Add Cloud Data Fusion API Service Agent role to service account
Verificar meu progresso
/ 25
Deploy a sample pipeline
Verificar meu progresso
/ 25
View the result
Verificar meu progresso
/ 25
Create a cloud data fusion instance
Verificar meu progresso
/ 25
Add Cloud Data Fusion API Service Agent role to service account
Verificar meu progresso
/ 25
Deploy a sample pipeline
Verificar meu progresso
/ 25
View the result
Verificar meu progresso
/ 25
Este laboratório pode incorporar ferramentas de IA para ajudar no seu aprendizado.
Visão geral
Neste laboratório, você vai aprender a criar uma instância do Data Fusion e implantar um pipeline de amostra fornecido.
O pipeline lê um arquivo JSON contendo dados de best-sellers do NYT do Cloud Storage. O pipeline executa transformações no arquivo para analisar e limpar os dados. Por fim, carrega um subconjunto dos registros no BigQuery.
Objetivos
Neste laboratório, você vai aprender a:
Criar uma instância do Data Fusion
Implantar um pipeline de amostra que executa algumas transformações em um arquivo JSON e filtra os resultados correspondentes no BigQuery
Configuração
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Como iniciar seu laboratório e fazer login no console do Google Cloud
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
O botão Abrir Console do Google Cloud
O tempo restante
As credenciais temporárias que você vai usar neste laboratório
Outras informações, se forem necessárias
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
Clique em Próxima.
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
Acesse as próximas páginas:
Aceite os Termos e Condições.
Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ().
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No Console do Google Cloud, acesse o menu de navegação () e clique em IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.
Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
No card Informações do projeto, copie o Número do projeto.
No Menu de navegação, clique em IAM e administrador > IAM.
Na parte superior da página IAM, clique em Adicionar.
Substitua {project-number} pelo número do seu projeto.
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
Clique em Salvar.
Tarefa 1: ativar a API Cloud Data Fusion
No console do Cloud, acesse Menu de navegação () e clique em APIs e serviços > Biblioteca.
Na caixa de pesquisa, digite Data Fusion para encontrar a API Cloud Data Fusion e clique no hiperlink.
A API já está ativada. Clique em Gerenciar e depois em Desativar API. Confirme Desativar.
Depois que a API for desativada, clique em Ativar para reativá-la.
Tarefa 2: criar uma instância do Cloud Data Fusion
No console do Google Cloud, acesse o Menu de navegação () e clique em Ver todos os produtos. Em Analytics, clique em Fusão de dados.
Clique no link Criar uma instância na parte de cima da seção para criar uma instância do Cloud Data Fusion.
Na página Criar instância do Data Fusion que é carregada:
a. Insira um nome para a instância (como cdf-lab-instance).
b. Em Região, selecione us-central1.
c. Em Edição, selecione Basic
d. Na seção Autorização, clique em Conceder permissão, se necessário.
e. Clique no ícone de menu suspenso ao lado de Opções avançadas, em Monitoramento e geração de registros avançados, marque a caixa de seleção Geração de registros do Cloud Managed Service for Spark.
f. Deixe os outros campos como estão e clique em Criar.
Clique em Verificar meu progresso para conferir o objetivo.
Criar uma instância do Cloud Data Fusion
Observação: a criação da instância leva cerca de 10 minutos. Enquanto espera, assista esta apresentação sobre o Cloud Data Fusion do Next '19, começando no minuto 15:31. Volte e confira sua instância de vez em quando. Você pode terminar de assistir ao vídeo depois que o laboratório for concluído.
Observação : este laboratório tem um limite de tempo, e você vai perder seu progresso quando o tempo acabar.
Em seguida, conceda permissões à conta de serviço associada à instância, de acordo com as etapas a seguir.
