.
- Wählen Sie dann Wrangler aus.
Aufgabe 4: Mit Wrangler arbeiten
Wrangler ist ein interaktives, visuelles Tool, mit dem Sie die Effekte von Transformationen auf eine kleine Teilmenge von Daten sehen können, bevor Sie große, parallel verarbeitende Jobs für das gesamte Dataset starten.
-
Wenn Wrangler geladen ist, sehen Sie auf der linken Seite einen Bereich mit den vorkonfigurierten Verbindungen zu Ihren Daten, darunter auch die Cloud Storage-Verbindung.
-
Wählen Sie in GCS die Option Cloud Storage – Standard aus.
-
Klicken Sie auf den Bucket mit der entsprechenden Projekt-ID.
-
Klicken Sie auf titanic.csv.
-
Wählen Sie in den Parsing-Optionen im Drop-down-Menü das Format Text aus.
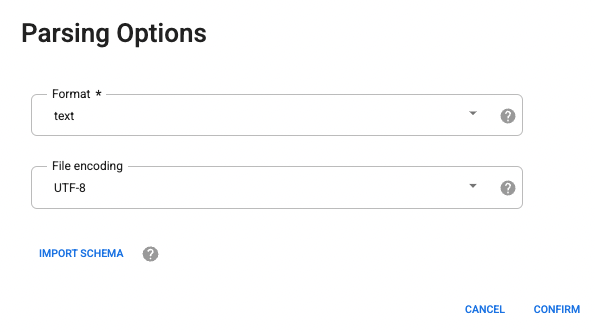
- Klicken Sie auf Bestätigen. Die Daten werden in Wrangler geladen.
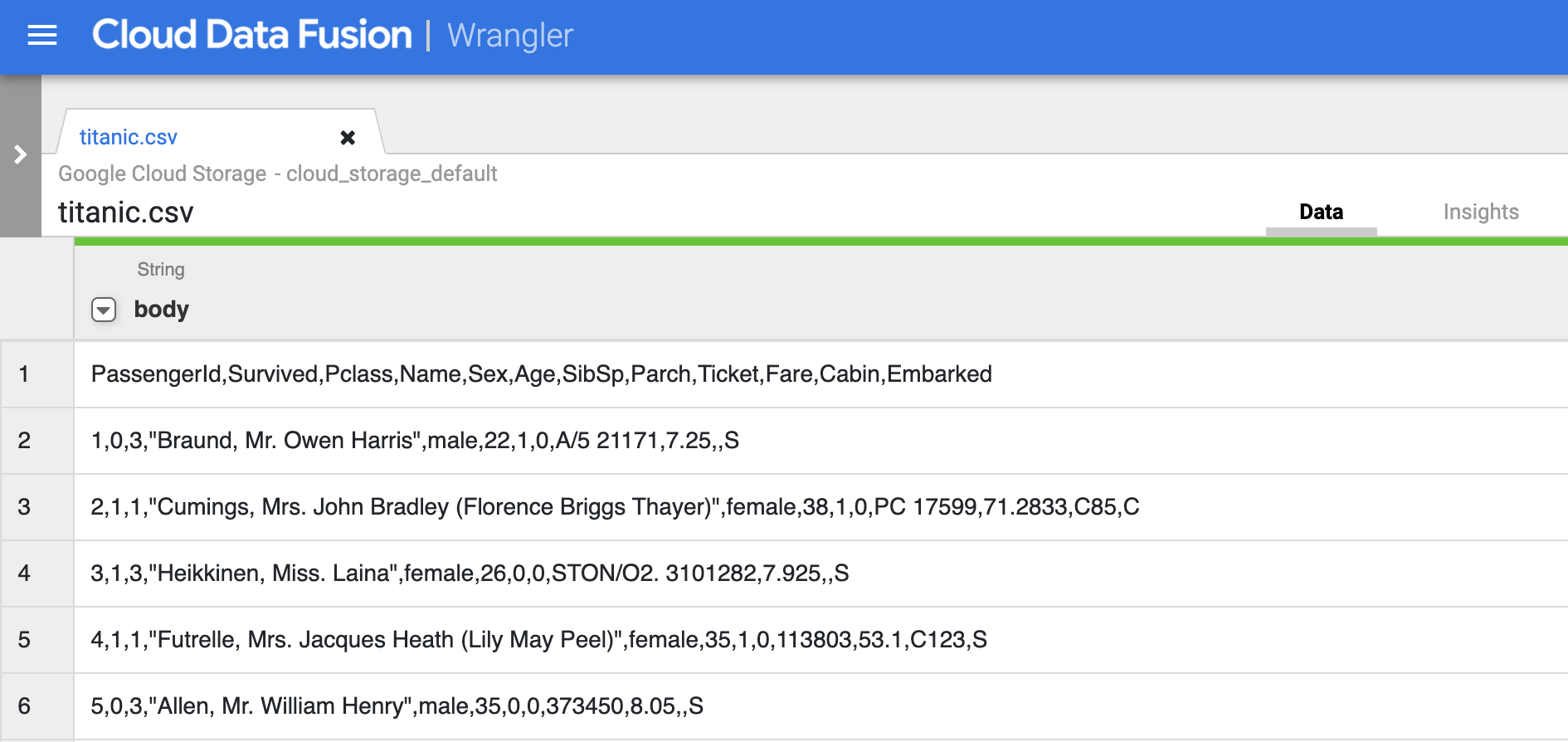
- Im ersten Schritt werden die CSV-Rohdaten in eine tabellarische Darstellung geparst, die in Zeilen und Spalten aufgeteilt ist. Klicken Sie dazu auf das Drop-down-Symbol in der ersten Spaltenüberschrift, wählen Sie den Menüpunkt Parsen und dann CSV aus dem Untermenü aus.
