GSP807

Übersicht
ETL steht für Extract, Transform und Load. Es gibt verschiedene andere Varianten dieses Konzepts, darunter EL, ELT und ELTL.
In diesem Lab lernen Sie, wie Sie mit dem Pipeline Studio in Cloud Data Fusion eine ETL-Pipeline erstellen. Pipeline Studio bietet die Bausteine und integrierten Plug-ins, mit denen Sie Ihre Batchpipeline Knoten für Knoten erstellen können. Außerdem verwenden Sie das Wrangler-Plug-in, um Transformationen für Daten zu erstellen und anzuwenden, die durch die Pipeline geleitet werden.
Die häufigste Datenquelle für ETL-Anwendungen sind in der Regel Daten, die in Textdateien im CSV-Format (Comma Separated Value) gespeichert sind. Viele Datenbanksysteme exportieren und importieren Daten auf diese Weise. In diesem Lab verwenden Sie eine CSV-Datei, aber die gleichen Techniken können auch auf Datenbankquellen sowie auf jede andere verfügbare Datenquelle angewendet werden.
Die Ausgabe wird in eine BigQuery-Tabelle geschrieben und Sie führen Datenanalysen für dieses Ziel-Dataset mit Standard-SQL durch.
Ziele
Aufgaben in diesem Lab:
- Batchpipeline mit Pipeline Studio in Cloud Data Fusion erstellen
- Mit Wrangler Daten interaktiv transformieren
- Ausgabe in BigQuery schreiben
Einrichtung und Anforderungen
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
-
Melden Sie sich über ein Inkognitofenster bei Google Skills an.
-
Beachten Sie die Zugriffszeit (z. B. 02:00:00) und achten Sie darauf, dass Sie das Lab innerhalb dieser Zeit abschließen.
Es gibt keine Pausenfunktion. Sie können bei Bedarf neu starten, müssen dann aber von vorn beginnen.
-
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Hinweis: Nachdem Sie auf Lab starten geklickt haben, dauert es etwa 15 bis 20 Minuten, bis die erforderlichen Ressourcen für das Lab bereitgestellt und eine Data Fusion-Instanz erstellt wurden.
In der Zwischenzeit können Sie sich anhand der unten aufgeführten Schritte mit den Zielen des Labs vertraut machen.
Wenn im linken Bereich Lab-Anmeldedaten (Nutzername und Passwort) angezeigt werden, ist die Instanz erstellt und Sie können sich in der Console anmelden.
-
Notieren Sie sich Ihre Anmeldedaten (Nutzername und Passwort). Mit diesen Daten melden Sie sich in der Google Cloud Console an.
-
Klicken Sie auf Google Console öffnen.
-
Klicken Sie auf Anderes Konto verwenden. Kopieren Sie den Nutzernamen und das Passwort für dieses Lab und fügen Sie beides in die entsprechenden Felder ein.
Wenn Sie andere Anmeldedaten verwenden, tritt ein Fehler auf oder es fallen Kosten an.
-
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen.
Hinweis: Über den Button Lab beenden wird Ihre Arbeit gelöscht und das Projekt entfernt. Sie sollten daher nur darauf klicken, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten.
Bei der Google Cloud Console anmelden
- Kopieren Sie im Browsertab oder Fenster für diese Lab-Sitzung im Bereich Verbindungsdetails den Nutzernamen und klicken Sie auf den Button Google Console öffnen.
Hinweis: Wenn die Eingabeaufforderung „Konto auswählen“ angezeigt wird, klicken Sie auf Anderes Konto verwenden.
- Fügen Sie den Nutzernamen und das Passwort ein, wenn Sie dazu aufgefordert werden.
- Klicken Sie auf Weiter.
- Akzeptieren Sie die Nutzungsbedingungen.
Da es sich um ein temporäres Konto handelt, das nur für die Dauer dieses Labs verfügbar ist, beachten Sie bitte Folgendes:
- Fügen Sie keine Wiederherstellungsoptionen hinzu.
- Melden Sie sich nicht für kostenlose Testversionen an.
- Wenn die Console geöffnet wurde, klicken Sie oben links auf das Navigationsmenü (
 ), um die Liste der Dienste aufzurufen.
), um die Liste der Dienste aufzurufen.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Cloud Shell bietet Ihnen Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen. gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
-
Klicken Sie in der Google Cloud Console im Navigationsbereich auf Cloud Shell aktivieren ( ).
).
-
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:

Beispielbefehle
gcloud auth list
(Ausgabe)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Beispielausgabe)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Ausgabe)
[core]
project = <project_ID>
(Beispielausgabe)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Projektberechtigungen prüfen
Bevor Sie mit der Arbeit in Google Cloud beginnen, müssen Sie sicherstellen, dass für Ihr Projekt im Rahmen von Identity and Access Management (IAM) die nötigen Berechtigungen vorliegen.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf IAM und Verwaltung > IAM.
-
Prüfen Sie, ob das standardmäßige Compute-Dienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden und ihm die Rolle Bearbeiter zugewiesen ist. Das Kontopräfix ist die Projektnummer. Sie finden sie im Navigationsmenü unter Cloud-Übersicht.

Wenn das Konto nicht in IAM vorhanden ist oder nicht über die Bearbeiter-Rolle verfügt, weisen Sie die erforderliche Rolle so zu:
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf Cloud-Übersicht.
-
Kopieren Sie auf der Karte Projektinformationen die Projektnummer.
-
Klicken Sie im Navigationsmenü auf IAM und Verwaltung > IAM.
-
Klicken Sie oben auf der Seite IAM auf Hinzufügen.
-
Geben Sie unter Neue Hauptkonten ein:
{project-number}-compute@developer.gserviceaccount.com
Ersetzen Sie {project-number} durch die entsprechende Projektnummer.
-
Wählen Sie unter Rolle auswählen die Option Basic (oder „Projekt“) > Editor aus.
-
Klicken Sie auf Speichern.
Aufgabe 1: Daten laden
In dieser Aufgabe erstellen Sie einen Cloud Storage-Bucket in Ihrem Projekt und stellen eine CSV-Datei bereit. Cloud Data Fusion liest später Daten aus diesem Storage-Bucket.
- Führen Sie in Cloud Shell die folgenden Befehle aus, um einen neuen Bucket zu erstellen, und kopieren Sie die relevanten Daten dorthin:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
Der erstellte Bucket-Name ist Ihre Projekt-ID.
- Führen Sie den folgenden Befehl aus, um die Datendateien (eine CSV- und eine XML-Datei) in Ihren Bucket zu kopieren:
gsutil cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Klicken Sie auf Fortschritt prüfen.
Daten laden
Aufgabe 2: Erforderliche Berechtigungen für Ihre Cloud Data Fusion-Instanz hinzufügen
In dieser Aufgabe weisen Sie dem Dienstkonto, das der Cloud Data Fusion-Instanz zugeordnet ist, die erforderlichen IAM-Rollen zu.
- Klicken Sie in der Google Cloud Console im Navigationsmenü auf Alle Produkte ansehen und wählen Sie unter der Kategorie Analytics die Option Data Fusion > Instanzen aus. Sie sollten eine Cloud Data Fusion-Instanz sehen, die bereits eingerichtet und einsatzbereit ist.
Hinweis: Das Erstellen der Instanz dauert etwa 10 Minuten. Bitte warten Sie, bis der Vorgang abgeschlossen ist.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf IAM und Verwaltung > IAM.
-
Suchen Sie das Compute Engine-Standarddienstkonto {project-number}-compute@developer.gserviceaccount.com und kopieren Sie das Dienstkonto in die Zwischenablage.
-
Klicken Sie auf der Seite „IAM-Berechtigungen“ auf + Zugriff erlauben.
-
Fügen Sie im Feld „Neue Hauptkonten“ das Dienstkonto ein.
-
Geben Sie unter Rolle auswählen den Text Cloud Data Fusion API-Dienst-Agent ein und wählen Sie die Rolle aus.
-
Klicken Sie auf + Weitere Rolle hinzufügen.
