GSP807

Ringkasan
ETL adalah singkatan dari Extract, Transform, dan Load (Ekstraksi, Transformasi, dan Pemuatan). Ada berbagai variasi lain dari konsep ini, termasuk EL, ELT, dan ELTL.
Lab ini akan mengajarkan cara menggunakan Pipeline Studio di Cloud Data Fusion untuk membangun pipeline ETL. Pipeline Studio mengekspos elemen penyusun dan plugin bawaan agar Anda dapat membangun pipeline batch, satu node dalam satu waktu. Anda juga akan menggunakan plugin Wrangler untuk membangun dan menerapkan transformasi ke data Anda yang melewati pipeline.
Sumber data yang paling umum untuk aplikasi ETL biasanya adalah data yang disimpan dalam file teks berformat comma separated value (CSV), karena banyak sistem database mengekspor dan mengimpor data dengan cara ini. Untuk tujuan lab ini, Anda akan menggunakan file CSV, tetapi teknik yang sama dapat diterapkan ke sumber DB serta sumber data lain yang Anda miliki.
Output akan ditulis ke tabel BigQuery dan Anda akan menggunakan SQL standar untuk melakukan analisis data terhadap set data target ini.
Tujuan
Di lab ini, Anda akan mempelajari cara:
- Membuat pipeline batch dengan Pipeline Studio di Cloud Data Fusion.
- Menggunakan Wrangler untuk mentransformasi data secara interaktif.
- Menulis output ke BigQuery.
Penyiapan dan persyaratan
Untuk setiap lab, Anda akan memperoleh project Google Cloud baru serta serangkaian resource selama jangka waktu tertentu, tanpa biaya.
-
Login ke Google Skills menggunakan jendela samaran.
-
Perhatikan waktu akses lab (misalnya, 02:00:00), dan pastikan Anda dapat menyelesaikannya dalam waktu tersebut.
Tidak ada fitur jeda. Bila perlu, Anda dapat memulai ulang lab, tetapi Anda harus memulai dari awal.
-
Jika sudah siap, klik Start lab.
Catatan: Setelah Anda mengklik Start lab, perlu waktu sekitar 15 - 20 menit agar resource yang diperlukan disediakan dan instance Data Fusion dibuat.
Selama waktu ini, Anda dapat membaca langkah-langkah di bawah untuk mengetahui sasaran lab.
Jika Anda melihat kredensial lab (Nama pengguna dan Sandi) di panel kiri, artinya instance telah dibuat dan Anda dapat melanjutkan dengan login ke konsol.
-
Catat kredensial lab (Nama pengguna dan Sandi) Anda. Anda akan menggunakannya untuk login ke Konsol Google Cloud.
-
Klik Open Google console.
-
Klik Use another account, lalu salin/tempel kredensial lab ini ke perintah yang muncul.
Jika menggunakan kredensial lain, Anda akan menerima pesan error atau dikenai biaya.
-
Setujui ketentuan dan lewati halaman resource pemulihan.
Catatan: Jangan klik End lab kecuali Anda sudah menyelesaikan lab atau ingin mengulanginya. Tindakan ini akan membersihkan pekerjaan Anda dan menghapus project.
Login ke Konsol Google Cloud.
- Dengan menggunakan tab atau jendela browser yang Anda gunakan untuk sesi lab ini, salin Username dari panel Connection Details, lalu klik tombol Open Google Console.
Catatan: Jika Anda diminta untuk memilih akun, klik Use another account.
- Tempel Username, lalu Password saat diminta.
- Klik Next.
- Setujui persyaratan dan ketentuan.
Karena ini adalah akun sementara yang hanya akan berlaku selama penggunaan lab ini, Anda disarankan untuk:
- Tidak menambahkan opsi pemulihan
- Tidak mendaftar ke uji coba gratis
- Setelah konsol terbuka, lihat daftar layanan dengan mengklik Navigation menu (
 ) di kiri atas.
) di kiri atas.

Mengaktifkan Cloud Shell
Cloud Shell adalah mesin virtual dengan beberapa alat pengembangan. Mesin virtual ini menawarkan direktori beranda persisten berkapasitas 5 GB dan berjalan di Google Cloud. Cloud Shell memberikan akses command line ke resource Google Cloud Anda. gcloud adalah alat command line untuk Google Cloud. Fitur ini sudah terinstal di Cloud Shell dan mendukung penyelesaian tab.
-
Di Google Cloud Console, pada panel navigasi, klik Activate Cloud Shell ( ).
).
-
Klik Continue.
Perlu waktu beberapa saat untuk menyediakan dan menghubungkan ke lingkungan. Setelah terhubung, Anda juga diautentikasi, dan project ditetapkan ke PROJECT_ID Anda. Contoh:

Contoh perintah
gcloud auth list
(Output)
Akun berkredensial:
- <myaccount>@<mydomain>.com (active)
(Contoh output)
Akun berkredensial:
- google1623327_student@qwiklabs.net
gcloud config list project
(Output)
[core]
project = <project_ID>
(Contoh output)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Memeriksa izin project
Sebelum mulai bekerja di Google Cloud, Anda harus memastikan project Anda memiliki izin yang tepat dalam Identity and Access Management (IAM).
-
Di Konsol Google Cloud, pada Navigation menu (), klik IAM & Admin > IAM.
-
Pastikan Akun Layanan komputasi default {project-number}-compute@developer.gserviceaccount.com tersedia dan peran editor telah ditetapkan. Prefiks akun adalah nomor project yang dapat Anda temukan di Navigation menu > Cloud overview.

Jika akun tersebut tidak ada di IAM atau tidak memiliki peran editor, ikuti langkah-langkah di bawah untuk menetapkan peran yang diperlukan.
-
Di Konsol Google Cloud, pada Navigation menu, klik Cloud overview.
-
Dari kartu Project info, salin Project number.
-
Pada Navigation menu, klik IAM & Admin > IAM.
-
Di bagian atas halaman IAM, klik Add.
-
Untuk New principals, ketik:
{project-number}-compute@developer.gserviceaccount.com
Ganti {project-number} dengan nomor project Anda.
-
Untuk Select a role, pilih Basic (atau Project) > Editor.
-
Klik Save.
Tugas 1. Memuat data
Dalam tugas ini, Anda akan membuat bucket Cloud Storage di project Anda dan menyiapkan file CSV. Cloud Data Fusion nanti akan membaca data dari bucket penyimpanan ini.
- Di Cloud Shell, jalankan perintah berikut untuk membuat bucket baru dan menyalin data yang relevan ke dalamnya:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
Nama bucket yang dibuat adalah Project ID Anda.
- Untuk menyalin file data (file CSV dan XML) ke bucket Anda, jalankan perintah berikut:
gsutil cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Klik Periksa progres saya untuk memverifikasi tujuan.
Memuat data
Tugas 2. Menambahkan izin yang diperlukan untuk instance Cloud Data Fusion Anda
Dalam tugas ini, Anda akan memberikan peran IAM yang diperlukan ke akun layanan yang terkait dengan instance Cloud Data Fusion.
- Di Konsol Google Cloud, pada Navigation menu, klik View All Products, dari Kategori Analytics, lalu pilih Data Fusion > Instances. Anda akan melihat instance Cloud Data Fusion yang sudah disiapkan dan siap digunakan.
Catatan: Pembuatan instance memerlukan waktu sekitar 10 menit. Harap tunggu sampai prosesnya selesai.
-
Di Konsol Google Cloud, pada Navigation menu, klik IAM & Admin > IAM.
-
Temukan akun layanan default Compute Engine {project-number}-compute@developer.gserviceaccount.com, lalu salin Akun Layanan tersebut ke papan klip Anda.
