GSP807

Visão geral
ETL significa extrair, transformar e carregar. Há várias outras mutações desse conceito, incluindo EL, ELT e ELTL.
Neste laboratório, você vai aprender a usar o Pipeline Studio no Cloud Data Fusion para criar um pipeline de ETL. O Pipeline Studio expõe os elementos básicos e os plug-ins integrados para que você crie seu pipeline em lote, um nó por vez. Você também vai usar o plug-in Wrangler para criar e aplicar transformações aos dados que passam pelo pipeline.
A fonte de dados mais comum para aplicativos ETL normalmente são dados armazenados em arquivos de texto no formato de valores separados por vírgula (CSV, na sigla em inglês), já que muitos sistemas de banco de dados exportam e importam dados dessa maneira. Para este laboratório, você vai usar um arquivo CSV, mas as mesmas técnicas podem ser aplicadas a fontes de banco de dados e a qualquer outra fonte de dados disponível.
A saída será gravada em uma tabela do BigQuery, e você vai usar o SQL padrão para realizar análises de dados nesse conjunto de dados de destino.
Objetivos
Neste laboratório, você vai aprender a:
- Criar um pipeline em lote com o Pipeline Studio no Cloud Data Fusion.
- Usar o Wrangler para transformar dados de forma interativa.
- Gravar a saída no BigQuery.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Faça login no Google Skills usando uma janela anônima.
-
Verifique o tempo de acesso do laboratório (por exemplo, 02:00:00) para conseguir finalizar todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
-
Quando tudo estiver pronto, clique em Começar o laboratório.
Observação: depois de clicar em Começar o laboratório, o tempo para provisionar os recursos necessários e criar uma instância do Data Fusion é de 15 a 20 minutos.
Enquanto isso, você pode conferir as etapas abaixo para conhecer as metas do laboratório.
Quando as credenciais do laboratório (nome de usuário e senha) aparecem no painel esquerdo, isso significa que a instância foi criada, e você pode continuar o login no console.
-
Anote as credenciais (nome de usuário e senha). É com elas que você vai fazer login no console do Google Cloud.
-
Clique em Abrir console do Google.
-
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Aceite os termos e pule a página de recursos de recuperação.
Observação: não clique em Terminar o laboratório a menos que você tenha concluído as atividades ou queira refazer tudo. Essa opção limpa as ações que você realizou e remove o projeto.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
-
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ( ).
).
-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:

Exemplo de comandos
gcloud auth list
(Saída)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemplo de saída)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Saída)
[core]
project = <project_ID>
(Exemplo de saída)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
-
No Console do Google Cloud, acesse o menu de navegação ( ) e clique em IAM e administrador > IAM.
) e clique em IAM e administrador > IAM.
-
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.

Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
-
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
-
No card Informações do projeto, copie o Número do projeto.
-
No Menu de navegação, clique em IAM e administrador > IAM.
-
Na parte superior da página IAM, clique em Adicionar.
-
Para Novos principais, digite:
{project-number}-compute@developer.gserviceaccount.com
Substitua {project-number} pelo número do seu projeto.
-
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
-
Clique em Salvar.
Tarefa 1: carregar os dados
Nesta tarefa, você vai criar um bucket do Cloud Storage no seu projeto e preparar um arquivo CSV. Depois, o Cloud Data Fusion lê os dados desse bucket de armazenamento.
- No Cloud Shell, execute os seguintes comandos para criar um novo bucket e copiar os dados relevantes para ele:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
O nome do bucket criado é o ID do projeto.
- Para copiar os arquivos de dados (um CSV e um XML) para o bucket, execute o seguinte comando:
gsutil cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Clique em Verificar meu progresso para conferir o objetivo.
Carregar os dados
Tarefa 2: adicionar as permissões necessárias para a instância do Cloud Data Fusion
Nesta tarefa, você vai conceder os papéis do IAM necessários à conta de serviço associada à instância do Cloud Data Fusion.
- No console do Google Cloud, no Menu de navegação, clique em Ver todos os produtos. Nas categorias de Análise de dados, selecione Data Fusion > Instâncias. Você vai ver uma instância do Cloud Data Fusion já configurada e pronta para uso.
Observação: a criação da instância demora em torno de 10 minutos. Aguarde até que ela fique pronta.
-
No Console do Google Cloud, acesse o menu de navegação e clique em IAM e admin > IAM.
-
Localize a conta de serviço padrão do Compute Engine {project-number}-compute@developer.gserviceaccount.com e copie a conta de serviço para a área de transferência.
-
Na página de permissões do IAM, clique em +Conceder acesso.
-
No campo "Novos principais", cole a conta de serviço.
-
Em Selecionar um papel, digite Agente de serviço da API Cloud Data Fusion e selecione essa opção.
-
Clique em + Adicionar outro papel.
-
Em Selecionar papel, escolha Administrador do Managed Service for Spark.
-
Clique em Salvar.
Clique em Verificar meu progresso para conferir o objetivo.
Adicionar um papel de agente de serviço da API Cloud Data Fusion à conta de serviço
Conceder permissão do usuário para a conta de serviço
-
No console, acesse o Menu de navegação e clique em IAM e admin > IAM.
-
Marque a caixa de seleção Incluir concessões do papel fornecidas pelo Google.
-
Role a lista para baixo até encontrar a conta de serviço do Cloud Data Fusion gerenciada pelo Google com esta estrutura: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com e copie o nome da conta de serviço para a área de transferência.

-
Em seguida, acesse IAM e admin > Contas de serviço.
-
Clique na conta padrão do Compute Engine com esta estrutura: {project-number}-compute@developer.gserviceaccount.com. Depois disso, selecione a guia Principais com acesso na parte de cima do menu de navegação.
-
Clique no botão Permitir acesso.
-
No campo Novos principais, cole a conta de serviço que você copiou mais cedo.
-
No menu suspenso Papel, selecione Usuário da conta de serviço.
-
Clique em Salvar.
Tarefa 3: criar um pipeline em lote
Nesta tarefa, você vai usar o componente Wrangler no Cloud Data Fusion para preparar e limpar dados brutos. Esse processo iterativo permite ver as transformações em tempo real.
-
No console do Google Cloud, no Menu de navegação, clique em Data Fusion > Instâncias.
-
Na sua instância, clique em Visualizar instância. Se solicitado, use suas credenciais do laboratório para fazer login. Se o serviço oferecer um tour, clique em Agora não.
-
Na IU do Cloud Data Fusion, no Menu de navegação, clique em Wrangler.