-
Wählen Sie unter Rolle auswählen die Rolle Dataproc-Administrator aus.
-
Klicken Sie auf Speichern.
Klicken Sie auf Fortschritt prüfen.
Rolle „Cloud Data Fusion API-Dienst-Agent“ zum Dienstkonto hinzufügen
Dienstkontonutzerin/Dienstkontonutzer die Berechtigung erteilen
-
Klicken Sie in der Console im Navigationsmenü auf IAM & Verwaltung > IAM.
-
Klicken Sie auf das Kästchen Von Google bereitgestellte Rollenzuweisungen einschließen.
-
Suchen Sie in der Liste nach dem von Google verwalteten Cloud Data Fusion-Dienstkonto, das so aussieht: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Kopieren Sie dann den Namen des Dienstkontos in die Zwischenablage.

-
Rufen Sie als Nächstes IAM & Verwaltung > Dienstkonten auf.
-
Klicken Sie auf das Compute Engine-Standardkonto, das so aussieht: {project-number}-compute@developer.gserviceaccount.com, und wählen Sie in der oberen Navigationsleiste den Tab Hauptkonten mit Zugriff aus.
-
Klicken Sie auf den Button Zugriff gewähren.
-
Fügen Sie im Feld Neue Hauptkonten das zuvor kopierte Dienstkonto ein.
-
Wählen Sie im Drop‑down-Menü Rolle die Option Dienstkontonutzer aus.
-
Klicken Sie auf Speichern.
Aufgabe 3: Batchpipeline erstellen
In dieser Aufgabe verwenden Sie die Wrangler-Komponente in Cloud Data Fusion, um Rohdaten vorzubereiten und zu bereinigen. Mit diesem iterativen Prozess können Sie Transformationen in Echtzeit visualisieren.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf Data Fusion > Instanzen.
-
Klicken Sie für Ihre Instanz auf Instanz aufrufen. Melden Sie sich bei Aufforderung mit den Anmeldedaten des Labs an. Wenn Ihnen eine Tour angeboten wird, klicken Sie auf Nein danke.
-
Klicken Sie in der Cloud Data Fusion-UI im Navigationsmenü auf Wrangler.
-
Klicken Sie im linken Bereich auf (GCS) Google Cloud Storage und wählen Sie Cloud Storage – Standard aus.
-
Klicken Sie auf den Bucket mit der entsprechenden Projekt-ID.
-
Klicken Sie auf titanic.csv.
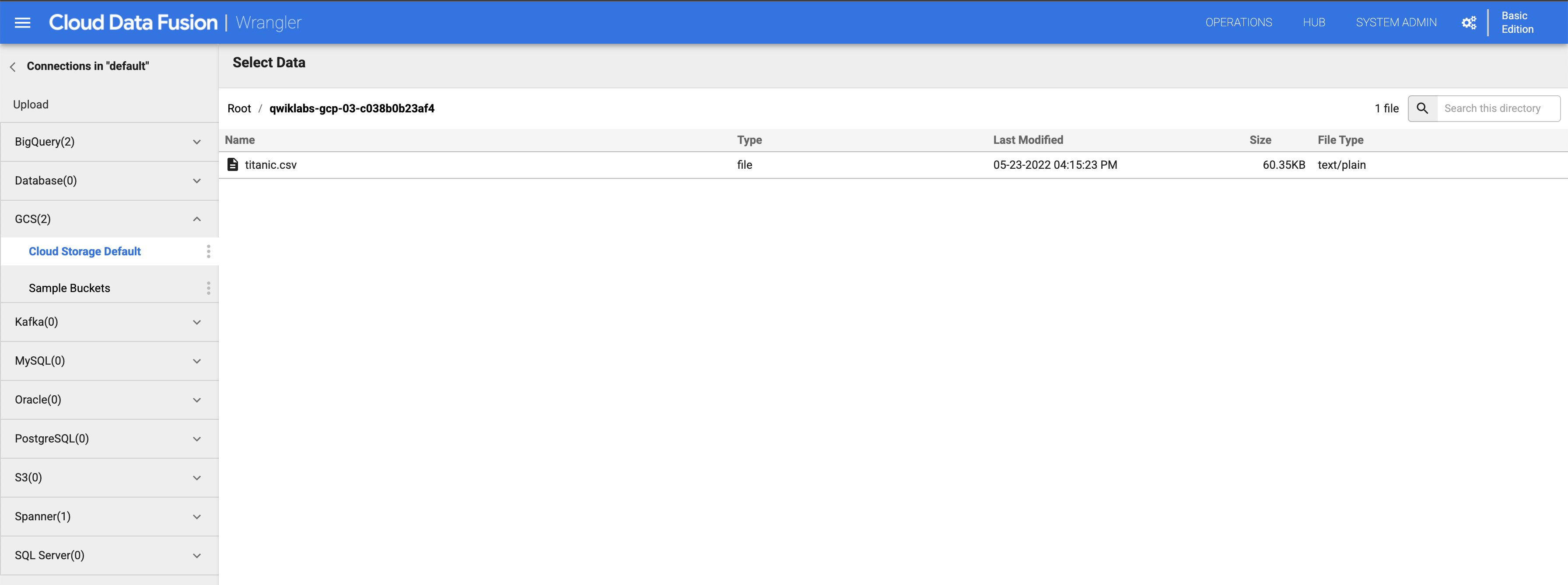
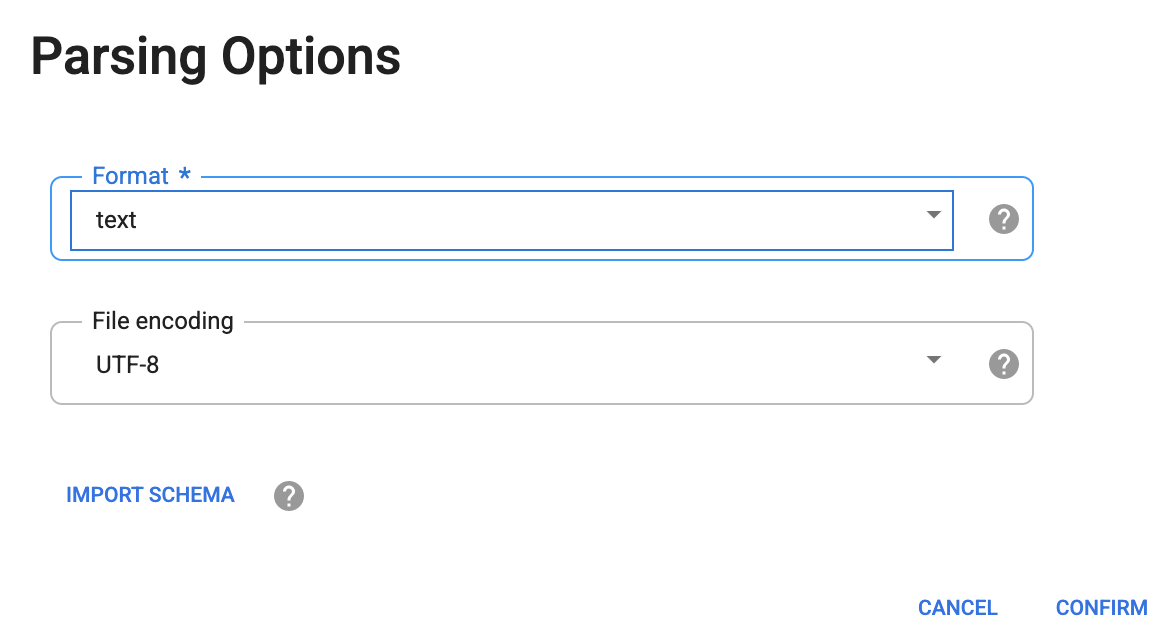
-
Wählen Sie im Dialogfeld Parsing-Optionen für Format die Option Text aus und klicken Sie auf Bestätigen.
Die Daten werden in den Wrangler-Bildschirm geladen. Sie können jetzt mit der iterativen Anwendung der Datentransformationen beginnen.