-
Di halaman IAM, klik +Grant Access.
-
Di kolom New principals, tempel akun layanan.
-
Untuk Select a role, ketik Cloud Data Fusion API Service Agent, lalu pilih opsi tersebut.
-
Klik + Add another role.
-
Untuk Select a role, pilih peran Dataproc Administrator.
-
Klik Save.
Klik Periksa progres saya untuk memverifikasi tujuan.
Menambahkan peran Agen Layanan Cloud Data Fusion API ke akun layanan
Memberikan izin pengguna kepada akun layanan
-
Di konsol, pada Navigation menu, klik IAM & admin > IAM.
-
Pilih kotak centang Include Google-provided role grants.
-
Scroll ke bawah dalam daftar untuk menemukan akun layanan Cloud Data Fusion yang dikelola Google yang terlihat seperti service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com, lalu salin nama akun layanan tersebut ke papan klip Anda.

-
Selanjutnya, buka IAM & admin > Service Accounts.
-
Klik akun compute engine default yang terlihat seperti {project-number}-compute@developer.gserviceaccount.com, lalu pilih tab Principals with access di menu navigasi bagian atas.
-
Klik tombol Grant Access.
-
Di kolom New Principals, tempel akun layanan yang telah Anda salin sebelumnya.
-
Pada menu dropdown Role, pilih Service Account User.
-
Klik Save.
Tugas 3. Membangun pipeline batch
Dalam tugas ini, Anda akan menggunakan komponen Wrangler di Cloud Data Fusion untuk menyiapkan dan membersihkan data mentah. Proses iteratif ini membantu Anda memvisualisasikan transformasi secara real time.
-
Di Konsol Google Cloud, pada Navigation menu, klik Data Fusion > Instances.
-
Untuk instance Anda, klik View Instance. Jika diminta, gunakan kredensial lab Anda untuk login. Jika diminta untuk mengikuti tur, klik No, Thanks.
-
Di UI Cloud Data Fusion, pada Navigation menu, klik Wrangler.
-
Di panel kiri, klik (GCS) Google Cloud Storage, lalu pilih Cloud Storage Default.
-
Klik bucket yang sesuai dengan project ID Anda.
-
Klik titanic.csv.
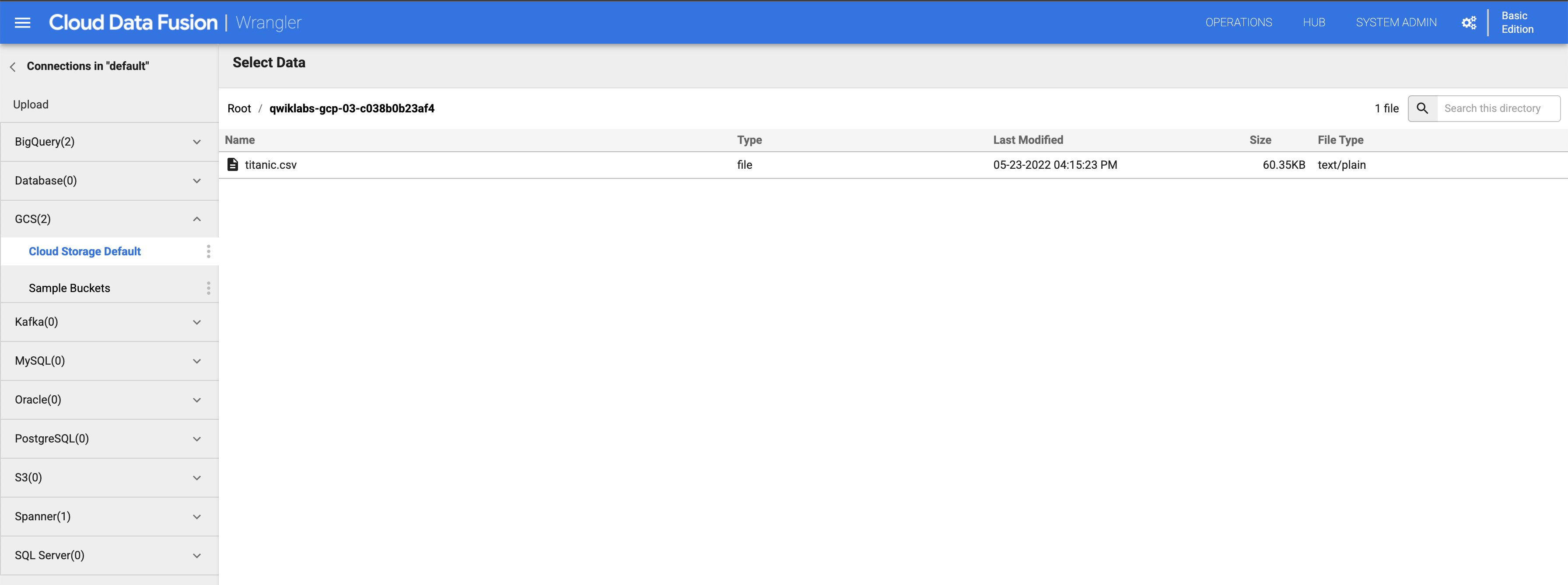
-
Di kotak dialog Parsing Options, untuk Format, pilih text, lalu klik Confirm.
Data akan dimuat ke layar Wrangler. Sekarang Anda dapat mulai menerapkan transformasi data secara iteratif.
-
Untuk mengurai data CSV mentah ke dalam format tabel, klik arrow di samping judul kolom body, pilih Parse, lalu pilih CSV.
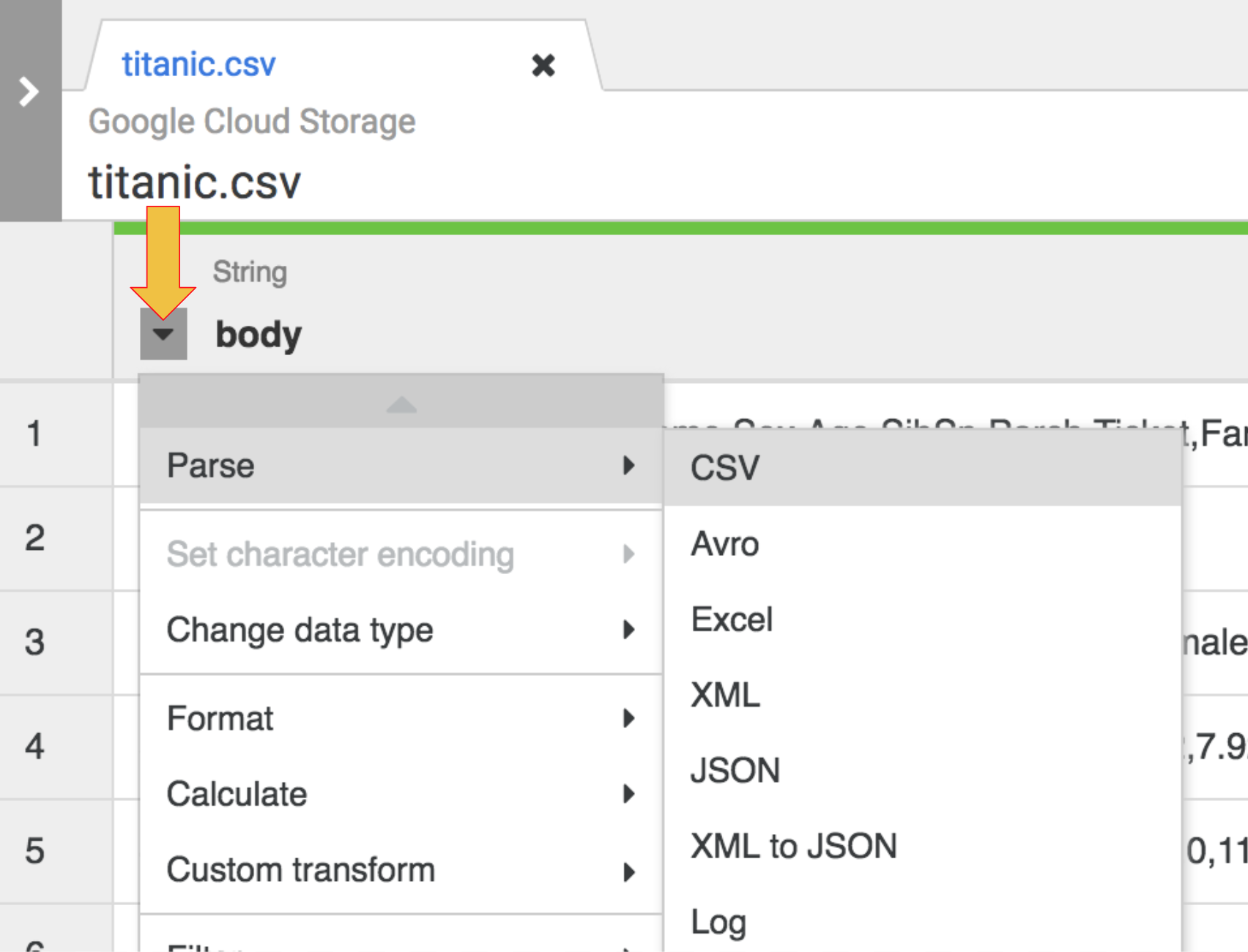
-
Di kotak dialog Parse as CSV dialog, centang kotak Set first row as header, lalu klik Apply.