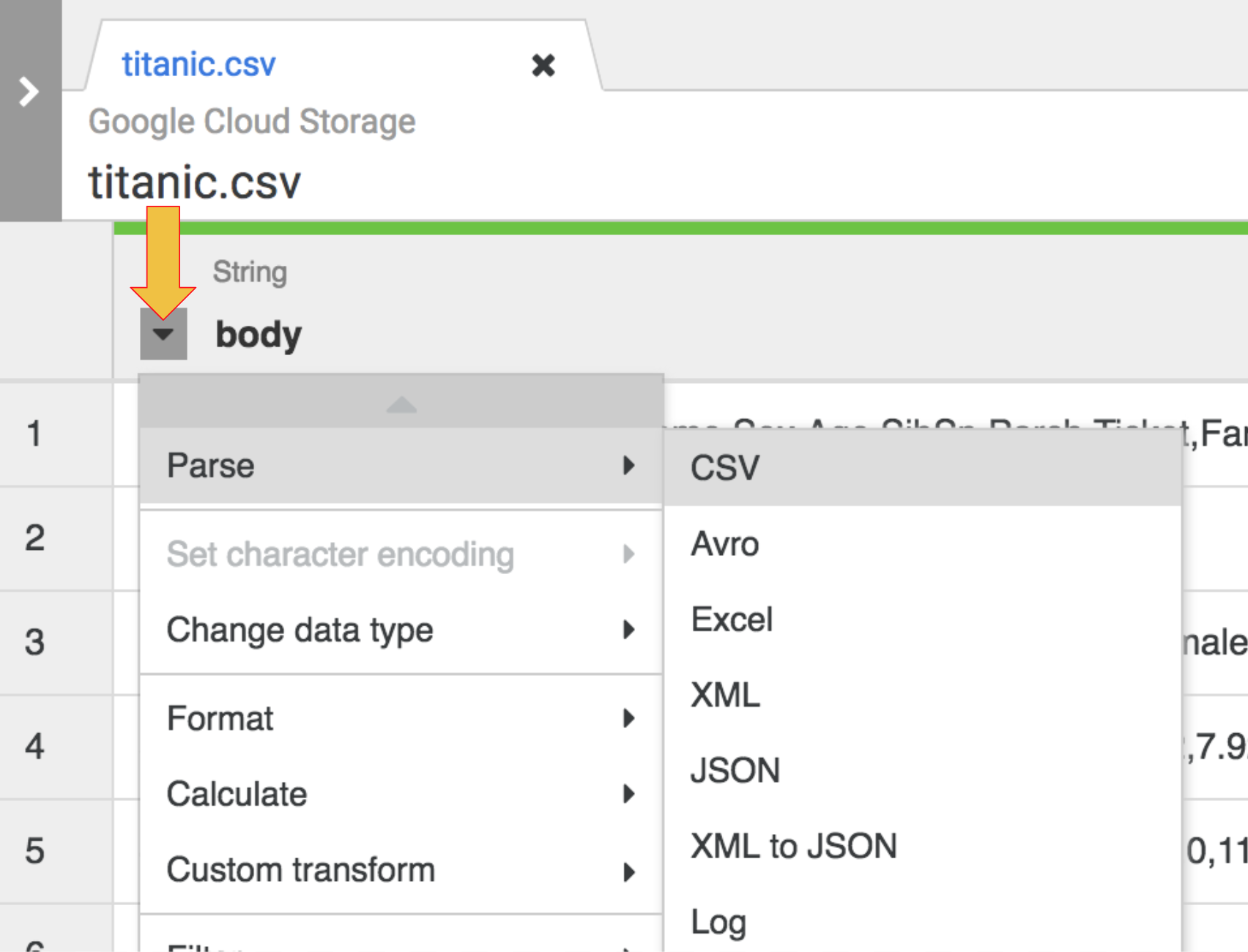
-
In den Rohdaten sehen Sie, dass die erste Zeile aus Spaltenüberschriften besteht. Wählen Sie daher im Dialogfeld Als CSV-Datei parsen die Option Erste Zeile als Header festlegen aus und klicken Sie auf Anwenden.
-
In dieser Phase werden die Rohdaten geparst. Die Spalten, die durch diesen Vorgang generiert werden, sehen Sie rechts neben der Spalte body.
-
Die Spalte body wird nicht mehr benötigt. Entfernen Sie sie, indem Sie auf das Drop-down-Symbol neben der Spaltenüberschrift body klicken und den Menüpunkt Spalte löschen auswählen.
Hinweis: Sie können Transformationen auch über die Befehlszeile anwenden. Die Befehlszeile ist die schwarze Leiste am unteren Bildschirmrand (mit dem grünen Prompt $). Wenn Sie mit der Eingabe von Befehlen beginnen, wird die Autofill-Funktion aktiviert und zeigt Ihnen eine passende Option an. Um beispielsweise die Spalte „body“ zu entfernen, hätten Sie alternativ die Anweisung drop: body verwenden können.
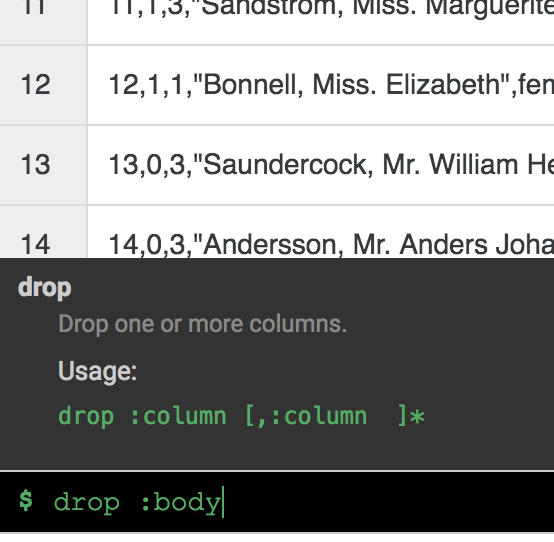
- Klicken Sie ganz rechts in der Wrangler-Benutzeroberfläche auf den Tab Transformationsschritte. Ihnen werden die beiden Transformationen angezeigt, die Sie bisher angewendet haben.