-
Klicken Sie zum Parsen der CSV-Rohdaten in ein Tabellenformat auf den Pfeil neben der Spaltenüberschrift body, wählen Sie Parsen und dann CSV aus.
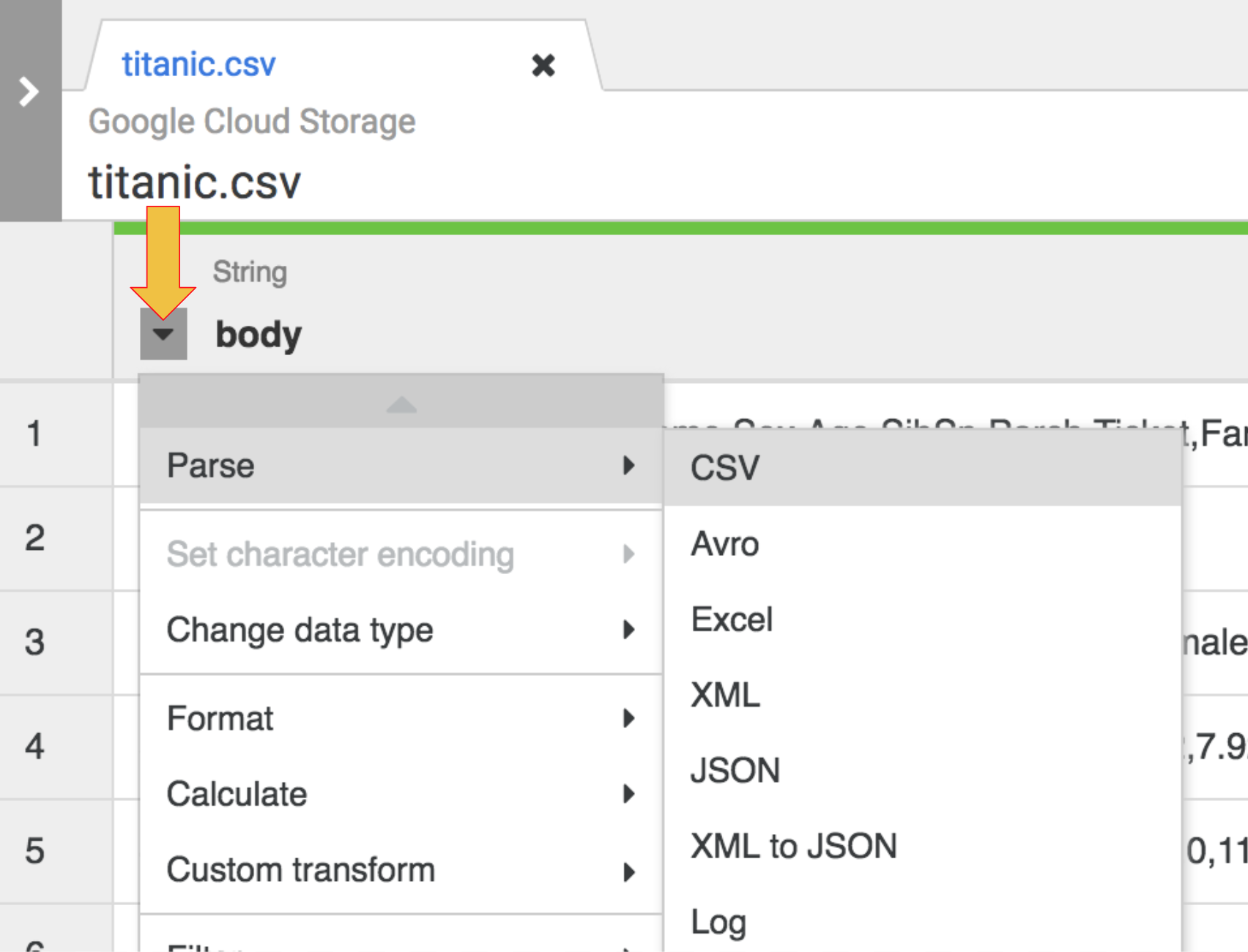
-
Wählen Sie im Dialogfeld Als CSV-Datei parsen das Kästchen Erste Zeile als Header festlegen aus und klicken Sie auf Anwenden.
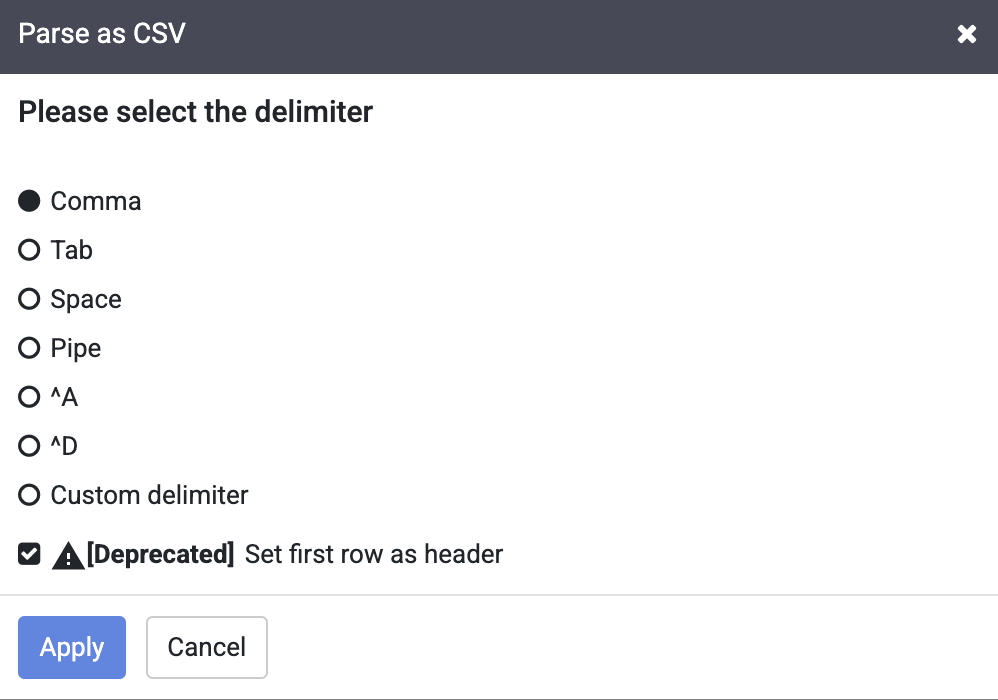
Hinweis: Sie können die Warnung zur Einstellung neben dem Kästchen Erste Zeile als Header festlegen ignorieren.
- In dieser Phase werden die Rohdaten geparst und Sie sehen die Spalten, die durch diesen Vorgang generiert wurden (Spalten rechts neben der Spalte body). Ganz rechts sehen Sie die Liste aller Spaltennamen.