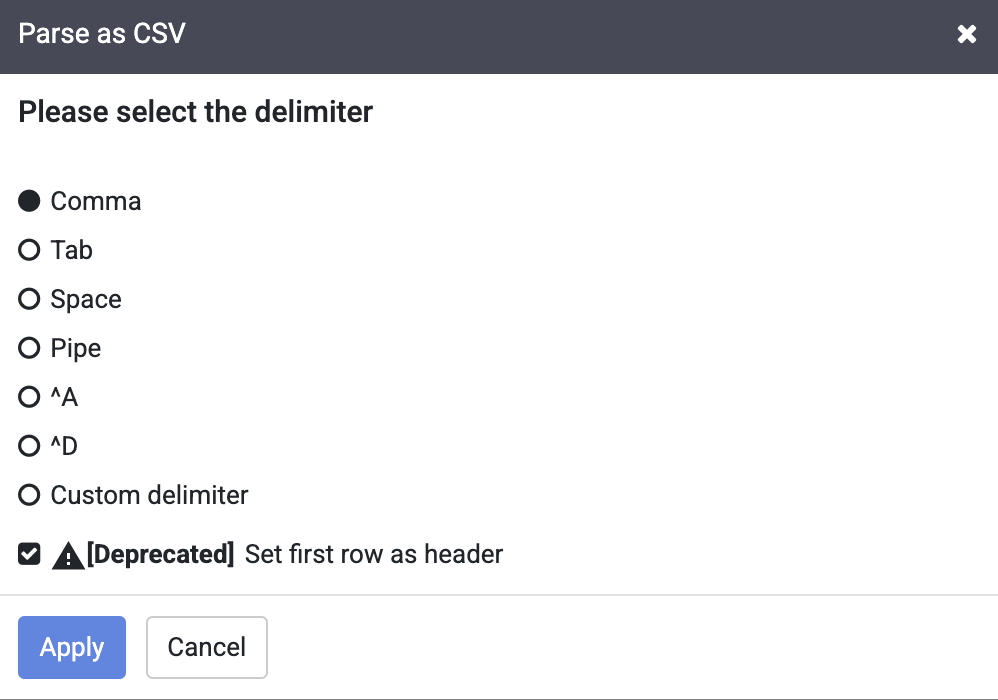
Catatan: Anda dapat mengabaikan peringatan deprecation di samping kotak centang Set first row as header.
- Di tahap ini, data mentah akan diuraikan dan Anda dapat melihat kolom yang dihasilkan oleh operasi ini (kolom di sebelah kanan kolom body). Di sisi paling kanan, Anda akan melihat daftar semua nama kolom.
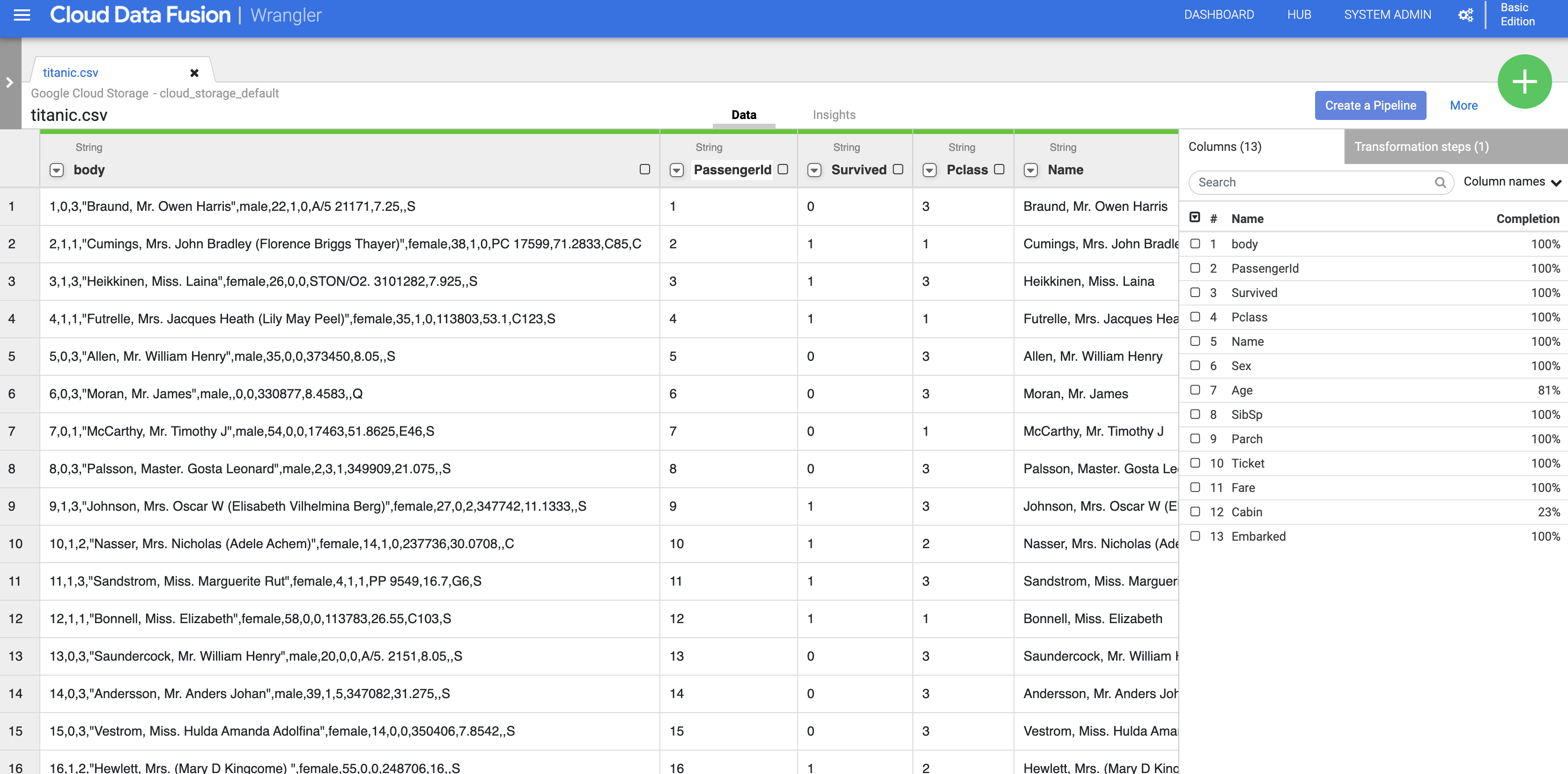
- Untuk menghapus kolom data mentah, klik arrow di samping judul kolom body, lalu klik Delete column.