Hinweis:
Sowohl die Menüauswahl als auch die Befehlszeile erstellen Anweisungen, die auf dem Tab Transformationsschritte rechts auf dem Bildschirm angezeigt werden. Anweisungen sind einzelne Transformationen, die zusammen als Schema bezeichnet werden.
Später im Lab fügen Sie mit der Befehlszeile weitere Transformationsschritte hinzu.
Wenn Sie Transformationsschritte auf Ihr Dataset anwenden, wirken sich die Transformationen auf die erhobenen Stichproben aus und liefern visuelle Hinweise, die Sie über den Browser Insights untersuchen können.
- Klicken Sie oben in der Mitte auf den Tab Statistiken, um zu sehen, wie die Daten auf die verschiedenen Spalten verteilt sind.
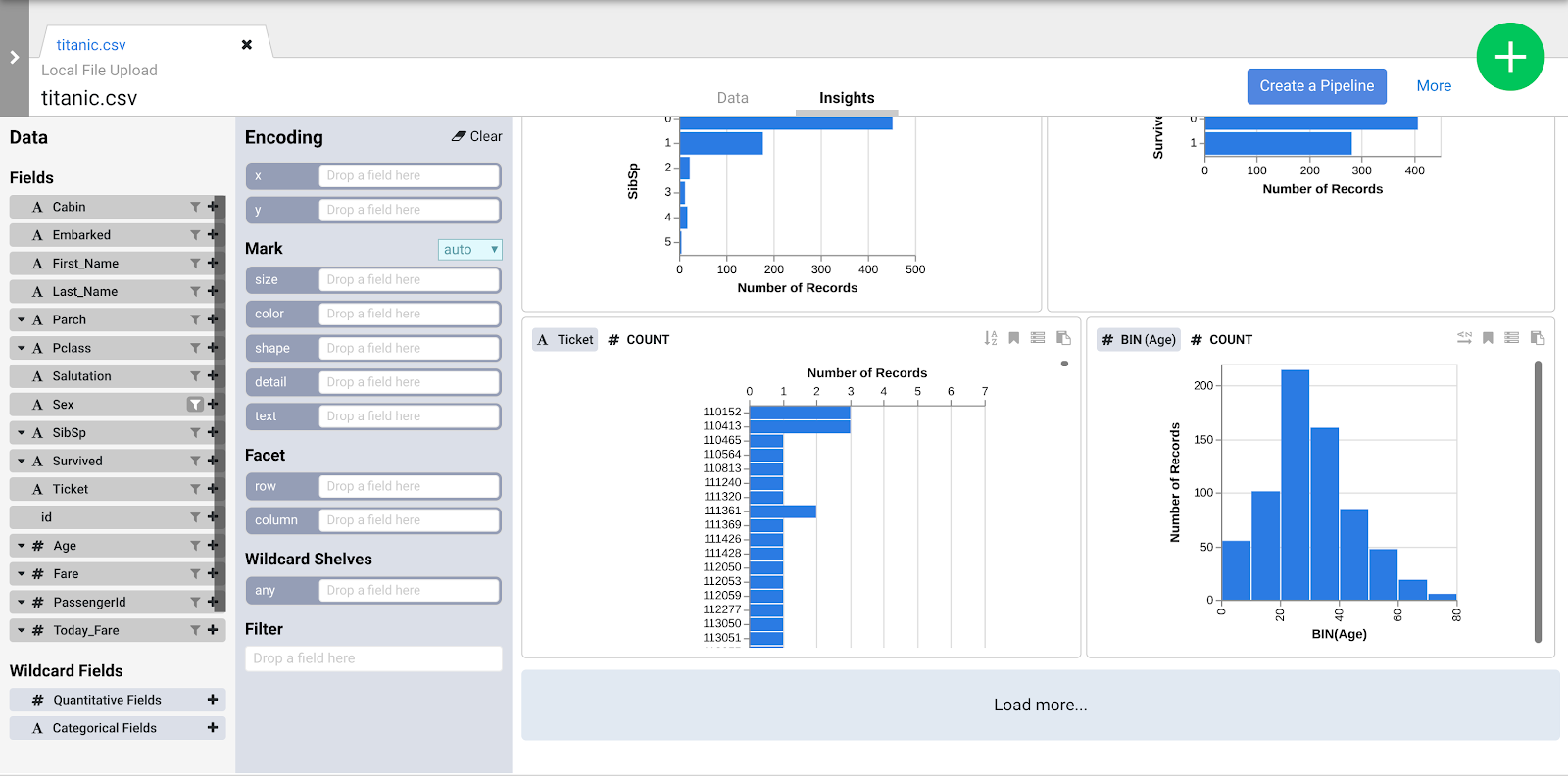
- Machen Sie sich mit der Benutzeroberfläche vertraut, um neue Möglichkeiten zur Datenanalyse zu entdecken. Ziehen Sie das Feld Age per Drag-and-drop in die x-Codierung, um zu sehen, wie sich die Datenperspektiven ändern.