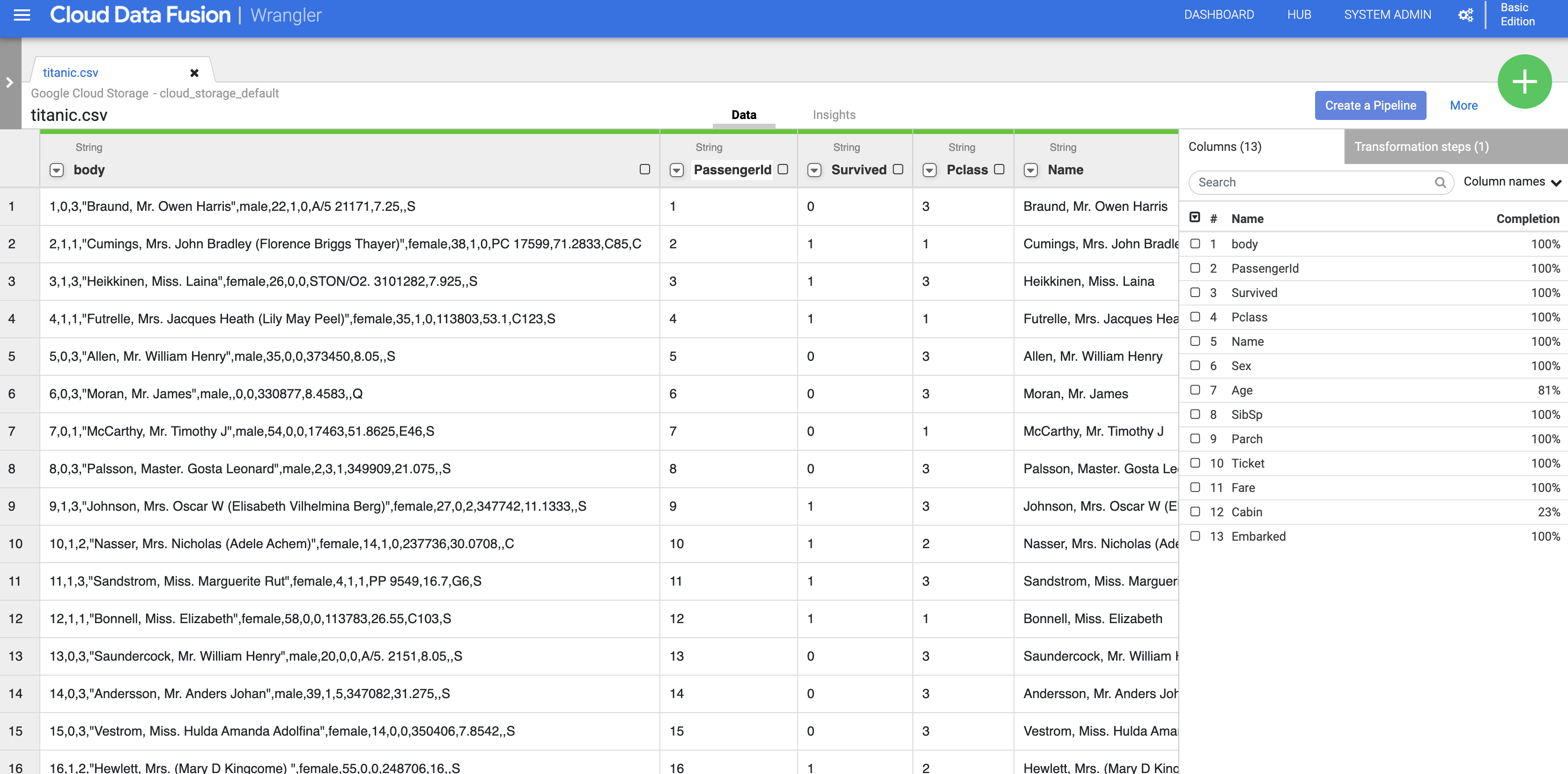
- Klicken Sie auf den Pfeil neben der Spaltenüberschrift body und dann auf Spalte löschen, um die Spalte mit den Rohdaten zu entfernen.
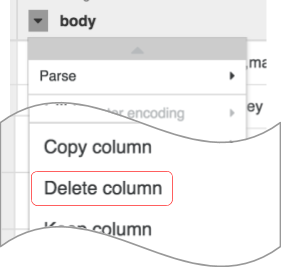
Hinweis: Sie können Transformationen auch über die Befehlszeile anwenden. Die Befehlszeile ist die schwarze Leiste am unteren Bildschirmrand (mit dem grünen Prompt $). Wenn Sie mit der Eingabe von Befehlen beginnen, wird die Autofill-Funktion aktiviert und zeigt Ihnen eine passende Option an. Um beispielsweise die Spalte „body“ zu entfernen, hätten Sie alternativ die Anweisung drop :body verwenden können.
- Klicken Sie rechts in der Wrangler-Benutzeroberfläche auf den Tab Transformationsschritte, um Ihr aktuelles Schema aufzurufen.
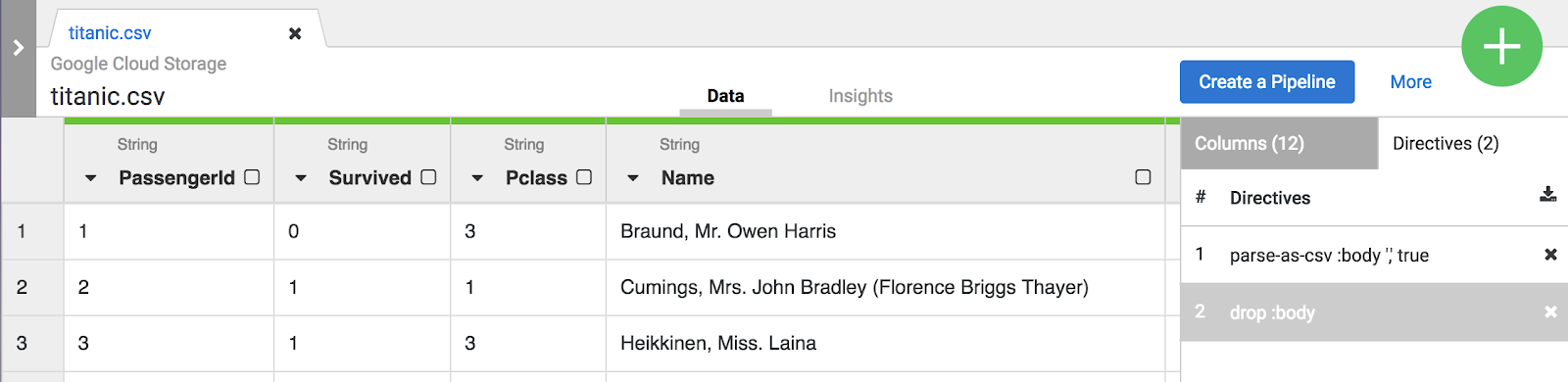
Hinweis: Sowohl die Menüauswahl als auch die Befehlszeile erstellen Anweisungen, die auf dem Tab Transformationsschritte rechts auf dem Bildschirm sichtbar sind. Anweisungen sind einzelne Transformationen, die zusammen als Schema bezeichnet werden.
Für dieses Lab reichen die beiden Transformationen oder das Schema aus, um die ETL-Pipeline zu erstellen. Im nächsten Schritt wird dieses Schema in einen Pipeline-Erstellungsschritt eingebunden, wobei das Schema für das „T“ in ETL steht.
-
Klicken Sie auf den Button Pipeline erstellen, um zum nächsten Abschnitt zu gelangen und eine Pipeline zu erstellen. Dort sehen Sie, wie die ETL-Pipeline zusammengesetzt wird.

-
Wählen Sie dann im angezeigten Dialogfeld die Option Batchpipeline aus.
Hinweis: Eine Batchpipeline kann interaktiv ausgeführt oder so geplant werden, dass sie alle 5 Minuten oder nur einmal im Jahr ausgeführt wird.
Aufgabe 4: BigQuery-Senke konfigurieren
Die restlichen Aufgaben zum Erstellen der Pipeline werden im Pipeline Studio ausgeführt, der Benutzeroberfläche, mit der Sie Datenpipelines visuell zusammenstellen können. Sie sollten jetzt die wichtigsten Bausteine Ihrer ETL-Pipeline im Studio sehen.
An diesem Punkt sehen Sie zwei Knoten in Ihrer Pipeline: das GCS-Datei-Plug-in, das die CSV-Datei aus Google Cloud Storage liest, und das Wrangler-Plug-in, das das Schema mit den Transformationen enthält.
Hinweis: Ein Knoten in einer Pipeline ist ein Objekt, das in einer Sequenz verbunden ist, um einen gerichteten azyklischen Graphen zu erzeugen. Beispiele: Quelle, Senke, Transformation, Aktion usw.
Diese beiden Plug-ins (Knoten) stehen für die E- und T-Phase in Ihrer ETL-Pipeline. Fügen Sie zum Vervollständigen dieser Pipeline die BigQuery-Senke hinzu, den L-Teil unseres ETL-Vorgangs.