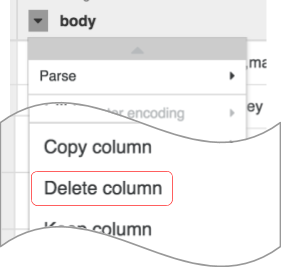
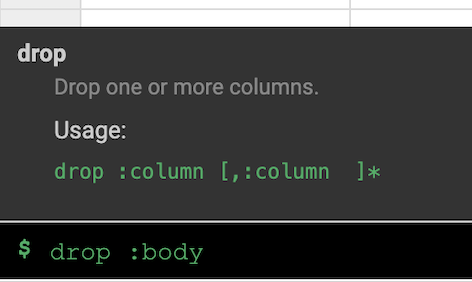
Catatan: Untuk menerapkan transformasi, Anda juga dapat menggunakan antarmuka command line (CLI). CLI adalah kolom hitam di bagian bawah layar (dengan perintah $ berwarna hijau). Saat Anda mulai mengetikkan perintah, fitur isi otomatis akan aktif dan menampilkan opsi yang cocok. Misalnya, untuk menghapus kolom body, Anda dapat menggunakan perintah: drop :body.
- Di sisi kanan UI Wrangler, klik tab Transformation steps untuk melihat urutan langkah Anda saat ini.
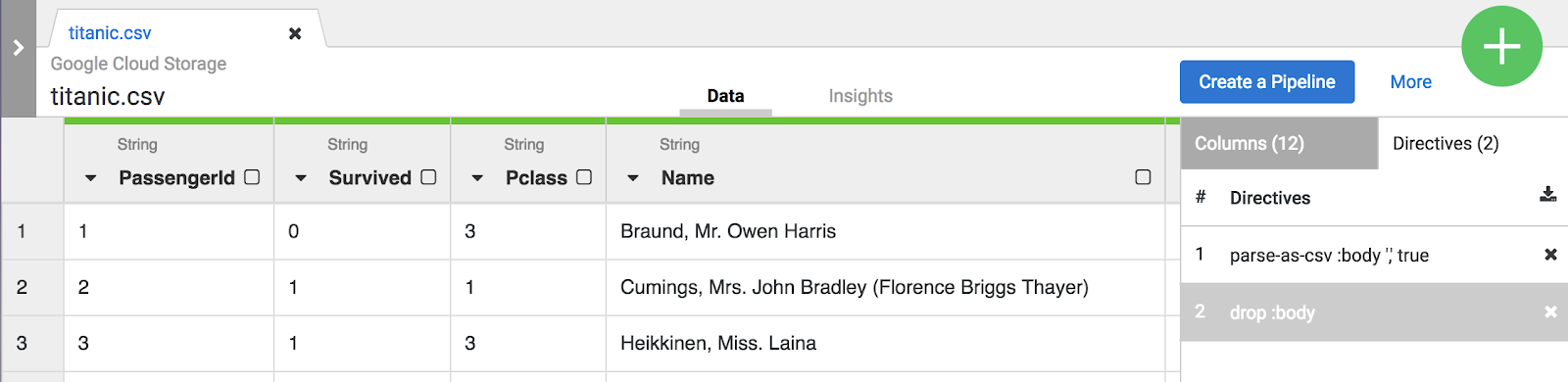
Catatan: Baik pilihan menu maupun CLI membuat perintah yang terlihat di tab Transformation steps
di sebelah kanan layar. Perintah adalah transformasi individual yang secara kolektif disebut sebagai urutan langkah.
Untuk tujuan lab ini, kedua transformasi, atau urutan langkah, sudah cukup untuk membuat pipeline ETL. Langkah berikutnya adalah memasukkan urutan langkah ini ke dalam langkah pembangunan pipeline, dan urutan langkah tersebut merepresentasikan T dalam ETL.
-
Klik tombol Create a Pipeline untuk melanjutkan proses ke bagian berikutnya guna membuat pipeline, tempat Anda akan melihat cara kerja pipeline ETL.

-
Saat dialog berikutnya muncul, pilih Batch pipeline untuk melanjutkan.
Catatan: Pipeline batch dapat dijalankan secara interaktif atau dijadwalkan untuk dijalankan sesering tiap 5 menit atau sedikit sekali dalam setahun.
Tugas 4. Mengonfigurasi sink BigQuery
Sisa tugas pembangunan pipeline akan dilakukan di pipeline studio, yakni UI yang memudahkan Anda menyusun pipeline data secara visual. Sekarang Anda akan melihat elemen penyusun utama pipeline ETL Anda di studio.
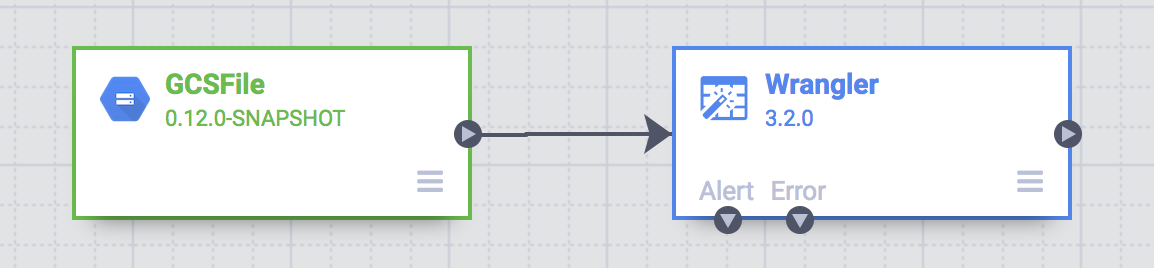
Di tahap ini, Anda akan melihat dua node di pipeline Anda: plugin GCS File yang akan membaca file CSV dari Google Cloud Storage dan plugin Wrangler yang berisi urutan langkah dengan transformasi.
Catatan: Node dalam pipeline adalah objek yang terhubung dalam urutan untuk menghasilkan Directed Acyclic Graph. Misalnya, Source, Sink, Transform, Action, dll.
Kedua plugin (node) ini merepresentasikan E dan T dalam pipeline ETL Anda. Untuk menyelesaikan pipeline ini, tambahkan sink BigQuery, yaitu bagian L dari ETL kita.