-
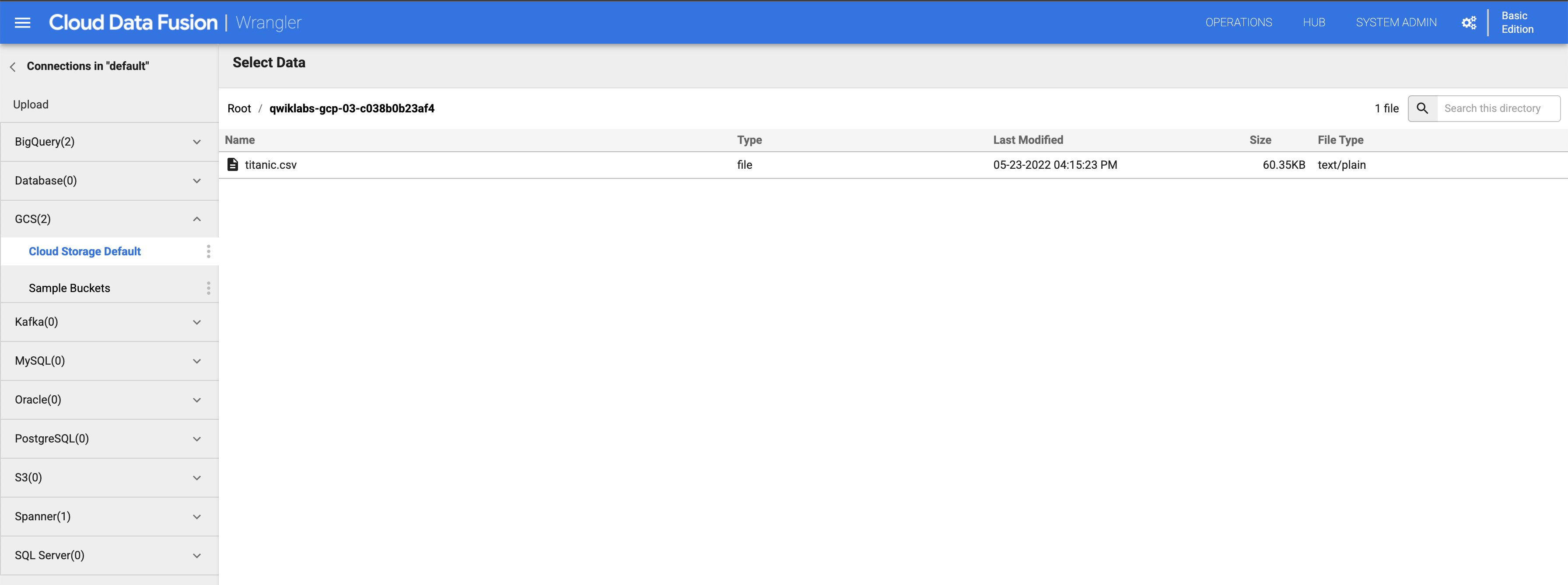
No painel esquerdo, clique em (GCS) Google Cloud Storage e selecione Cloud Storage Default.
-
Clique no bucket que corresponde ao ID do seu projeto.
-
Clique em titanic.csv.
-
Na caixa de diálogo Opções de análise, em Formato, selecione texto e clique em Confirmar.
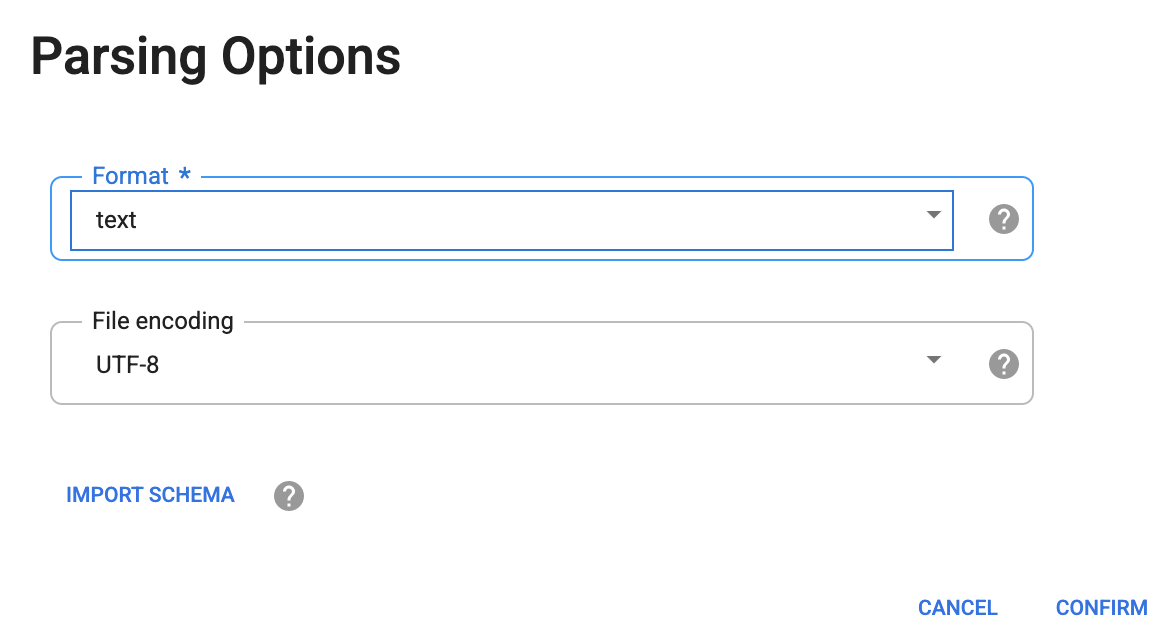
Os dados são carregados na tela do Wrangler. Agora você pode começar a aplicar as transformações de dados de forma iterativa.
-
Para analisar os dados CSV brutos em um formato tabular, clique na seta ao lado do cabeçalho da coluna body, selecione Analisar e, em seguida, CSV.
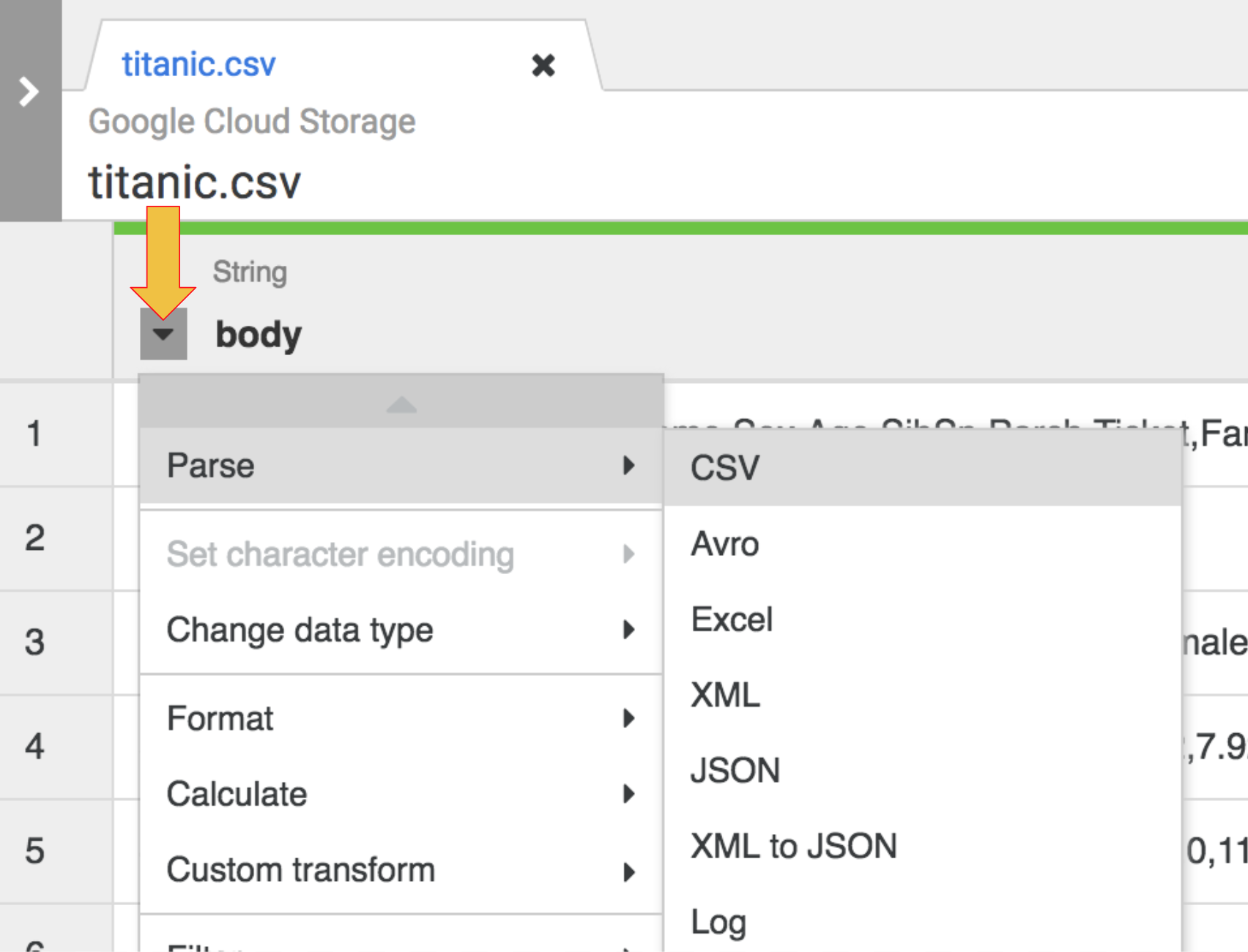
-
Na caixa de diálogo Analisar como CSV, marque a caixa de seleção Definir a primeira linha como cabeçalho e clique em Aplicar.