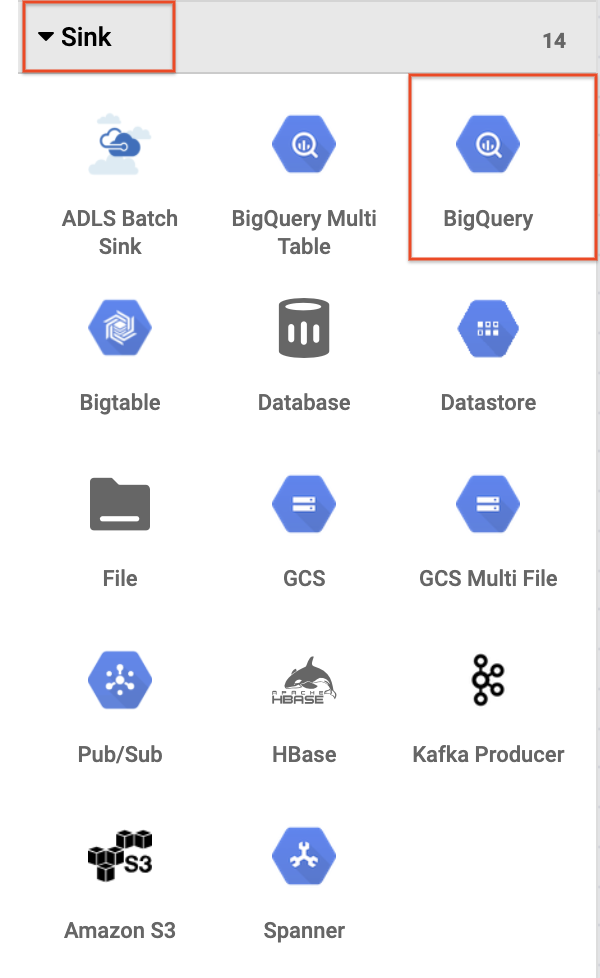
- Um die BigQuery-Senke zur Pipeline hinzuzufügen, rufen Sie im linken Bereich den Abschnitt Senke auf und klicken Sie auf das Symbol BigQuery, um es auf den Canvas zu platzieren.
-
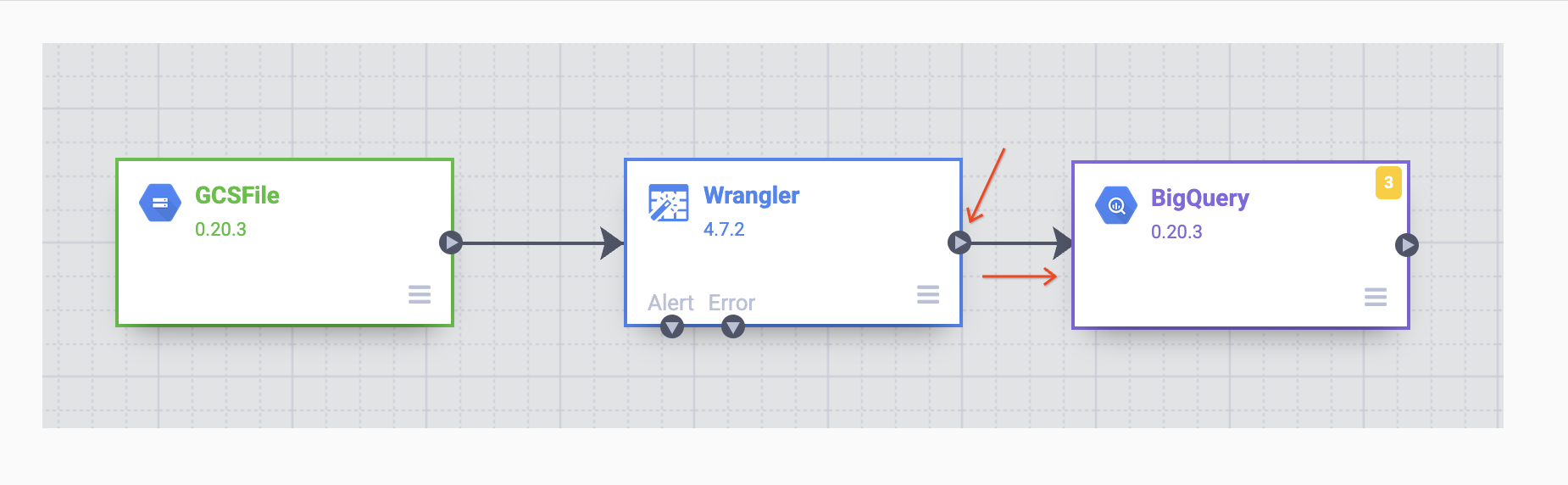
Sobald die BigQuery-Senke auf dem Canvas platziert wurde, verbinden Sie den Wrangler-Knoten mit dem BigQuery-Knoten. Ziehen Sie dazu den Pfeil vom Wrangler-Knoten zum BigQuery-Knoten, wie unten dargestellt. Jetzt müssen Sie nur noch einige Konfigurationsoptionen festlegen, damit Sie die Daten in das gewünschte Dataset schreiben können.
Aufgabe 5: Pipeline konfigurieren
Jetzt konfigurieren Sie die Pipeline. Dazu öffnen Sie die Attribute der einzelnen Knoten, um die Einstellungen zu überprüfen und/oder zusätzliche Änderungen vorzunehmen.
- Bewegen Sie den Mauszeiger auf den Knoten GCS. Daraufhin wird der Button Attribute angezeigt. Klicken Sie auf diesen Button, um die Konfigurationseinstellungen zu öffnen.
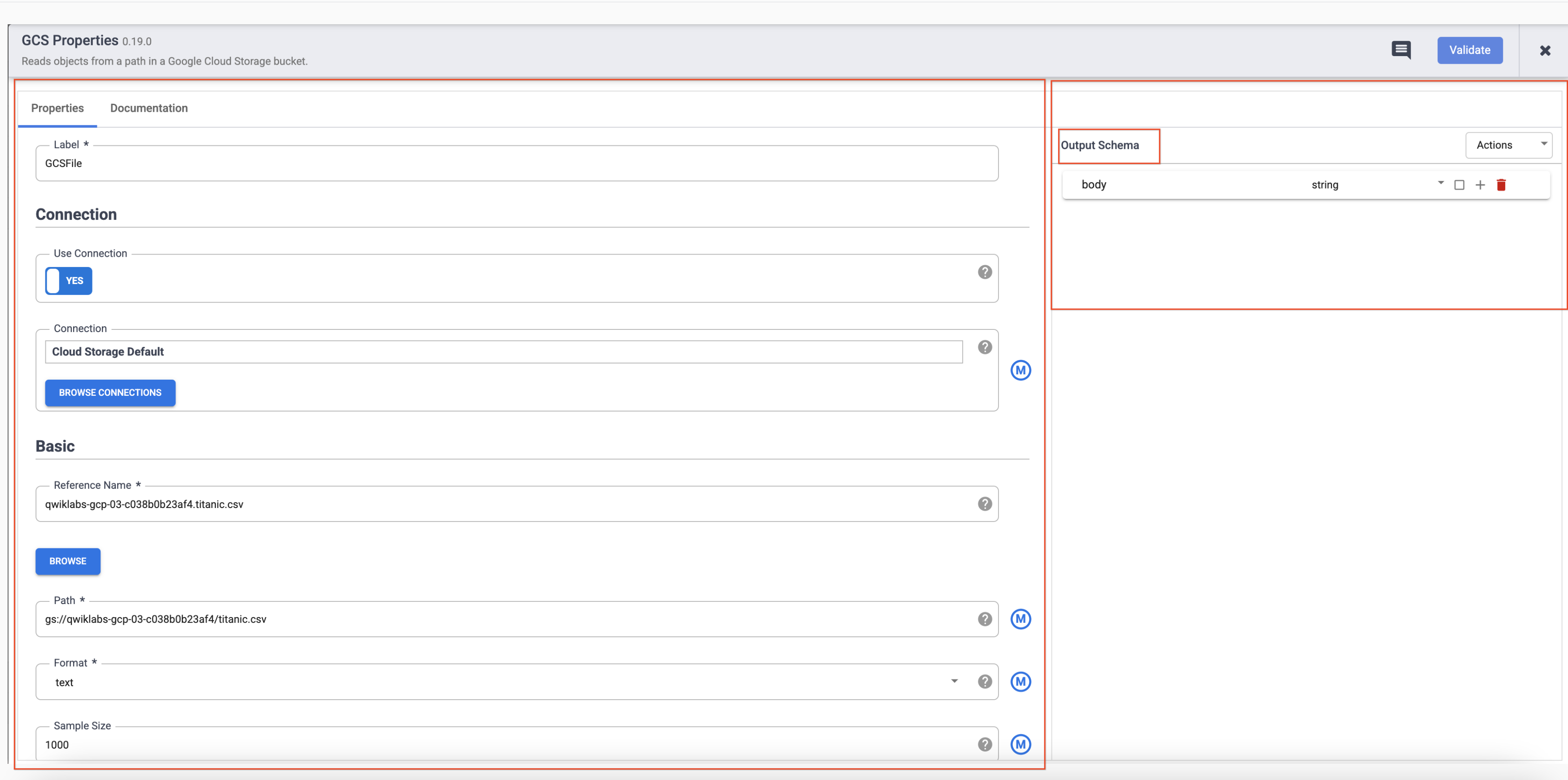
Jedes Plug-in hat einige Pflichtfelder, die vorhanden sein müssen und mit einem Sternchen (*) gekennzeichnet sind. Je nach Plug-in sehen Sie links ein Eingabeschema, in der Mitte den Abschnitt Konfiguration und rechts ein Ausgabeschema.