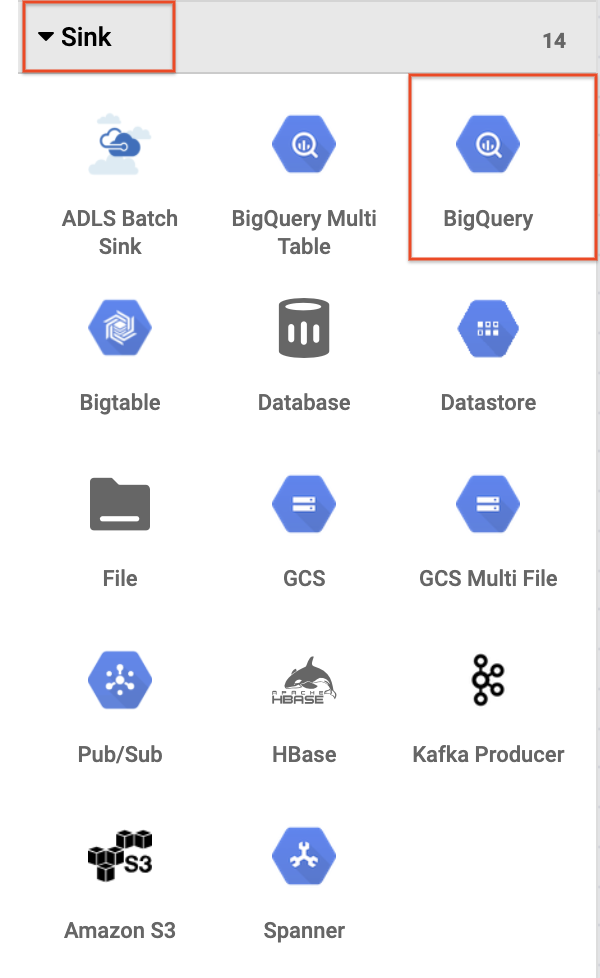
- Untuk menambahkan sink BigQuery ke pipeline, buka bagian Sink di panel kiri, lalu klik ikon BigQuery untuk menempatkannya di canvas.
-
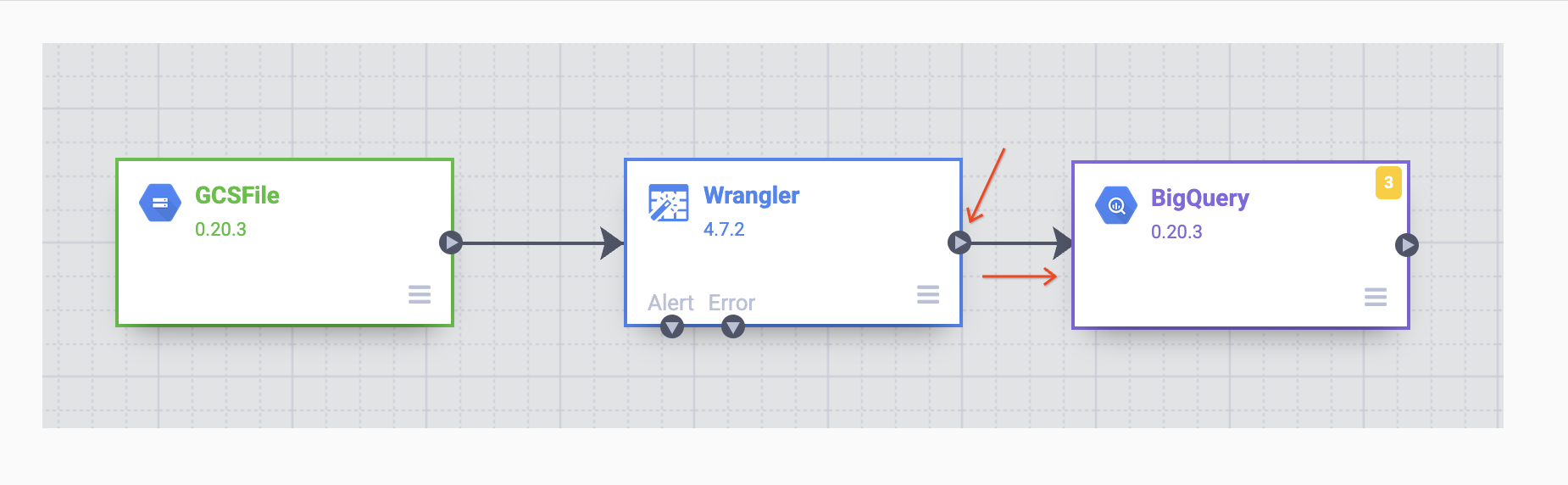
Setelah sink BigQuery ditempatkan di canvas, hubungkan node Wrangler dengan node BigQuery. Lakukan langkah ini dengan menarik panah dari node Wrangler untuk terhubung ke node BigQuery seperti yang diilustrasikan di bawah. Yang perlu dilakukan sekarang adalah menentukan beberapa opsi konfigurasi agar Anda dapat menulis data ke set data yang diinginkan.
Tugas 5. Mengonfigurasi pipeline
Sekarang saatnya mengonfigurasi pipeline. Anda dapat melakukannya dengan membuka properti tiap node untuk memverifikasi setelannya dan/atau membuat perubahan tambahan.
- Arahkan kursor ke node GCS dan tombol Properties akan ditampilkan. Klik tombol ini untuk membuka setelan konfigurasi.
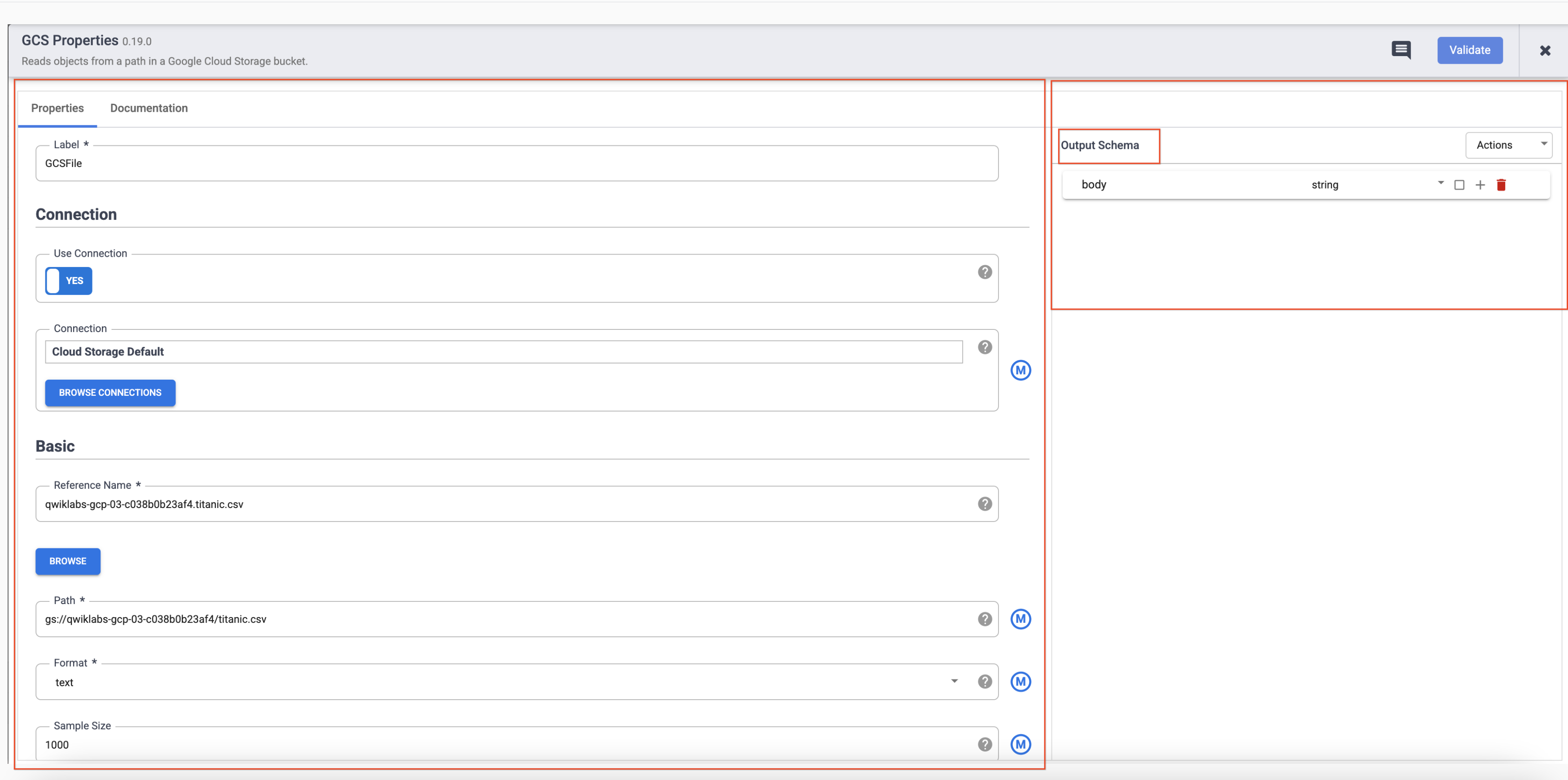
Tiap plugin memiliki beberapa kolom yang harus diisi dan ditandai dengan tanda bintang ( * ). Bergantung pada plugin yang Anda gunakan, Anda akan melihat Input Schema di sebelah kiri, bagian Configuration di tengah, dan Output Schema di sebelah kanan.