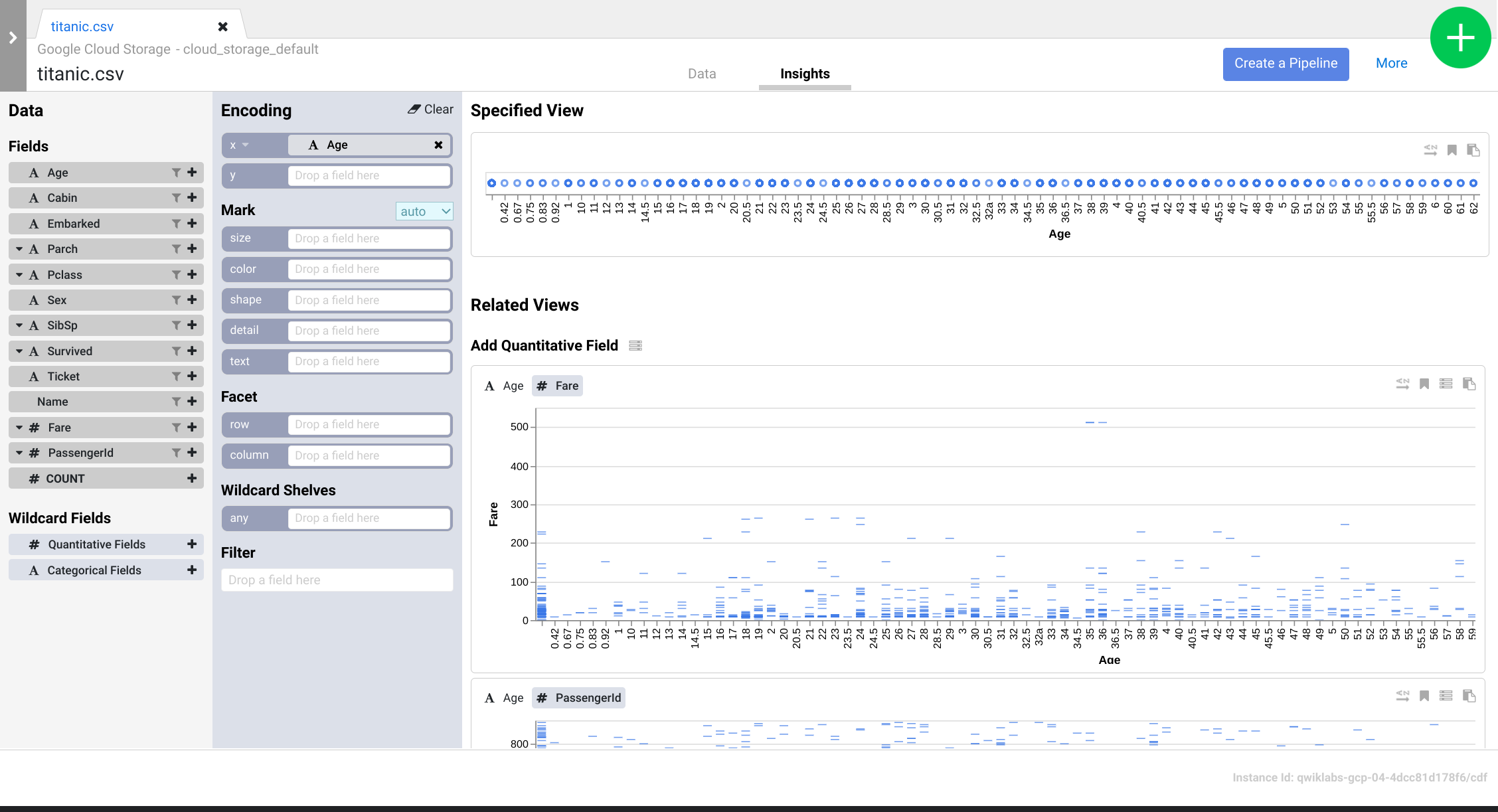
- Klicken Sie auf den Button Pipeline erstellen, um zum Pipeline-Entwicklungsmodus zu wechseln. Dort können Sie die Anweisungen prüfen, die Sie im Wrangler-Plug-in erstellt haben.

- Wählen Sie dann im angezeigten Dialogfeld die Option Batchpipeline aus.
-
Sobald Pipeline Studio geöffnet ist, zeigen Sie auf den Knoten Wrangler und klicken Sie auf Attribute.
-
Sehen Sie sich nach Anweisungen das Schema der Anweisungen an, die Sie zuvor hinzugefügt haben. Im nächsten Abschnitt fügen Sie mit der Befehlszeile weitere Transformationsschritte hinzu.
Aufgabe 5: Mit Transformationsschritten arbeiten
In diesem Abschnitt arbeiten Sie weiter in der Wrangler-Benutzeroberfläche, um das CSV-Dataset zu untersuchen und Transformationen über die Befehlszeile anzuwenden.
-
Klicken Sie im Abschnitt Anweisungen des Felds Attribute Ihres Wrangler-Knotens auf den Button Wrangle. Sie befinden sich wieder in der Wrangler-Benutzeroberfläche.
-
Klicken Sie ganz rechts in der Wrangler-Benutzeroberfläche auf Transformationsschritte, um die Anweisungen aufzurufen. Prüfen Sie, ob Sie derzeit zwei Transformationsschritte haben.
Sie fügen jetzt mit der Befehlszeile weitere Transformationsschritte hinzu und sehen, wie sich die Daten dadurch verändern. Die Befehlszeile ist die schwarze Leiste am unteren Bildschirmrand (mit dem grünen Prompt $).