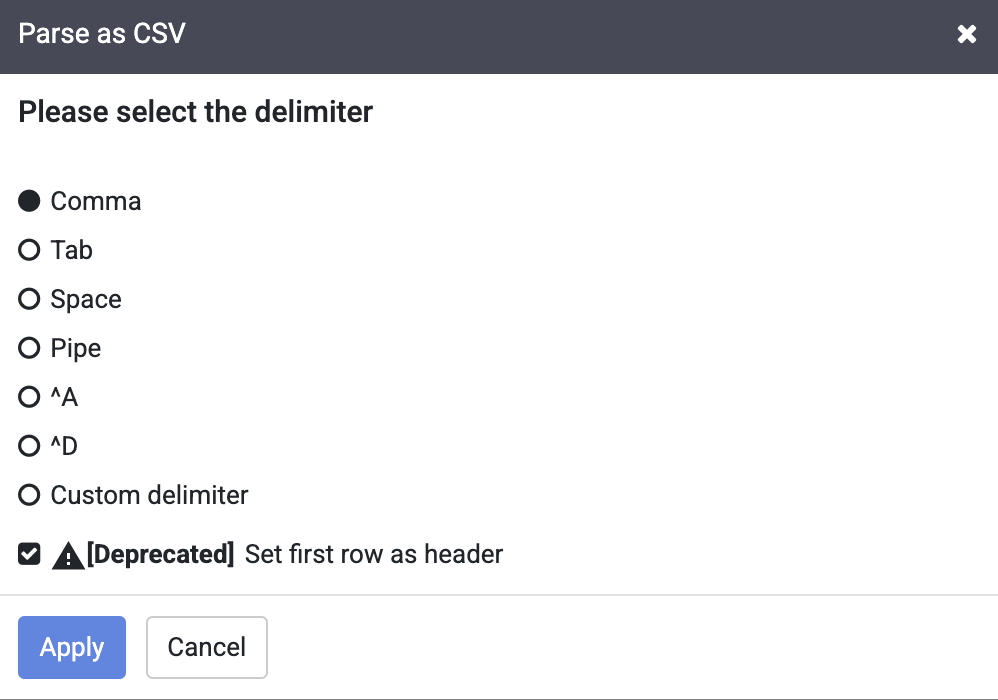
Observação: ignore o aviso de descontinuação ao lado da caixa de seleção Definir a primeira linha como cabeçalho.
- Nessa fase, os dados brutos são analisados. Confira as colunas geradas por essa operação à direita da coluna body. À direita, você vê a lista de todos os nomes de colunas.
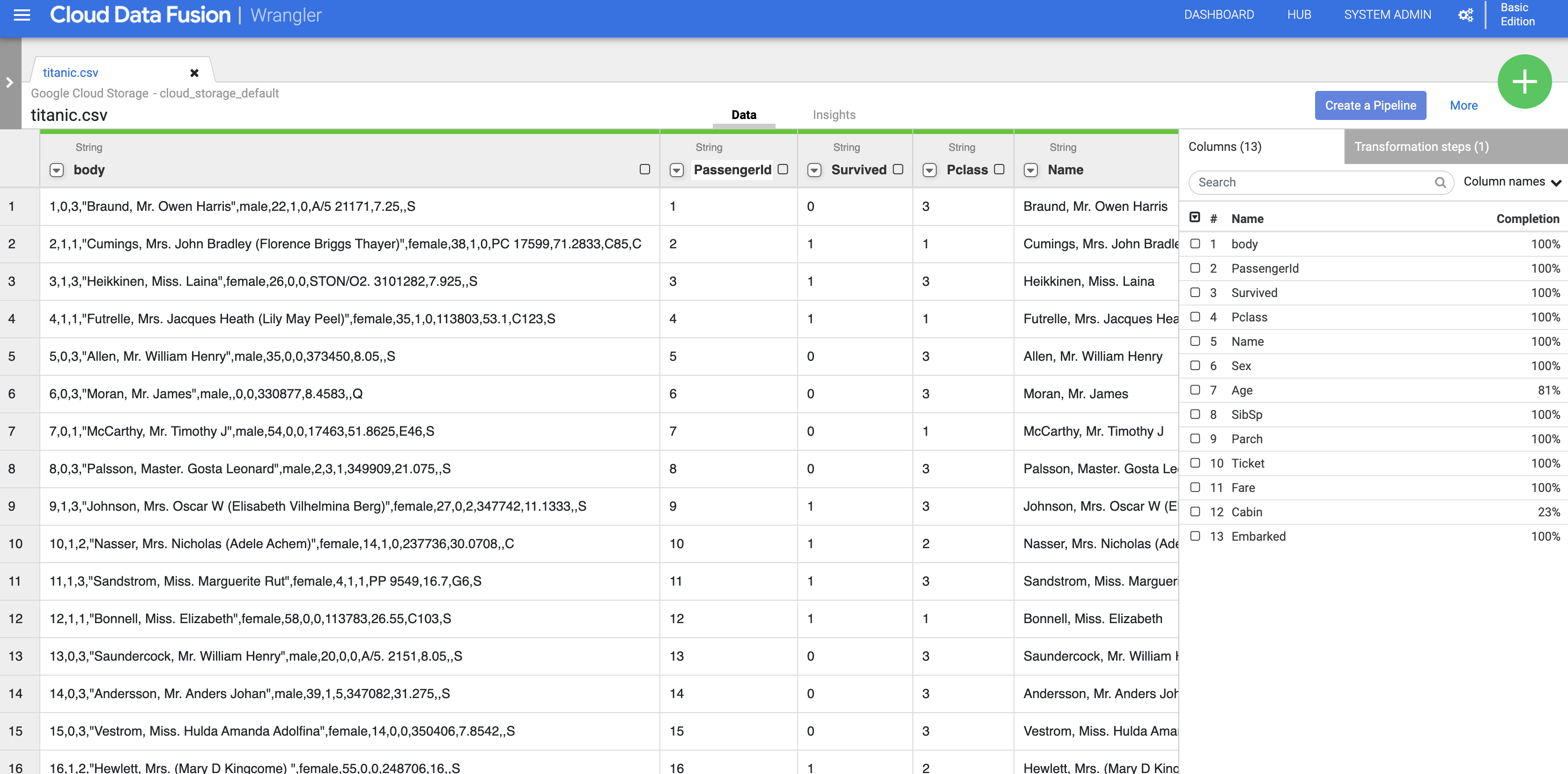
- Para remover a coluna de dados brutos, clique na seta ao lado do cabeçalho da coluna body e depois em Excluir coluna.