Anda akan melihat bahwa plugin Sink tidak memiliki skema output dan plugin Source tidak memiliki skema input. Plugin Sink dan Source juga akan memiliki kolom Reference Name wajib untuk mengidentifikasi sumber/sink data dalam silsilah.
Tiap plugin akan memiliki kolom Label. Ini adalah label node yang Anda lihat di canvas tempat pipeline Anda ditampilkan.
-
Klik X di kanan atas kotak Properties untuk menutupnya.
-
Selanjutnya, arahkan kursor ke node Wrangler Anda dan klik Properties.
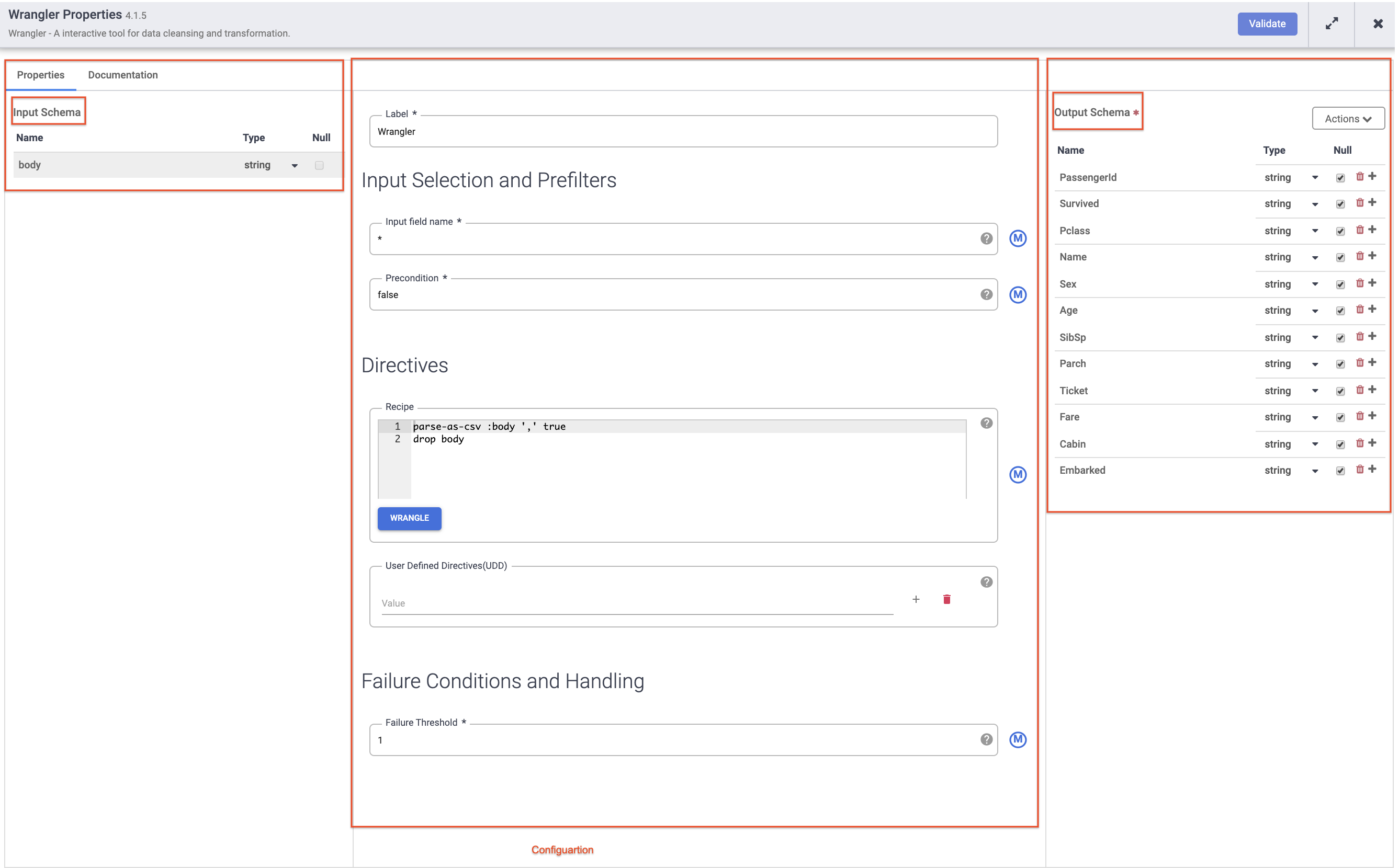
Catatan:
Plugin seperti Wrangler yang berisi skema input. Ini adalah kolom yang diteruskan ke plugin untuk diproses. Setelah diproses oleh plugin, data keluar dapat dikirim dalam skema output ke node berikutnya dalam pipeline, atau dalam kasus sink yang ditulis ke set data.
-
Klik X di kanan atas kotak Properties untuk menutupnya.