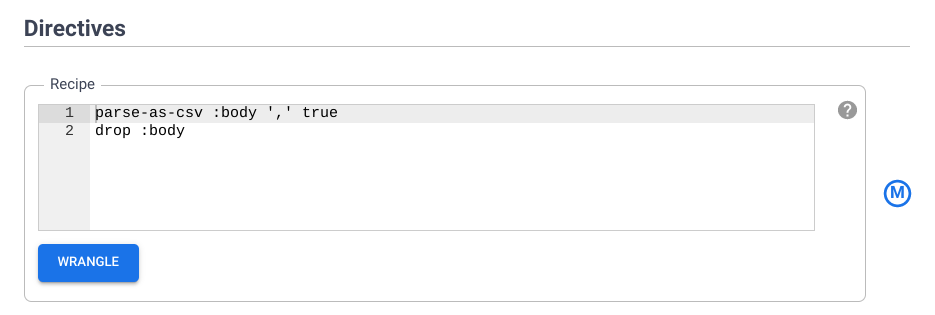
- Kopieren Sie die Anweisungen und fügen Sie sie in die Befehlszeile am Prompt $ ein. Rechts auf dem Bildschirm werden die Transformationsschritte aktualisiert.
fill-null-or-empty :Cabin 'none'
send-to-error empty(Age)
parse-as-csv :Name ',' false
drop Name
fill-null-or-empty :Name_2 'none'
rename Name_1 Last_Name
rename Name_2 First_Name
set-type :PassengerId integer
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125)
set-type :Age integer
set-type :Fare double
set-column Today_Fare (Fare * 23.4058)+1
generate-uuid id
mask-shuffle First_Name
Im Folgenden wird erläutert, wie sich die Anweisungen auf Ihre Daten auswirken. Geben Sie sie NICHT noch einmal in der Befehlszeile ein, da Sie dies gerade schon getan haben.
a. fill-null-or-empty :Cabin 'none' korrigiert die Spalte Cabin, sodass sie vollständig ist.
b. send-to-error empty(Age) korrigiert die Spalte Age, sodass keine leeren Zellen mehr vorhanden sind.
c. parse-as-csv :Name ',' false teilt die Spalte Name in zwei separate Spalten auf, die den Vornamen und den Nachnamen enthalten.
d. rename Name_1 Last_Name und rename Name_2 First_Name benennen die neu erstellten Spalten Name_1 und Name_2 in Last_Name und First_Name um.
e. drop Name entfernt die Spalte Name, da sie nicht mehr benötigt wird.
f. set-type :PassengerId integer konvertiert die Spalte PassengerId in eine Ganzzahl.
g. Die Anweisungen extrahieren die Anrede aus der Spalte „First_Name“, löschen die redundante Spalte und benennen die neu erstellten Spalten entsprechend um:
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
h. Die Anweisung send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125) führt Datenqualitätsprüfungen für die Spalte Age durch, während set-type :Age integer sie als Ganzzahlspalte festlegt.
i. set-type :Fare double konvertiert die Spalte Fare in einen Double-Wert, sodass Sie Berechnungen mit den Spaltenwerten durchführen können.