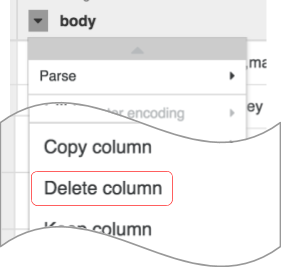
Observação: para aplicar transformações, também é possível usar a interface de linha de comando (CLI, na sigla em inglês). A CLI é a barra preta da parte inferior da tela, com o indicador $ verde. Quando você começa a digitar comandos, o recurso de preenchimento automático é ativado e exibe uma opção correspondente. Por exemplo, para remover a coluna "body", você poderia ter usado a diretiva drop: body.
- No lado direito da interface do Wrangler, clique na guia Etapas de transformação para ver sua receita atual.
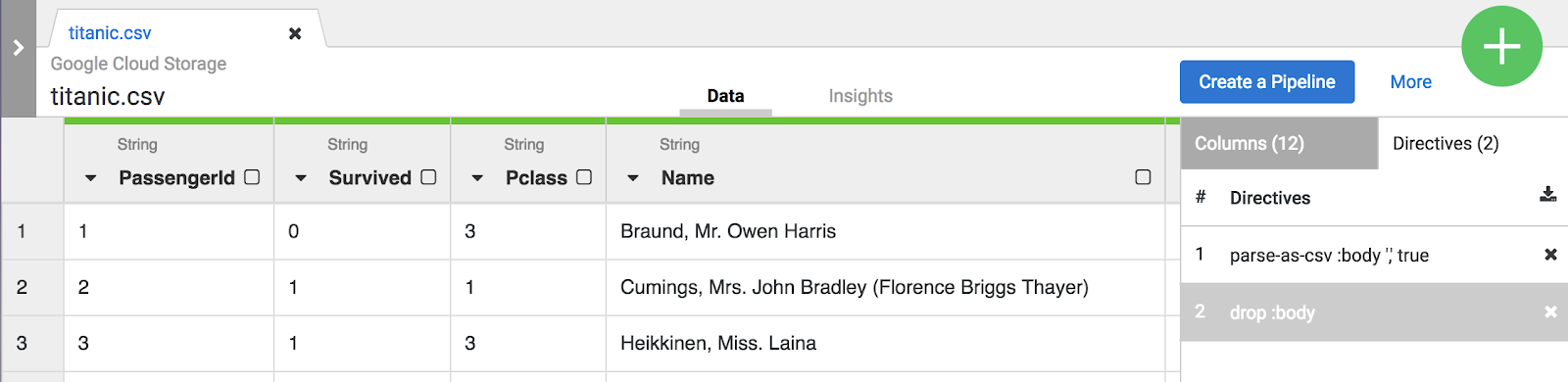
Observação: as seleções de menu e a CLI criam diretivas que ficam visíveis na guia Etapas de transformação
à direita da tela. As diretivas são transformações individuais coletivamente chamadas de roteiro.
Para este laboratório, as duas transformações ou o roteiro são suficientes para criar o pipeline de ETL. A próxima etapa é inserir essa receita em uma etapa de criação de pipeline em que a receita representa o T em ETL.
-
Clique no botão Criar um pipeline para ir para a próxima seção e criar um pipeline. Lá, você vai ver como o pipeline de ETL é montado.

-
Quando a caixa de diálogo for exibida, selecione Pipeline em lote para continuar.
Observação: um pipeline em lote pode ser executado de forma interativa ou programado para ser executado com uma frequência de até 5 minutos ou até uma vez por ano.
Tarefa 4: configurar o coletor do BigQuery
O restante das tarefas de criação do pipeline será realizado no pipeline studio, a interface que permite criar pipelines de dados visualmente. Agora você vai ver os principais blocos de construção do seu pipeline de ETL no estúdio.
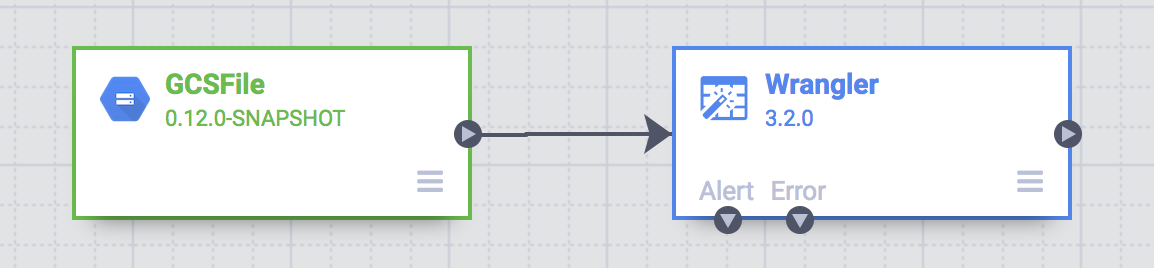
Neste ponto, você vai ver dois nós no pipeline: o plug-in Arquivo do GCS, que vai ler o arquivo CSV do Google Cloud Storage, e o plug-in Wrangler, que contém a receita com as transformações.
Observação: um nó em um pipeline é um objeto conectado em uma sequência para produzir um gráfico acíclico direcionado. Por exemplo, origem, coletor, transformação, ação etc.
Esses dois plug-ins (nós) representam o E e o T no seu pipeline de ETL. Para concluir este pipeline, adicione o coletor do BigQuery, a parte L do nosso ETL.