-
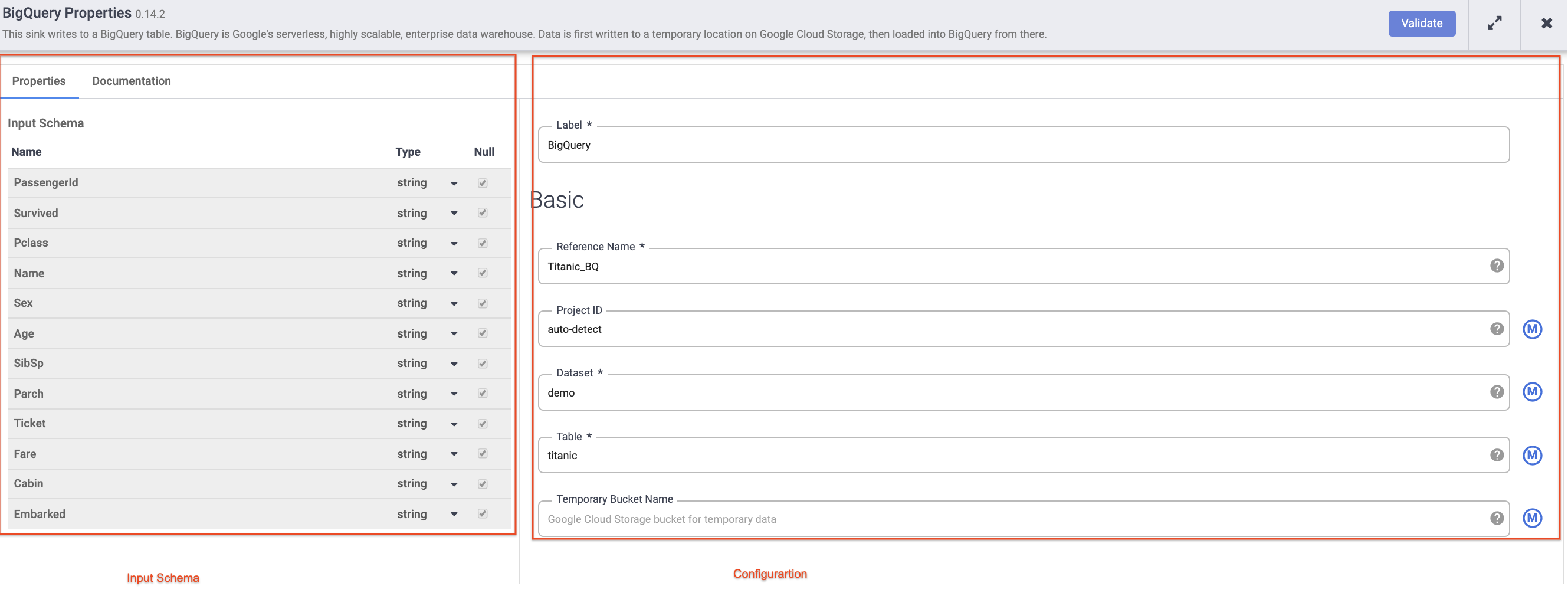
Arahkan kursor ke node BigQuery Anda, klik Properties, lalu masukkan setelan konfigurasi berikut:
-
Untuk Reference Name, masukkan Titanic_BQ.
-
Untuk Dataset, masukkan demo.
-
Untuk Table, masukkan titanic.
-
Klik X di kanan atas kotak Properties untuk menutupnya.
Tugas 6. Menguji pipeline
Sekarang, yang perlu Anda lakukan adalah menguji pipeline untuk memastikan pipeline tersebut berfungsi seperti yang diharapkan. Namun, sebelum melakukannya, pastikan Anda memberi nama dan menyimpan draf agar pekerjaan Anda tidak hilang.
-
Sekarang klik Save dari menu pojok kanan atas. Anda akan diminta untuk memberikan Name dan menambahkan description ke pipeline.
- Masukkan
ETL-batch-pipeline sebagai nama pipeline Anda.
- Masukkan
ETL pipeline to parse CSV, transform and write output to BigQuery untuk description.
-
Klik Save.
-
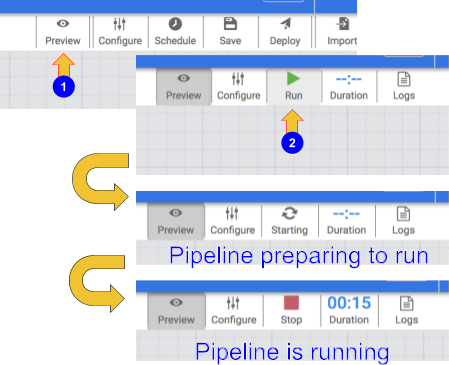
Untuk menguji pipeline Anda, klik ikon Preview. Panel tombol sekarang akan menampilkan ikon Run yang dapat Anda klik untuk menjalankan pipeline dalam mode pratinjau.
-
Klik ikon Run. Saat pipeline berjalan dalam mode pratinjau, tidak ada data yang benar-benar ditulis ke tabel BigQuery, tetapi Anda akan dapat mengonfirmasi bahwa data dibaca dengan benar dan akan ditulis sesuai harapan setelah pipeline di-deploy. Tombol pratinjau adalah tombol pengalih, jadi pastikan untuk mengkliknya lagi untuk keluar dari mode pratinjau setelah selesai.
-
Setelah pipeline selesai berjalan, arahkan kursor mouse ke node Wrangler Anda dan klik Properties. Lalu klik tab Preview. Jika semuanya berjalan lancar, Anda akan melihat data mentah yang masuk dari input, node di sebelah kiri, dan kumpulan data yang diuraikan yang akan dikeluarkan sebagai output, ke node di sebelah kanan. Klik X di kanan atas kotak Properties untuk menutupnya.
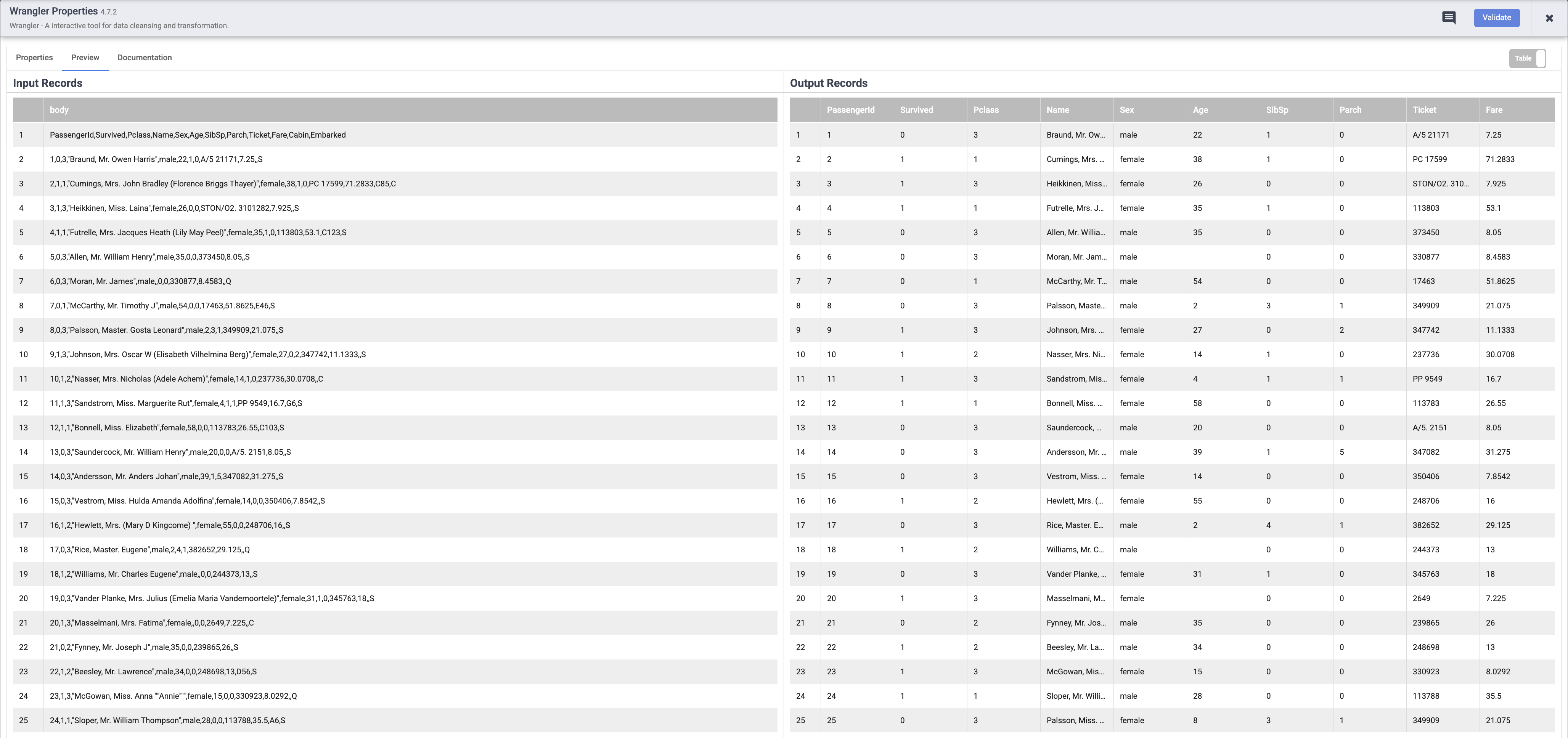
Catatan: Tiap node yang beroperasi pada data akan menampilkan output yang serupa. Ini adalah cara yang baik untuk membuktikan pekerjaan Anda guna memastikan Anda berada di jalur yang benar sebelum men-deploy pipeline Anda. Jika Anda menemukan kesalahan, Anda bisa dengan mudah memperbaikinya saat dalam mode draf.