j. set-column Today_Fare (Fare * 23.4058)+1 multipliziert die Spalte Fare mit der Inflationsrate des Dollars seit 1912, um den angepassten Dollarwert zu erhalten.
k. generate-uuid id erstellt eine Identitätsspalte, um jeden Datensatz eindeutig zu identifizieren.
l. mask-shuffle First_Name maskiert die Spalte Last_Name, um die Person zu de-identifizieren, d. h. personenidentifizierbare Informationen.
-
Klicken Sie oben rechts über den Transformationsschritten auf den Link Mehr und dann auf Schema ansehen, um das von den Transformationen erstellte Schema zu prüfen. Klicken Sie auf das Symbol Herunterladen, um es auf Ihren Computer herunterzuladen.
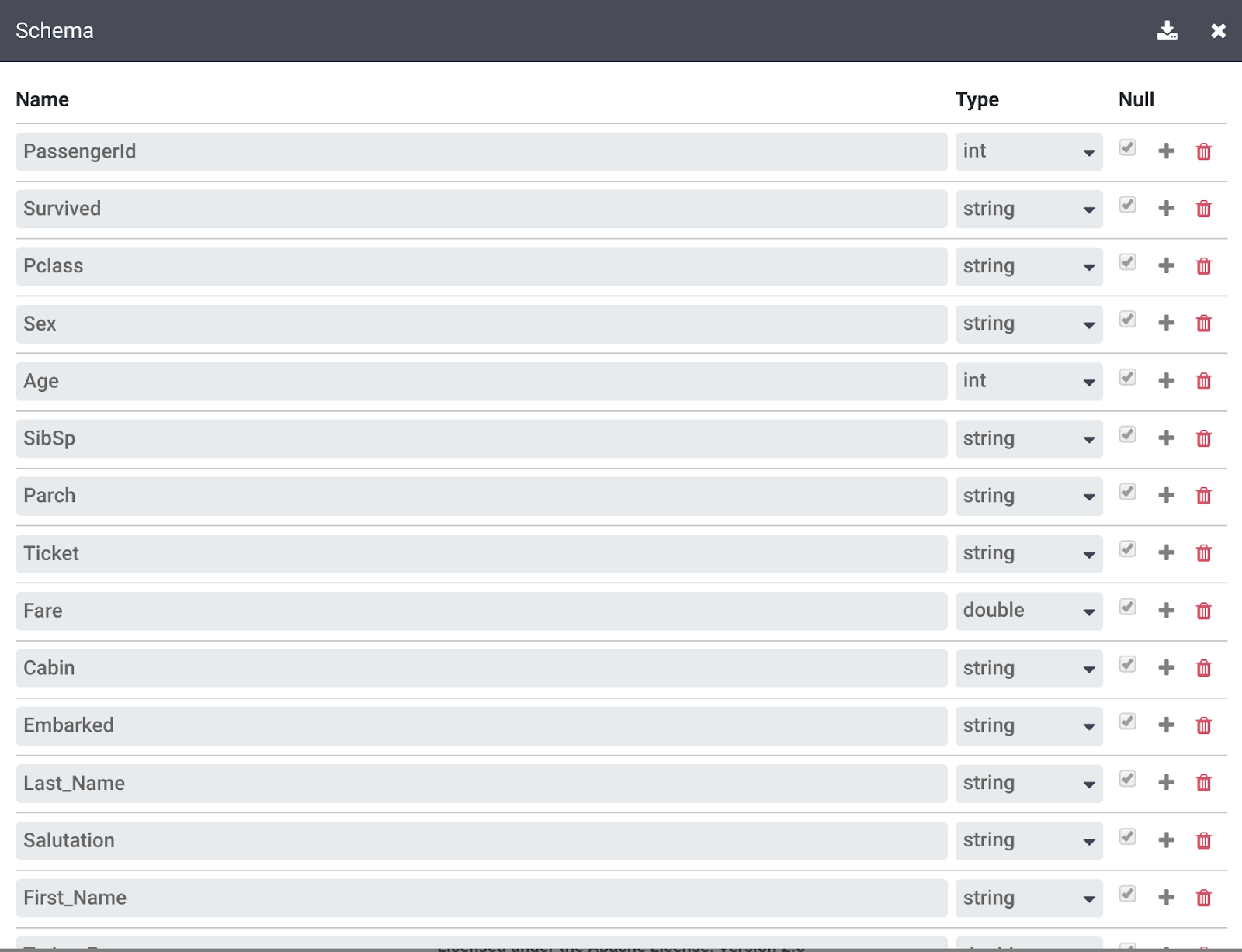
-
Klicken Sie auf X, um die Seite „Schema“ zu schließen.
-
Sie können auf das Symbol Herunterladen unter Transformationsschritte klicken, um das Schema für die Anweisungen auf Ihren Computer herunterzuladen. So haben Sie eine Kopie der Transformationsschritte zur späteren Verwendung.

-
Klicken Sie oben rechts auf den Button Anwenden, damit alle neu eingegebenen Transformationsschritte zur Konfiguration des Wrangler-Knotens hinzugefügt werden. Sie werden dann zurück zum Feld „Attribute“ des Knotens Wrangler geleitet.
-
Klicken Sie zum Schließen auf X. Sie befinden sich wieder im Pipeline Studio.
Aufgabe 6: Aufnahme in BigQuery
Erstellen Sie ein Dataset, um die Daten in BigQuery aufzunehmen.
-
Öffnen Sie BigQuery in der Google Cloud Console in einem neuen Tab oder rechtsklicken Sie auf den Tab der Google Cloud Console und wählen Sie Duplizieren aus. Wählen Sie dann im Navigationsmenü die Option BigQuery aus. Falls Sie dazu aufgefordert werden, klicken Sie auf Fertig.
-
Klicken Sie im Bereich „Explorer“ auf das Symbol Aktionen ansehen neben der Projekt-ID (beginnt mit qwiklabs) und wählen Sie dann Dataset erstellen aus.
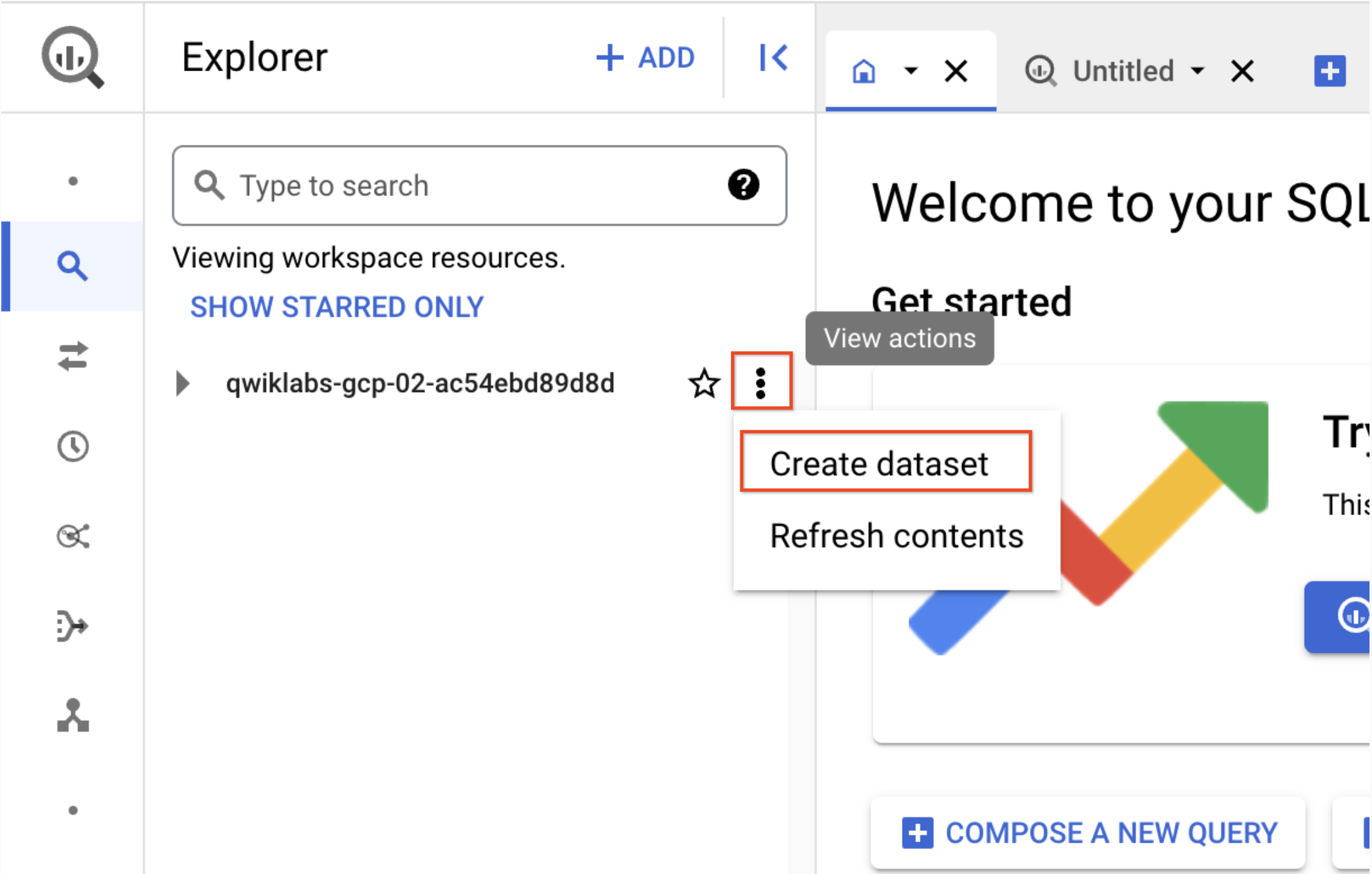
a. Dataset-ID: demo_cdf
b. Klicken Sie auf Dataset erstellen. Notieren Sie sich den Namen, da Sie ihn später im Lab verwenden werden.