Senken-Plug-ins haben kein Ausgabeschema und Quell-Plug-ins haben kein Eingabeschema. Sowohl Senken- als auch Quell-Plug-ins haben das Pflichtfeld Referenzname, um die Datenquelle/Senke für die Herkunft zu identifizieren.
Jedes Plug-in hat ein Feld vom Typ Label. Dies ist das Label des Knotens, der im Canvas angezeigt wird, in dem Ihre Pipeline dargestellt ist.
-
Klicken Sie zum Schließen oben rechts im Feld „Attribute“ auf das X.
-
Bewegen Sie den Mauszeiger auf den Knoten Wrangler und klicken Sie auf Attribute.
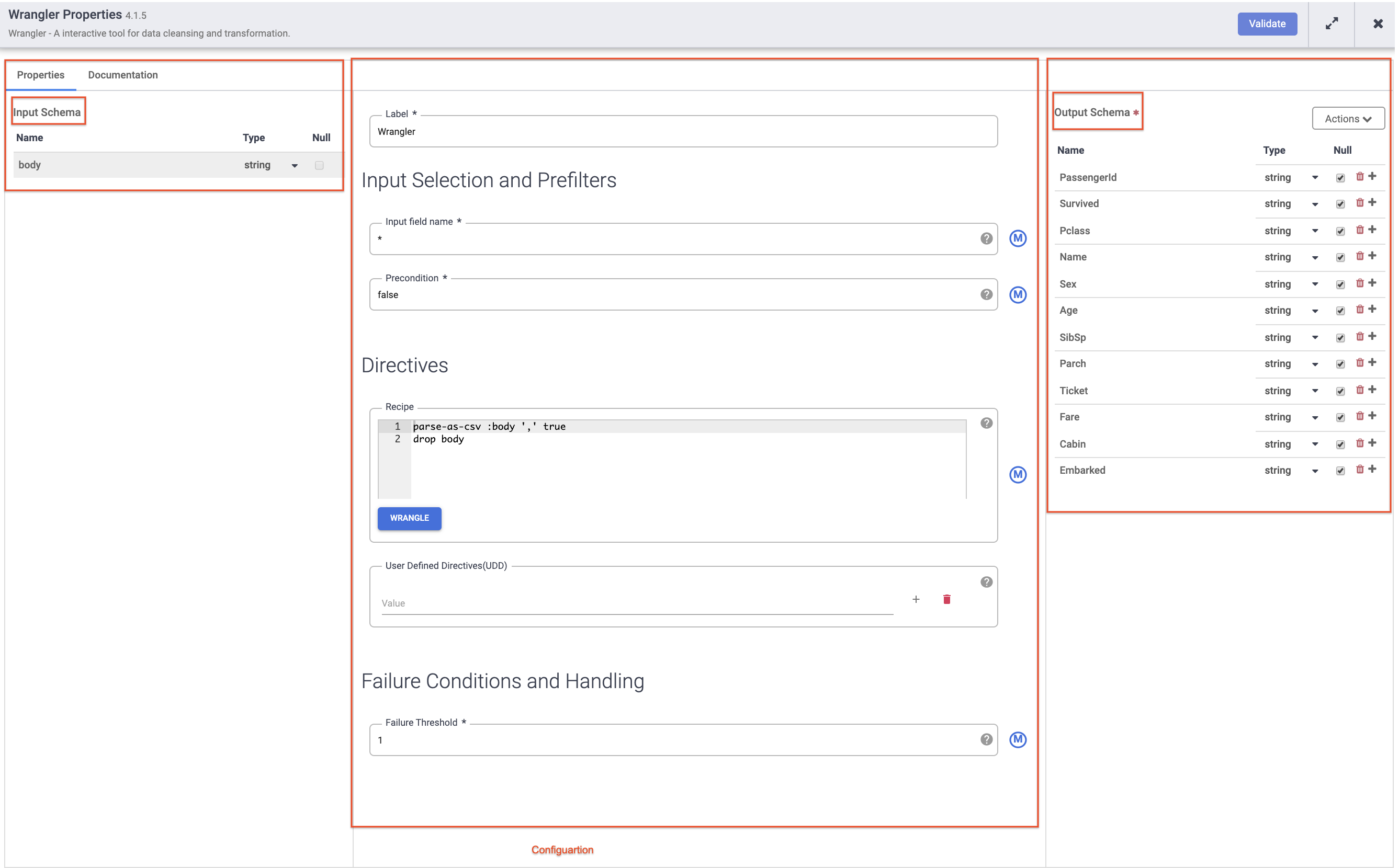
Hinweis:
Plugins wie Wrangler, die ein Eingabeschema enthalten. Diese Felder werden zur Verarbeitung an das Plug-in übergeben. Nach der Verarbeitung durch das Plug-in können ausgehende Daten im Ausgabeschema an den nächsten Knoten in der Pipeline gesendet oder im Fall einer Senke in ein Dataset geschrieben werden.
-
Klicken Sie zum Schließen oben rechts im Feld „Attribute“ auf das X.