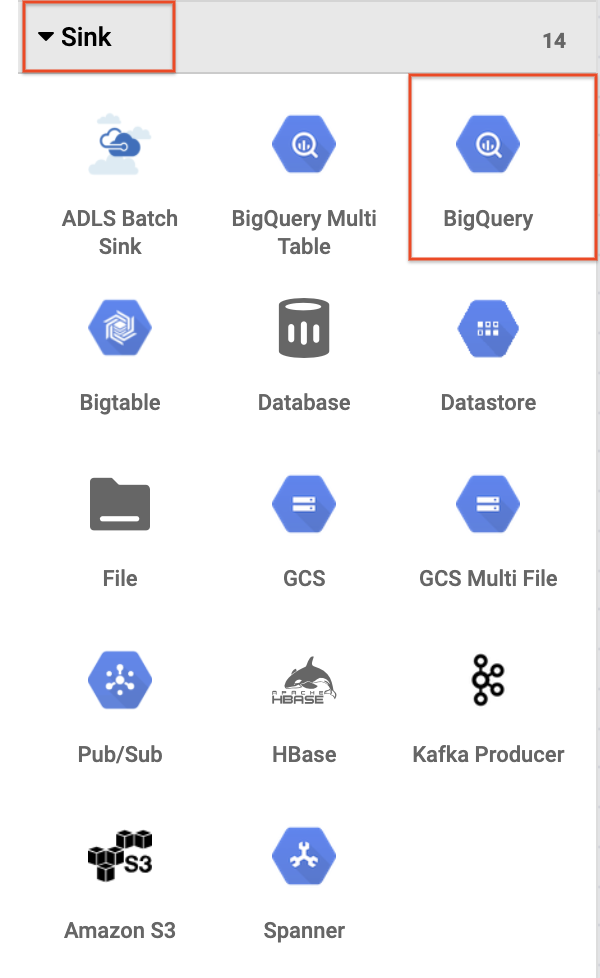
- Para adicionar o coletor do BigQuery ao pipeline, navegue até a seção Coletor no painel esquerdo e clique no ícone do BigQuery para colocá-lo na tela.
-
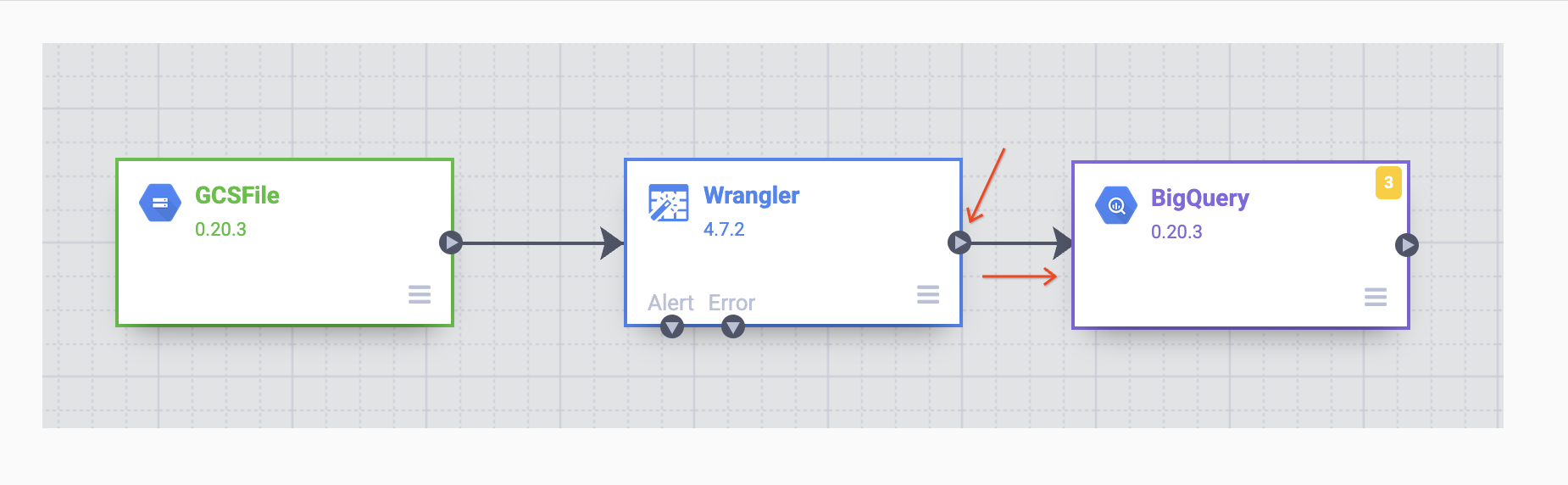
Depois que o coletor do BigQuery for colocado na tela, conecte o nó do Wrangler ao nó do BigQuery. Para isso, arraste a seta do nó do Wrangler para conectar-se ao nó do BigQuery, conforme ilustrado. Agora, basta especificar algumas opções de configuração para gravar os dados no conjunto de dados desejado.
Tarefa 5: configurar o pipeline
Agora é hora de configurar o pipeline. Para fazer isso, abra as propriedades de cada nó para verificar as configurações e/ou fazer outras mudanças.
- Passe o cursor do mouse sobre o nó GCS e um botão Propriedades será exibido. Clique nesse botão para abrir as configurações.
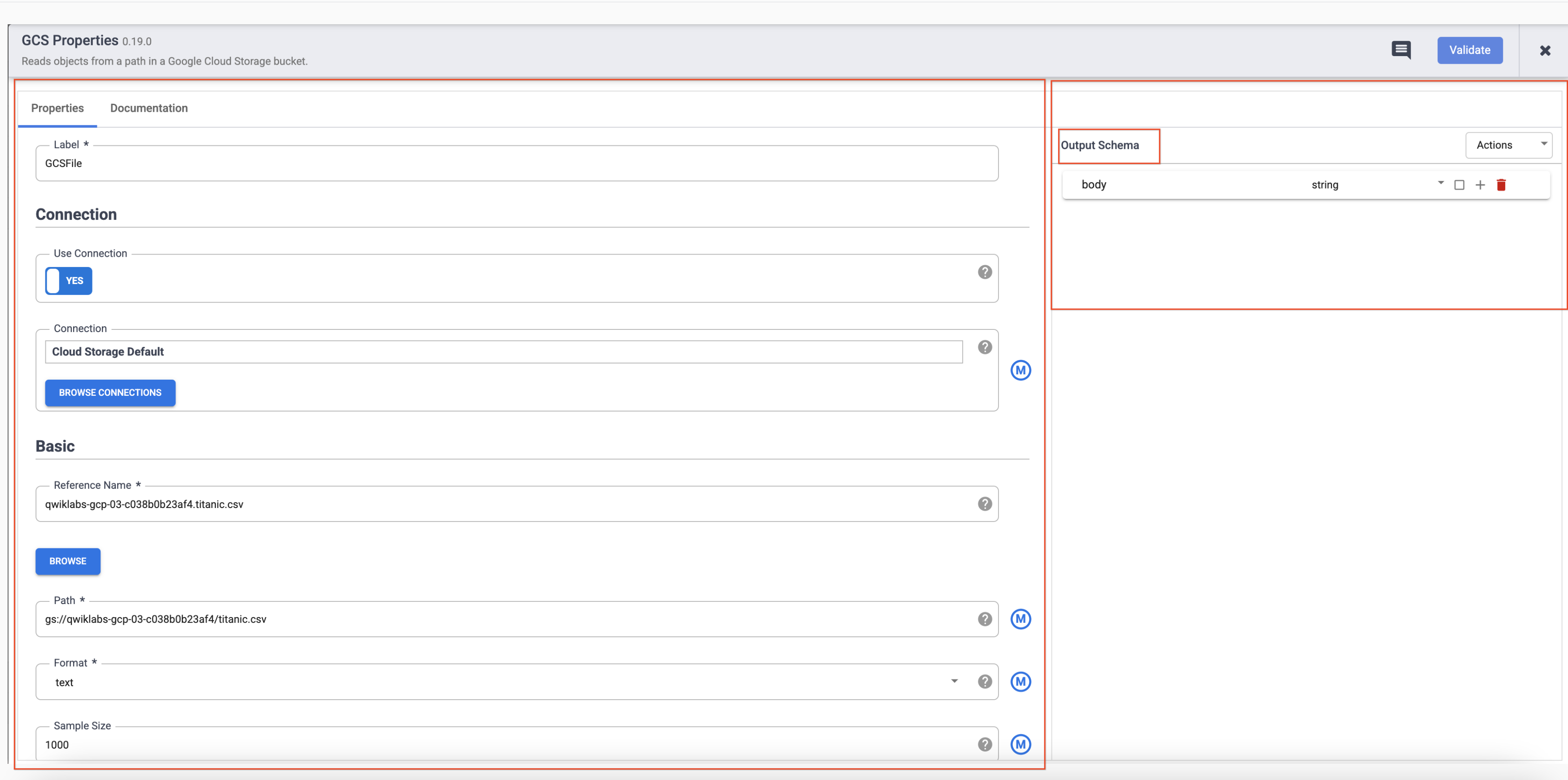
Cada plug-in tem alguns campos obrigatórios que precisam estar presentes e são marcados com um asterisco ( * ). Dependendo do plug-in que você está usando, você pode ver um esquema de entrada à esquerda, uma seção de configuração no meio e um esquema de saída à direita.