- Kehren Sie zum Tab Cloud Data Fusion-UI zurück.
a. Wenn Sie die BigQuery-Senke zur Pipeline hinzufügen möchten, rufen Sie im linken Bereich den Abschnitt Senke auf und klicken Sie auf das Symbol BigQuery, um es auf den Canvas zu platzieren.
b. Sobald die BigQuery-Senke auf dem Canvas platziert wurde, verbinden Sie den Wrangler-Knoten mit dem BigQuery-Knoten. Ziehen Sie dazu den Pfeil vom Wrangler-Knoten zum BigQuery-Knoten (siehe Abbildung).
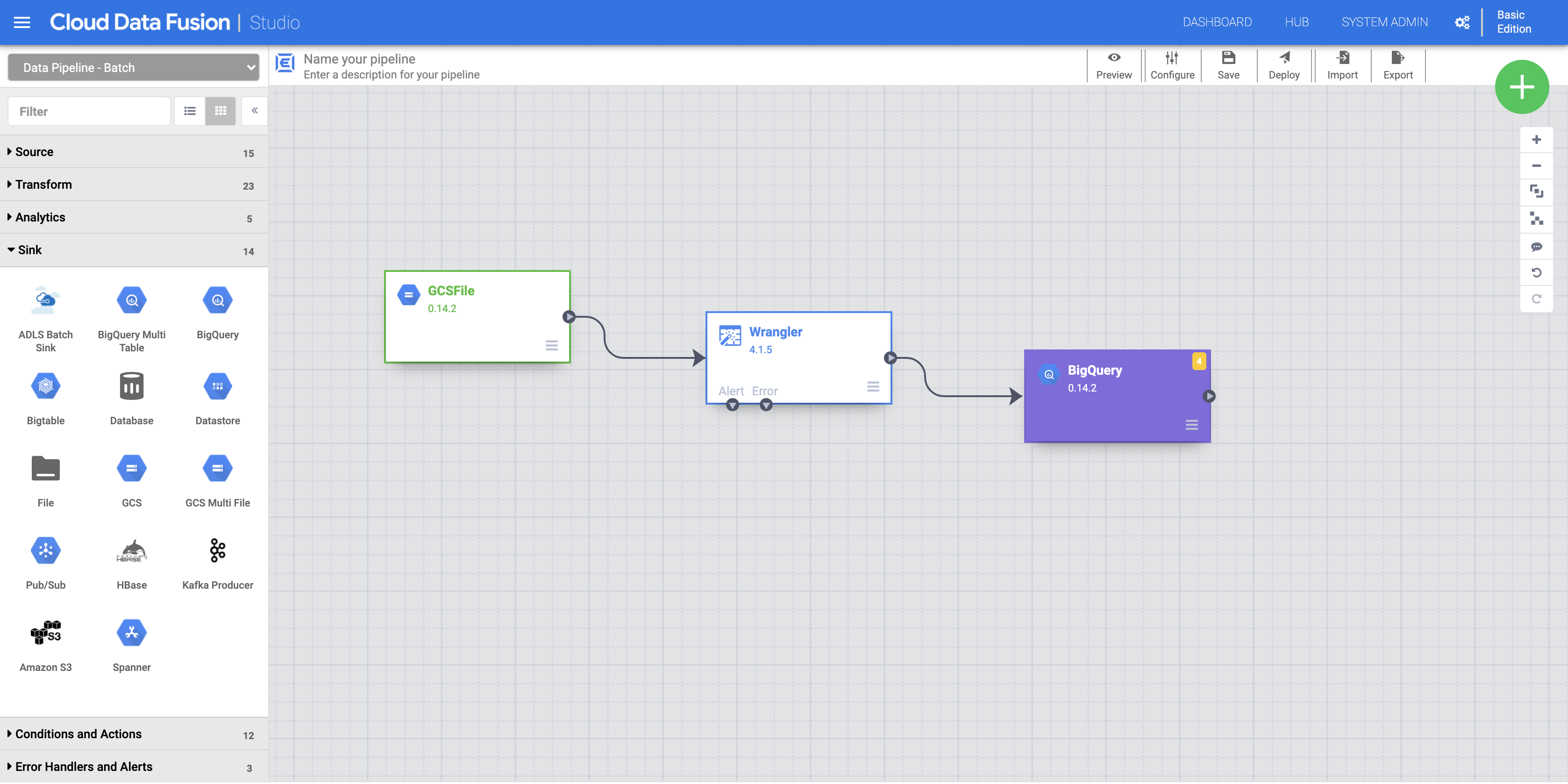
c. Bewegen Sie den Mauszeiger über den BigQuery-Knoten, klicken Sie auf Attribute und geben Sie die folgenden Konfigurationseinstellungen ein:
| Feld |
Wert |
| Referenzname |
DemoSink |
| Dataset-Projekt-ID |
Ihre Projekt-ID
|
| Dataset |
demo_cdf (das Dataset, das Sie im vorherigen Schritt erstellt haben) |
| Tabelle |
Geben Sie einen passenden Namen ein (z. B. titanic). |
Die Tabelle wird automatisch erstellt.