-
Klik ikon Preview lagi, kali ini untuk menonaktifkan mode Pratinjau.
-
Jika semuanya terlihat baik sejauh ini, Anda dapat melanjutkan tahap untuk men-deploy pipeline. Klik ikon Deploy di kanan atas  untuk men-deploy pipeline.
untuk men-deploy pipeline.
Anda akan melihat dialog konfirmasi bahwa pipeline Anda sedang di-deploy:
-
Setelah pipeline Anda berhasil di-deploy, Anda akan siap menjalankan pipeline ETL dan memuat beberapa data ke BigQuery.
-
Klik ikon Run untuk menjalankan tugas ETL.
-
Setelah selesai, Anda akan melihat status pipeline berubah menjadi Succeeded yang menunjukkan bahwa pipeline berhasil dijalankan.

-
Saat data diproses oleh pipeline, Anda akan melihat metrik yang dikeluarkan oleh tiap node di pipeline yang menunjukkan jumlah kumpulan data yang telah diproses.
Dalam operasi penguraian, 892 kumpulan data ditampilkan, sedangkan di sumber terdapat 893 kumpulan data. Apa yang terjadi? Operasi penguraian mengambil baris pertama dan menggunakannya untuk menetapkan judul kolom, sehingga 892 kumpulan data yang tersisa adalah yang akan diproses.

Klik Periksa progres saya untuk memverifikasi tujuan
Men-deploy dan menjalankan pipeline batch
Tugas 7. Melihat hasil
Pipeline akan menulis output ke tabel BigQuery. Anda dapat memverifikasinya menggunakan langkah-langkah berikut.
-
Di tab baru, buka UI BigQuery di Konsol Cloud atau klik kanan tab Konsol dan pilih Duplicate, lalu gunakan Navigation menu untuk memilih BigQuery. Saat diminta, klik Done.
-
Di panel kiri, di bagian Classic Explorer, klik Project ID Anda (akan dimulai dengan qwiklabs).
-
Di bawah set data demo di project Anda, klik tabel titanic dan klik "+" (kueri SQL), lalu jalankan kueri sederhana, seperti:
SELECT * FROM `demo.titanic` LIMIT 10
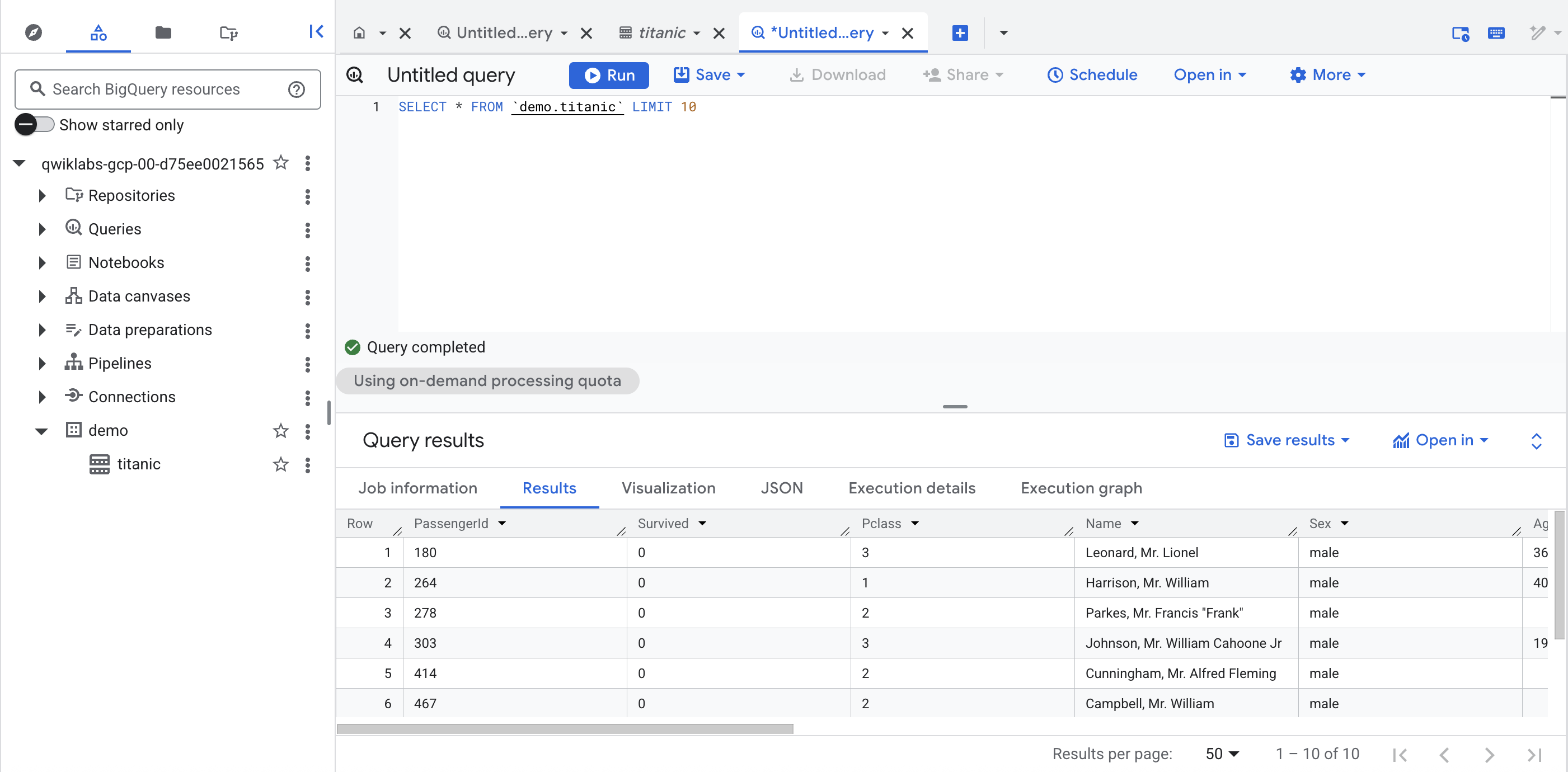
Klik Periksa progres saya untuk memverifikasi tujuan
Lihat hasilnya
Selamat!
Anda kini telah mempelajari cara menggunakan elemen penyusun yang tersedia di Pipeline Studio Cloud Data Fusion untuk membangun pipeline batch. Anda juga telah mempelajari cara menggunakan Wrangler untuk membuat langkah-langkah transformasi data.
Ikuti lab berikutnya
Lanjutkan dengan Membangun Transformasi dan Menyiapkan Data dengan Wrangler di Cloud Data Fusion.
Manual Terakhir Diperbarui pada 27 Januari 2026
Lab Terakhir Diuji pada 27 Januari 2026
Hak cipta 2026 Google LLC. Semua hak dilindungi undang-undang. Google dan logo Google adalah merek dagang dari Google LLC. Semua nama perusahaan dan produk lain mungkin adalah merek dagang dari tiap-tiap perusahaan yang bersangkutan.