Os plug-ins de coletor não têm um esquema de saída e os plug-ins de origem não têm um esquema de entrada. Os plug-ins de coletor e de origem também terão um campo obrigatório Nome de referência para identificar a origem/o coletor de dados para linhagem.
Cada plug-in terá um campo Rótulo. Este é o rótulo do nó que aparece na tela onde seu pipeline é exibido.
-
Clique em X no canto superior direito da caixa "Propriedades" para fechá-la.
-
Em seguida, passe o cursor sobre o nó do Wrangler e clique em Propriedades.
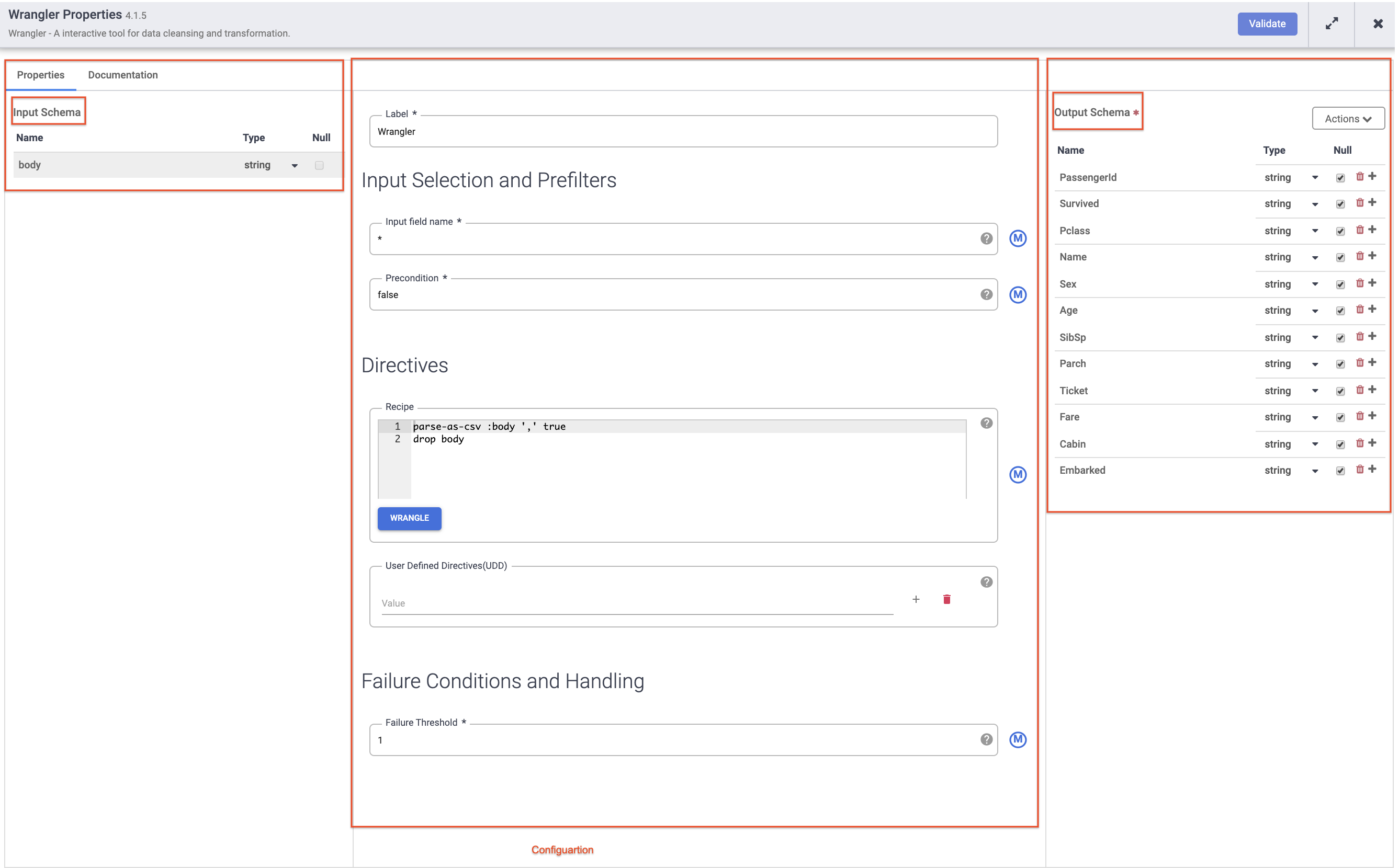
Observação:
plug-ins como o Wrangler que contêm um esquema de entrada. Estes são os campos que estão sendo transmitidos ao plug-in para serem processados. Depois de processados pelo plug-in, os dados de saída podem ser enviados no esquema de saída para o próximo nó no pipeline ou, no caso de um coletor, gravados em um conjunto de dados.
-
Clique em X no canto superior direito da caixa "Propriedades" para fechá-la.