d. Klicken Sie auf den Button Validieren, um zu prüfen, ob alles richtig eingerichtet ist.
e. Klicken Sie zum Schließen auf X. Sie befinden sich wieder im Pipeline Studio.
- Jetzt können Sie Ihre Pipeline ausführen.
a. Geben Sie Ihrer Pipeline einen Namen (z. B. DemoBQ).
b. Klicken Sie auf Speichern und dann oben rechts auf Bereitstellen, um die Pipeline bereitzustellen.
c. Klicken Sie auf Ausführen, um die Pipeline-Ausführung zu starten. Klicken Sie auf das Symbol Zusammenfassung, um sich einige Statistiken anzusehen.
Hinweis: Wenn die Pipeline fehlschlägt, führen Sie sie noch einmal aus.
Nach Abschluss der Ausführung ändert sich der Status in Erfolgreich. Kehren Sie zur BigQuery Console zurück, um die Ergebnisse abzufragen.
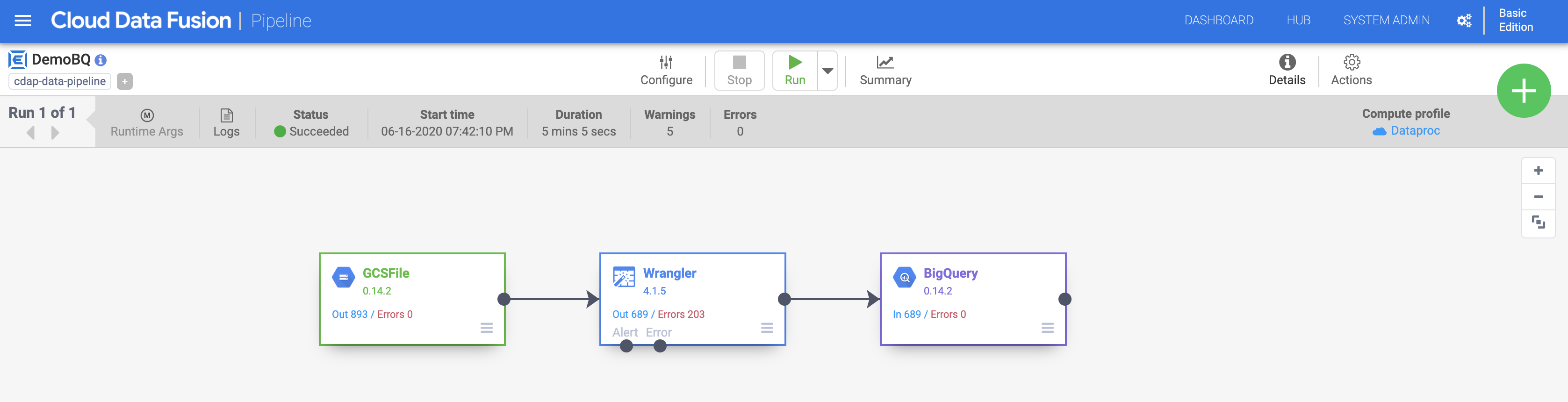
Klicken Sie auf Fortschritt prüfen.
Aufnahme in BigQuery
Glückwunsch!
In diesem Lab haben Sie die Wrangler-Benutzeroberfläche kennengelernt. Sie haben gelernt, wie Sie über das Menü und über die Befehlszeile Transformationsschritte (Anweisungen) hinzufügen. Mit Wrangler können Sie viele leistungsstarke Transformationen iterativ auf Ihre Daten anwenden. Über die Wrangler-Benutzeroberfläche können Sie sehen, wie sich dies auf das Schema Ihrer Daten auswirkt, bevor Sie Ihre Pipeline bereitstellen und ausführen.
Lab beenden
Wenn Sie das Lab abgeschlossen haben, klicken Sie auf Lab beenden. Google Skills entfernt daraufhin die von Ihnen genutzten Ressourcen und bereinigt das Konto.
Anschließend erhalten Sie die Möglichkeit, das Lab zu bewerten. Wählen Sie die entsprechende Anzahl von Sternen aus, schreiben Sie einen Kommentar und klicken Sie anschließend auf Senden.
Die Anzahl der Sterne hat folgende Bedeutung:
- 1 Stern = Sehr unzufrieden
- 2 Sterne = Unzufrieden
- 3 Sterne = Neutral
- 4 Sterne = Zufrieden
- 5 Sterne = Sehr zufrieden
Wenn Sie kein Feedback geben möchten, können Sie das Dialogfeld einfach schließen.
Verwenden Sie für Feedback, Vorschläge oder Korrekturen den Tab Support.
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