-
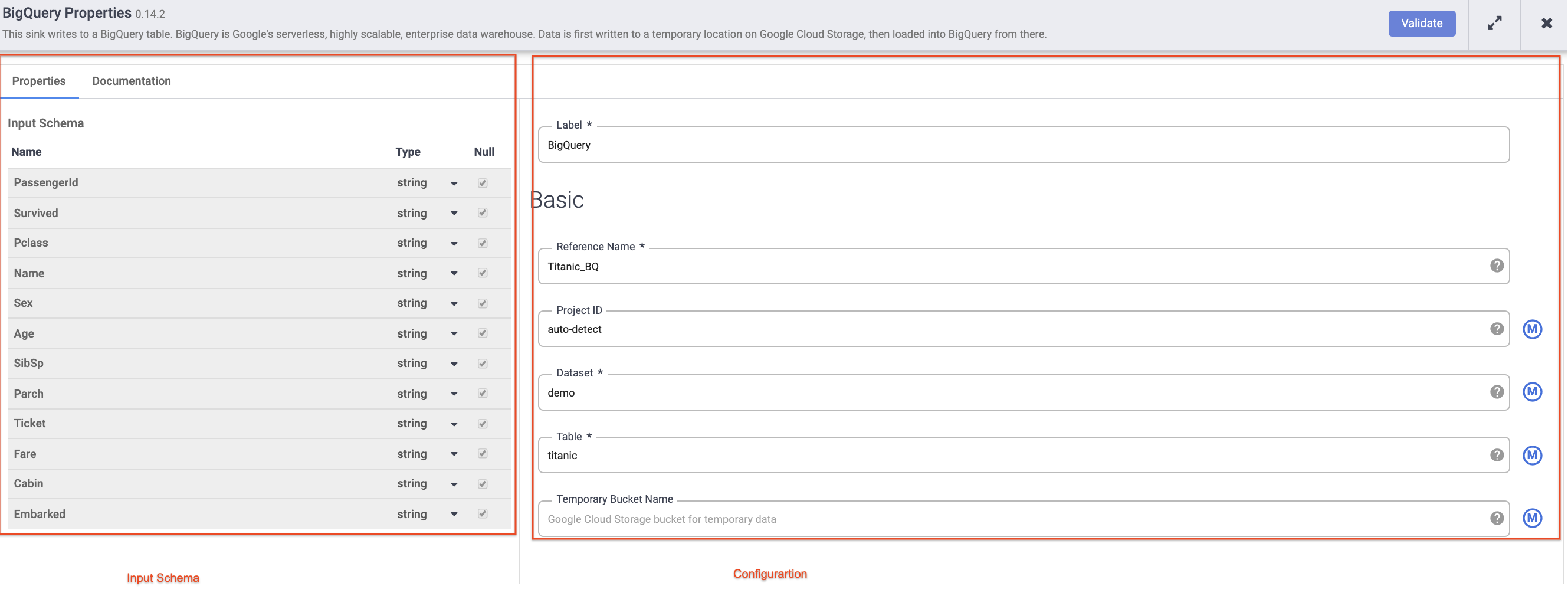
Bewegen Sie den Mauszeiger über den BigQuery-Knoten, klicken Sie auf Attribute und geben Sie die folgenden Konfigurationseinstellungen ein:
-
Geben Sie unter Referenzname Titanic_BQ ein.
-
Geben Sie unter Dataset demo ein.
-
Geben Sie für Tabelle titanic ein.
-
Klicken Sie zum Schließen oben rechts im Feld „Attribute“ auf das X.
Aufgabe 6: Pipeline testen
Jetzt müssen Sie nur noch Ihre Pipeline testen, um zu sehen, ob sie wie erwartet funktioniert. Vorher sollten Sie Ihrem Entwurf einen Namen geben und ihn speichern, damit Ihr Fortschritt nicht verloren geht.
-
Klicken Sie nun im Menü oben rechts auf Speichern. Sie werden aufgefordert, einen Namen und eine Beschreibung für die Pipeline einzugeben.
- Geben Sie
ETL-batch-pipeline als Namen der Pipeline ein.
- Geben Sie
ETL-Pipeline zum Parsen von CSV-Dateien, Transformieren und Schreiben der Ausgabe in BigQuery als Beschreibung ein.
-
Klicken Sie anschließend auf Speichern.
-
Klicken Sie zum Testen der Pipeline auf das Symbol Vorschau. In der Symbolleiste wird jetzt ein Ausführungssymbol angezeigt. Klicken Sie darauf, um die Pipeline im Vorschaumodus auszuführen.
-
Klicken Sie auf das Symbol Ausführen. Während die Pipeline im Vorschaumodus ausgeführt wird, werden keine Daten in die BigQuery-Tabelle geschrieben. Sie können aber prüfen, ob die Daten richtig gelesen und wie erwartet geschrieben werden, sobald die Pipeline bereitgestellt ist. Der Button „Vorschau“ ist ein Schalter. Wenn Sie die Vorschau beenden möchten, klicken Sie einfach noch einmal darauf.
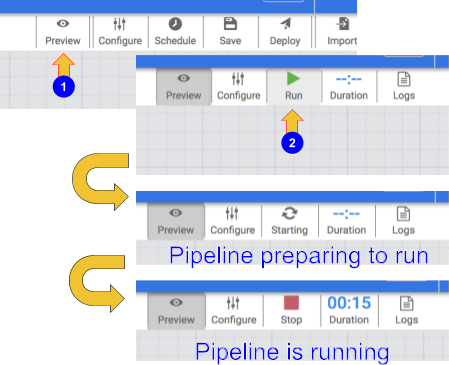
-
Wenn die Pipeline ausgeführt wurde, bewegen Sie den Mauszeiger auf den Knoten Wrangler und klicken Sie auf Attribute. Klicken Sie dann auf den Tab Vorschau. Wenn alles geklappt hat, sollten Sie die Rohdaten sehen, die von der Eingabe, dem Knoten links, stammen, und die geparsten Datensätze, die als Ausgabe an den Knoten rechts ausgegeben werden. Klicken Sie oben rechts im Feld „Attribute“ auf X, um es zu schließen.
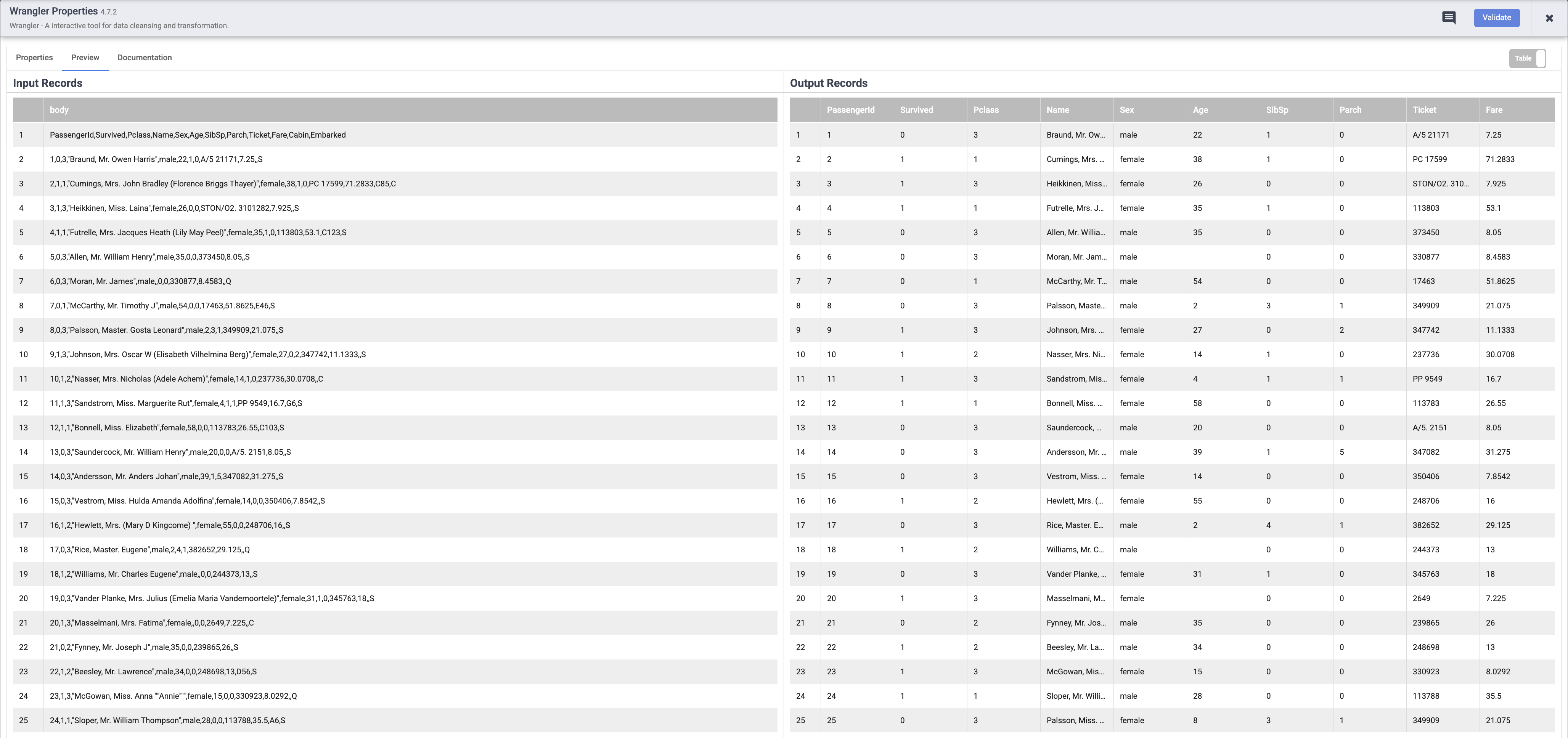
Hinweis: Jeder Knoten, der Daten verarbeitet, sollte eine ähnliche Ausgabe liefern. So können Sie Ihre Arbeit überprüfen und dafür sorgen, dass Sie auf dem richtigen Weg sind, bevor Sie Ihre Pipeline bereitstellen. Wenn Fehler auftreten, können Sie diese im Entwurfsmodus ganz einfach beheben.