-
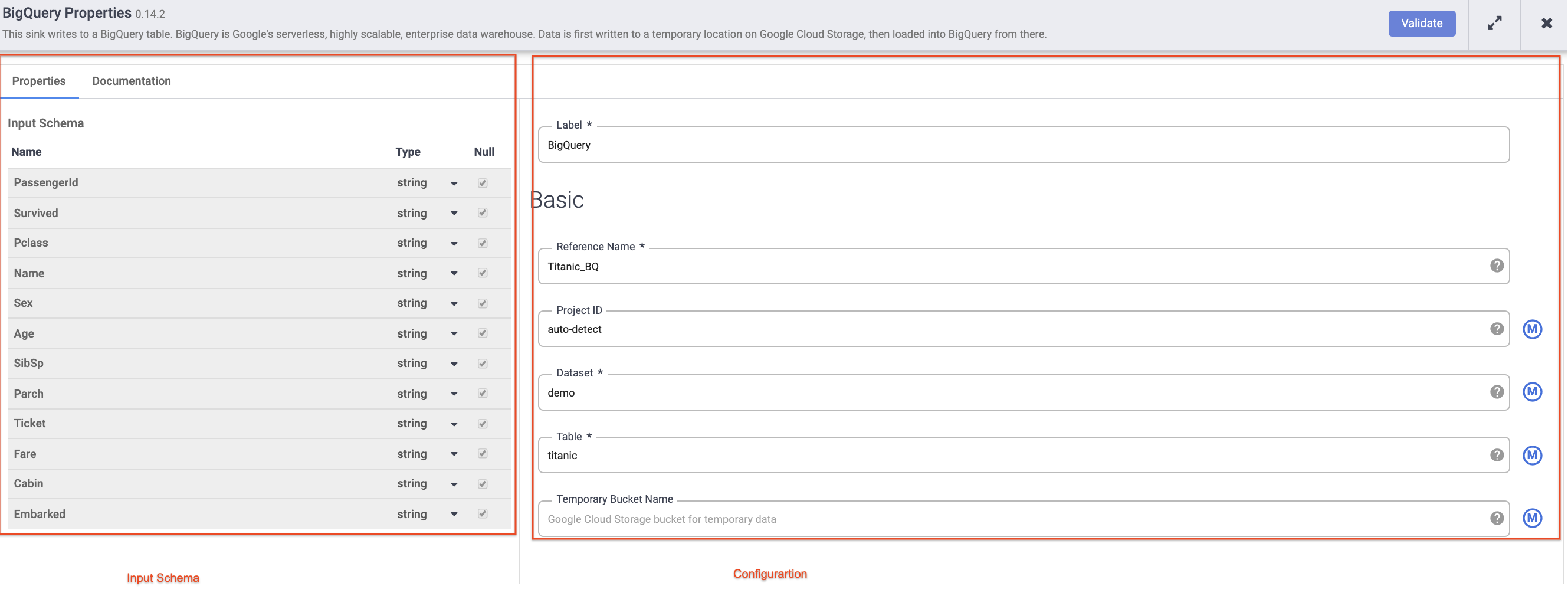
Passe o cursor sobre o nó do BigQuery, clique em Propriedades e insira as seguintes configurações:
-
Em Nome de referência, digite Titanic_BQ.
-
Em Conjunto de dados, insira demo.
-
Em Tabela, insira titanic.
-
Clique em X no canto superior direito da caixa "Propriedades" para fechá-la.
Tarefa 6: testar o pipeline
Agora, tudo o que resta é testar o pipeline para verificar se ele funciona como esperado. Mas antes disso, nomeie e salve o rascunho para não perder seu trabalho.
-
Agora clique em Salvar no menu no canto superior direito. Você vai receber um pedido para dar um Nome e adicionar uma descrição ao pipeline.
- Insira
ETL-batch-pipeline como o nome do seu pipeline.
- Insira
ETL pipeline to parse CSV, transform and write output to BigQuery na descrição.
-
Clique em Salvar.
-
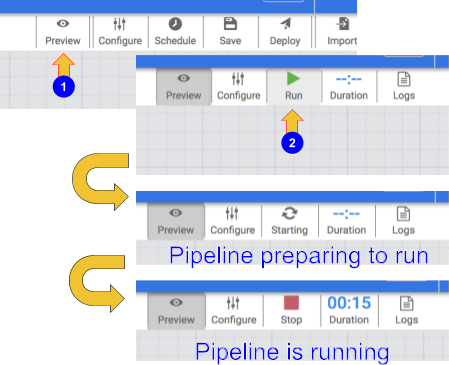
Para testar o pipeline, clique no ícone Visualizar. A barra de botões agora vai mostrar um ícone de execução que você pode clicar para executar o pipeline no modo de visualização.
-
Clique no ícone Executar. Enquanto o pipeline está sendo executado no modo de visualização, nenhum dado é gravado na tabela do BigQuery, mas você poderá confirmar se os dados estão sendo lidos corretamente e se serão gravados conforme o esperado quando o pipeline for implantado. O botão de visualização é um botão de alternância, então clique nele novamente para sair do modo de visualização quando terminar.
-
Quando o pipeline terminar de ser executado, passe o mouse sobre o nó do Wrangler e clique em Propriedades. Em seguida, clique na guia Visualizar. Se tudo der certo, você vai ver os dados brutos que vieram da entrada, o nó à esquerda e os registros analisados que serão emitidos como saída para o nó à direita. Clique em X no canto superior direito da caixa "Propriedades" para fechá-la.
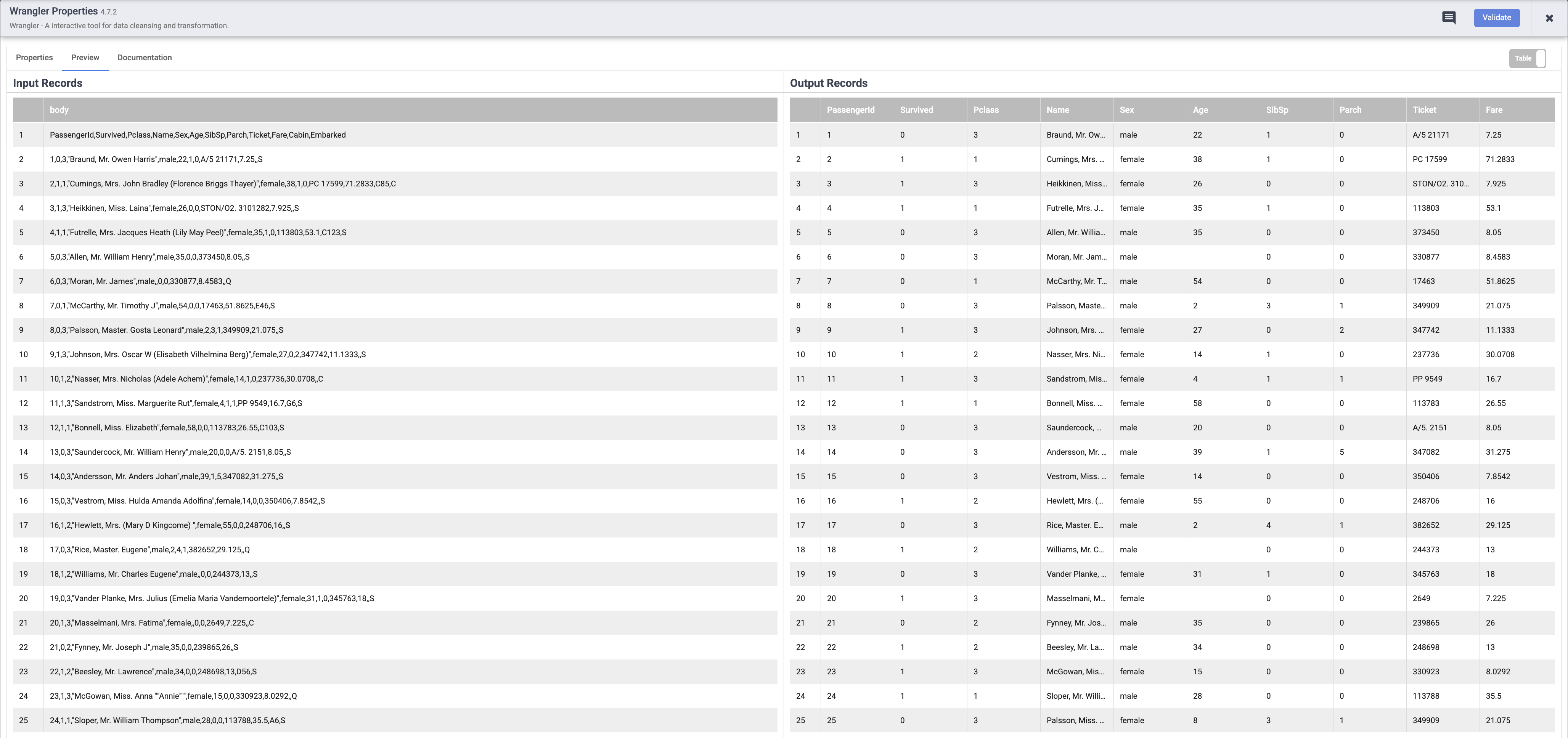
Observação: cada nó que opera nos dados deve mostrar uma saída semelhante. Essa é uma boa maneira de comprovar seu trabalho e garantir que você está no caminho certo antes de implantar o pipeline. Se você encontrar algum erro, poderá corrigi-lo facilmente no modo de rascunho.