-
Klicken Sie noch einmal auf das Symbol Vorschau, um den Vorschaumodus zu beenden.
-
Wenn alles in Ordnung ist, können Sie die Pipeline bereitstellen. Klicken Sie oben rechts auf das Symbol Bereitstellen  , um die Pipeline bereitzustellen.
, um die Pipeline bereitzustellen.
Es wird ein Dialogfeld zur Bestätigung angezeigt, dass Ihre Pipeline bereitgestellt wird:
-
Nachdem Ihre Pipeline erfolgreich bereitgestellt wurde, können Sie Ihre ETL-Pipeline ausführen und Daten in BigQuery laden.
-
Klicken Sie auf das Symbol Ausführen, um den ETL-Job auszuführen.
-
Wenn die Pipeline erfolgreich ausgeführt wurde, ändert sich der Status in Erfolgreich.

-
Während die Daten von der Pipeline verarbeitet werden, gibt jeder Knoten in der Pipeline Messwerte aus, die angeben, wie viele Datensätze verarbeitet wurden.
Beim Parsing-Vorgang werden 892 Datensätze angezeigt, in der Quelle waren es aber 893. Was ist passiert? Der Parsing-Vorgang hat die erste Zeile verwendet, um die Spaltenüberschriften festzulegen. Die verbleibenden 892 Datensätze wurden verarbeitet.

Klicken Sie auf Fortschritt prüfen.
Batchpipeline bereitstellen und ausführen
Aufgabe 7: Ergebnisse aufrufen
Die Pipeline schreibt die Ausgabe in eine BigQuery-Tabelle. Sie können dies mit den folgenden Schritten überprüfen.
-
Öffnen Sie in einem neuen Tab die BigQuery-UI in der Cloud Console oder rechtsklicken Sie auf den Console-Tab und wählen Sie Duplizieren aus. Wählen Sie dann im Navigationsmenü die Option BigQuery aus. Wenn Sie dazu aufgefordert werden, klicken Sie auf Weiter.
-
Klicken Sie im linken Bereich im Abschnitt Klassischer Explorer auf Ihre Projekt-ID (beginnt mit qwiklabs).
-
Klicken Sie im Dataset demo in Ihrem Projekt auf die Tabelle titanic und dann auf + (SQL-Abfrage). Führen Sie eine einfache Abfrage aus, z. B.:
SELECT * FROM `demo.titanic` LIMIT 10
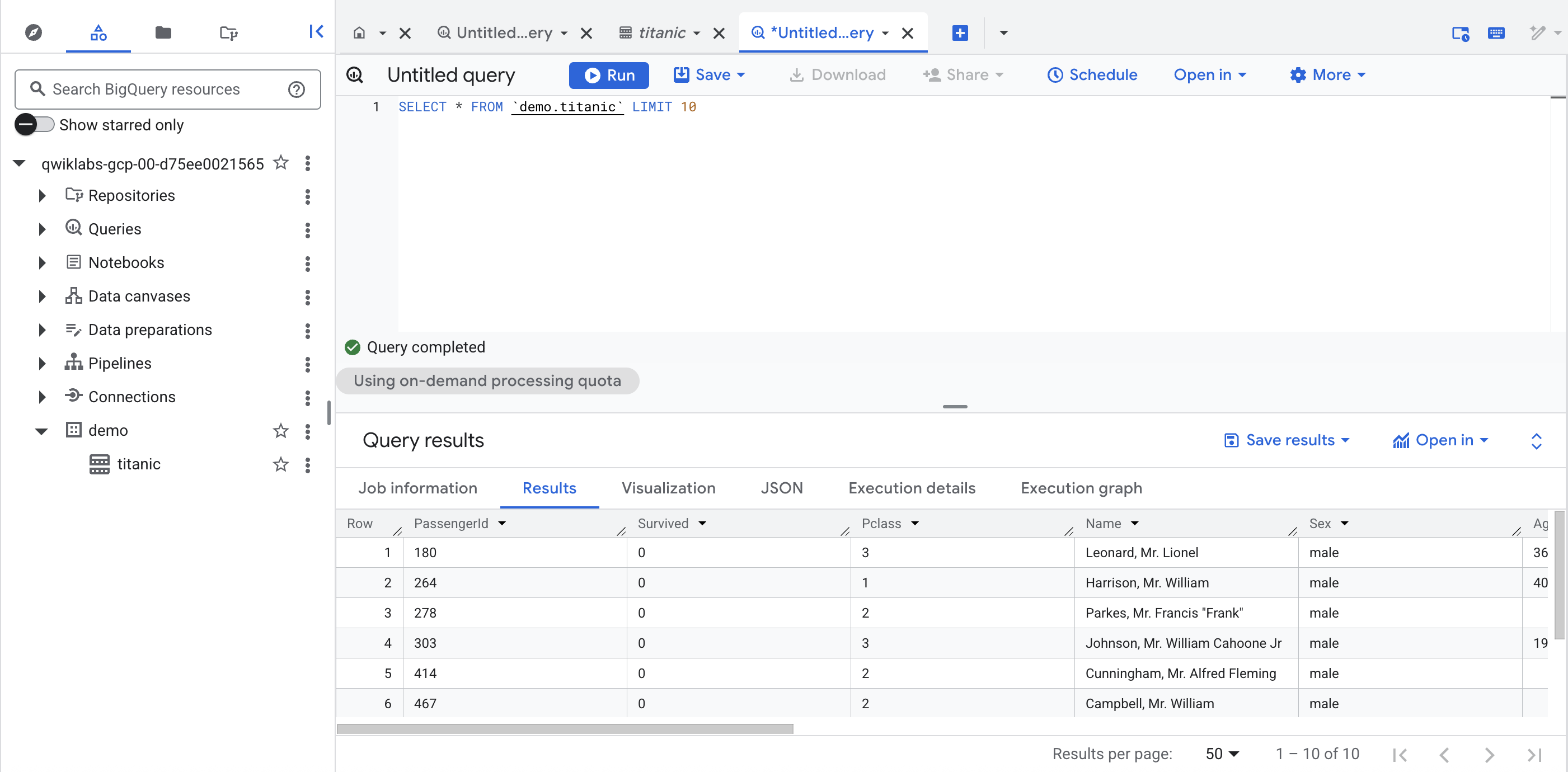
Klicken Sie auf Fortschritt prüfen.
Ergebnisse ansehen
Glückwunsch!
Sie haben gelernt, wie Sie mit den Bausteinen, die in Pipeline Studio von Cloud Data Fusion verfügbar sind, eine Batch-Pipeline erstellen. Außerdem haben Sie gelernt, wie Sie mit Wrangler Transformationsschritte für Ihre Daten erstellen.
Nächstes Lab absolvieren
Fahren Sie mit Transformationen erstellen und Daten mit Wrangler in Cloud Data Fusion vorbereiten fort.
Anleitung zuletzt am 27. Januar 2026 aktualisiert
Lab zuletzt am 27. Januar 2026 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.