-
Clique no ícone Visualizar de novo para sair do modo de visualização.
-
Se tudo estiver certo até agora, você pode prosseguir para implantar o pipeline. Clique no ícone Implantar no canto superior direito  para implantar o pipeline.
para implantar o pipeline.
Você vai ver uma caixa de diálogo de confirmação de que seu pipeline está sendo implantado:
-
Depois que o pipeline for implantado, você poderá executar o pipeline de ETL e carregar alguns dados no BigQuery.
-
Clique no ícone Executar para executar o job de ETL.
-
Quando terminar, o status do pipeline vai mudar para Concluído, indicando que o pipeline foi executado com sucesso.

-
À medida que os dados são processados pelo pipeline, você verá métricas sendo emitidas por cada nó do pipeline indicando quantos registros foram processados.
Na operação de análise, ele mostra 892 registros, enquanto na origem havia 893 registros. O que aconteceu? A operação de análise usou a primeira linha para definir os cabeçalhos das colunas, então os 892 registros restantes foram o que sobrou para processar.

Clique em Verificar meu progresso para conferir o objetivo
Implantar e executar o pipeline em lote
Tarefa 7: conferir os resultados
O pipeline grava a saída em uma tabela do BigQuery. Você pode verificar isso seguindo estas etapas.
-
Em uma nova guia, abra a interface do BigQuery no console do Cloud ou clique com o botão direito do mouse na guia do console, selecione Duplicar e use o Menu de navegação para selecionar BigQuery. Quando solicitado, clique em Concluído.
-
No painel à esquerda, na seção Análises clássicas, clique na ID do projeto (que começa com qwiklabs).
-
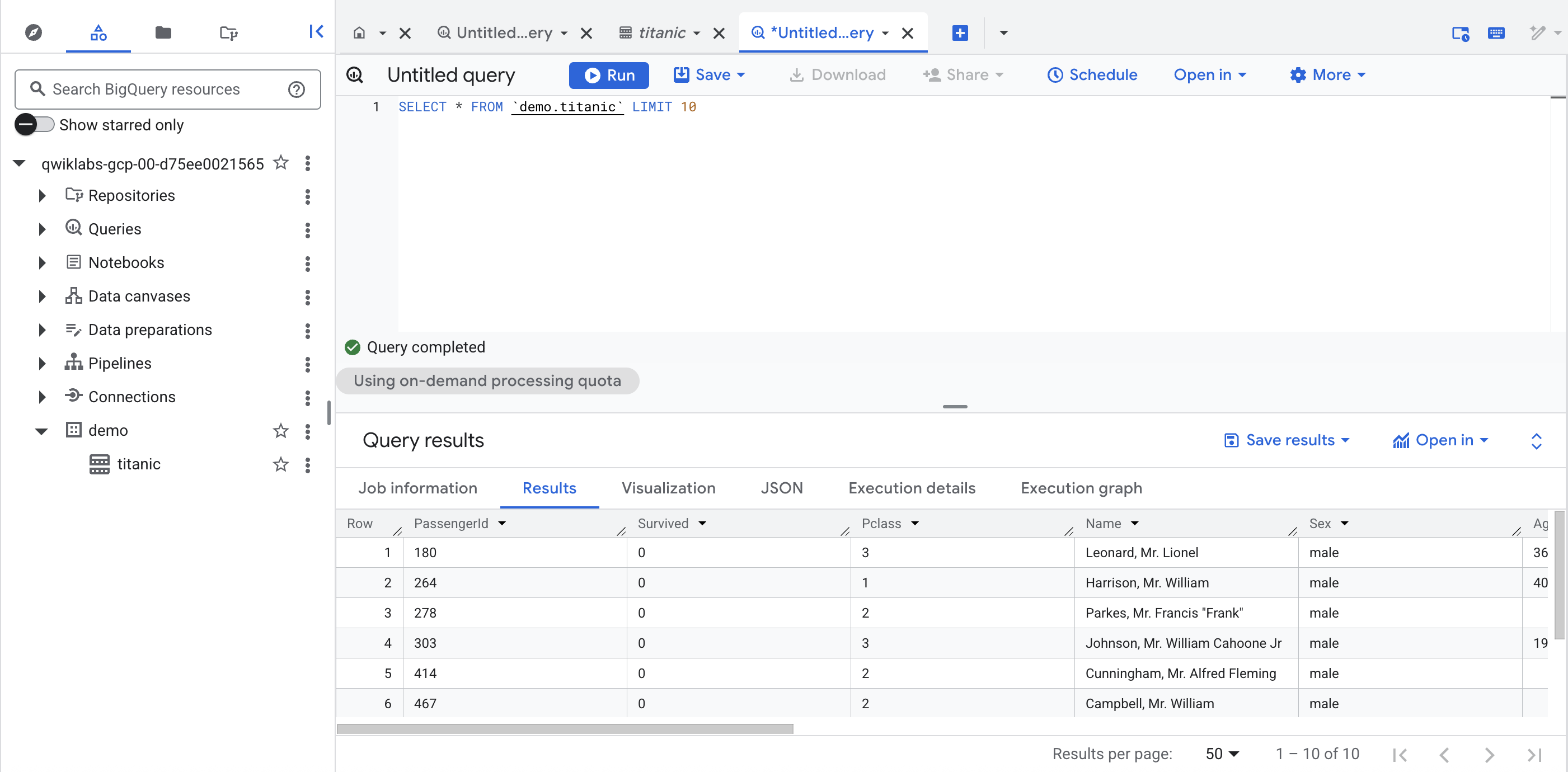
No conjunto de dados demo do projeto, clique na tabela titanic e em + (consulta SQL). Em seguida, execute uma consulta simples, como:
SELECT * FROM `demo.titanic` LIMIT 10
Clique em Verificar meu progresso para conferir o objetivo
Confira os resultados
Parabéns!
Você aprendeu a usar os elementos básicos disponíveis no Pipeline Studio do Cloud Data Fusion para criar um pipeline em lote. Você também aprendeu a usar o Wrangler para criar etapas de transformação para seus dados.
Comece o próximo laboratório
Continue com o módulo Como criar transformações e preparar os dados com o Wrangler no Cloud Data Fusion.
Manual atualizado em 27 de janeiro de 2026
Laboratório testado em 27 de janeiro de 2026
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.