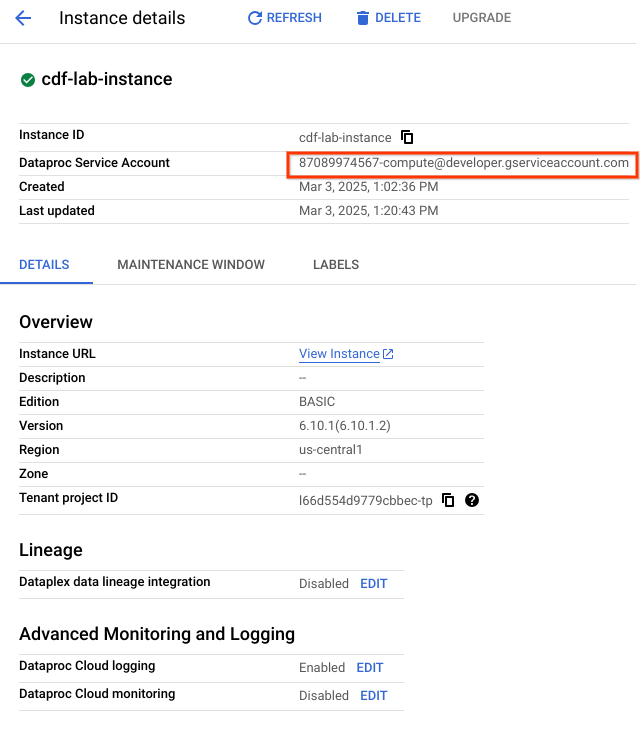
Clique no nome da instância. Na página "Detalhes da instância", copie a Conta de serviço do Managed Service for Spark para a área de transferência.
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Na página de permissões do IAM, clique em +Conceder acesso.
No campo "Novos principais", cole a conta de serviço do Managed Service for Spark.
Clique no campo "Selecionar um papel", digite Agente de serviço da API Cloud Data Fusion e selecione essa opção.
Clique em Salvar.
Clique em Verificar meu progresso para conferir o objetivo.
Adicionar um papel de agente de serviço da API Cloud Data Fusion à conta de serviço
Tarefa 3: navegar pela interface do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o console do Cloud e a interface separada do Cloud Data Fusion.
No console do Cloud, é possível criar e excluir instâncias do Cloud Data Fusion e visualizar os detalhes da instância do Cloud Data Fusion.
Na interface da web do Cloud Data Fusion, é possível usar as várias páginas, como o Pipeline Studio ou o Wrangler, para acessar a funcionalidade do Cloud Data Fusion.
Para navegar na interface do Cloud Data Fusion, siga estas etapas:
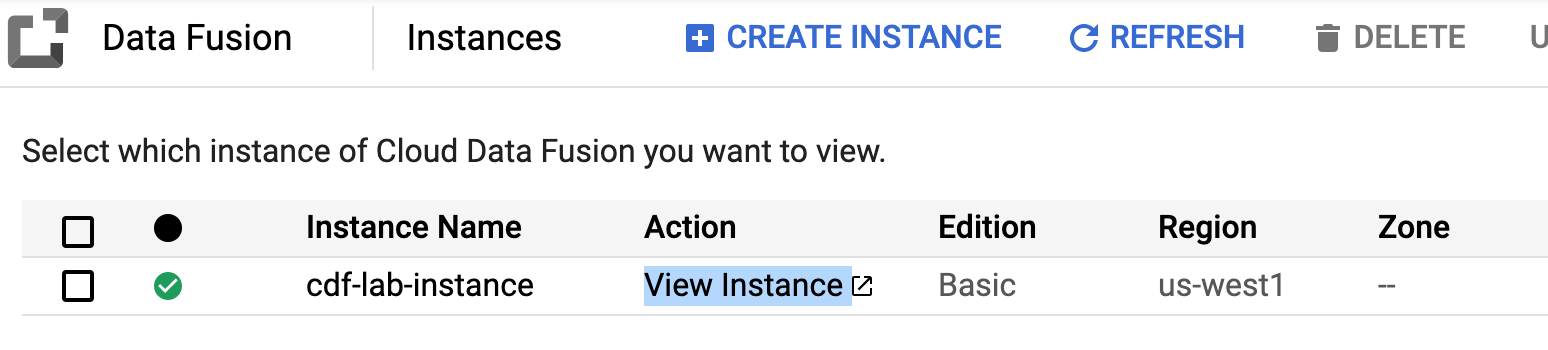
No console do Google Cloud, acesse o Menu de navegação () e clique em Ver todos os produtos. Em Analytics, clique em Fusão de dados.
Clique no link Exibir instância próximo da instância do Data Fusion. Selecione suas credenciais do laboratório para fazer login e, se necessário, marque a caixa de seleção ao lado de Gerenciar seus dados do Google Service Control. Clique em Continuar.
Se o serviço oferecer um tour, clique em Cancelar. Agora você está usando a interface do Cloud Data Fusion.
A interface da web do Cloud Data Fusion tem o próprio painel de navegação à esquerda para navegar até a página necessária.
Tarefa 4: implantar um pipeline de amostra
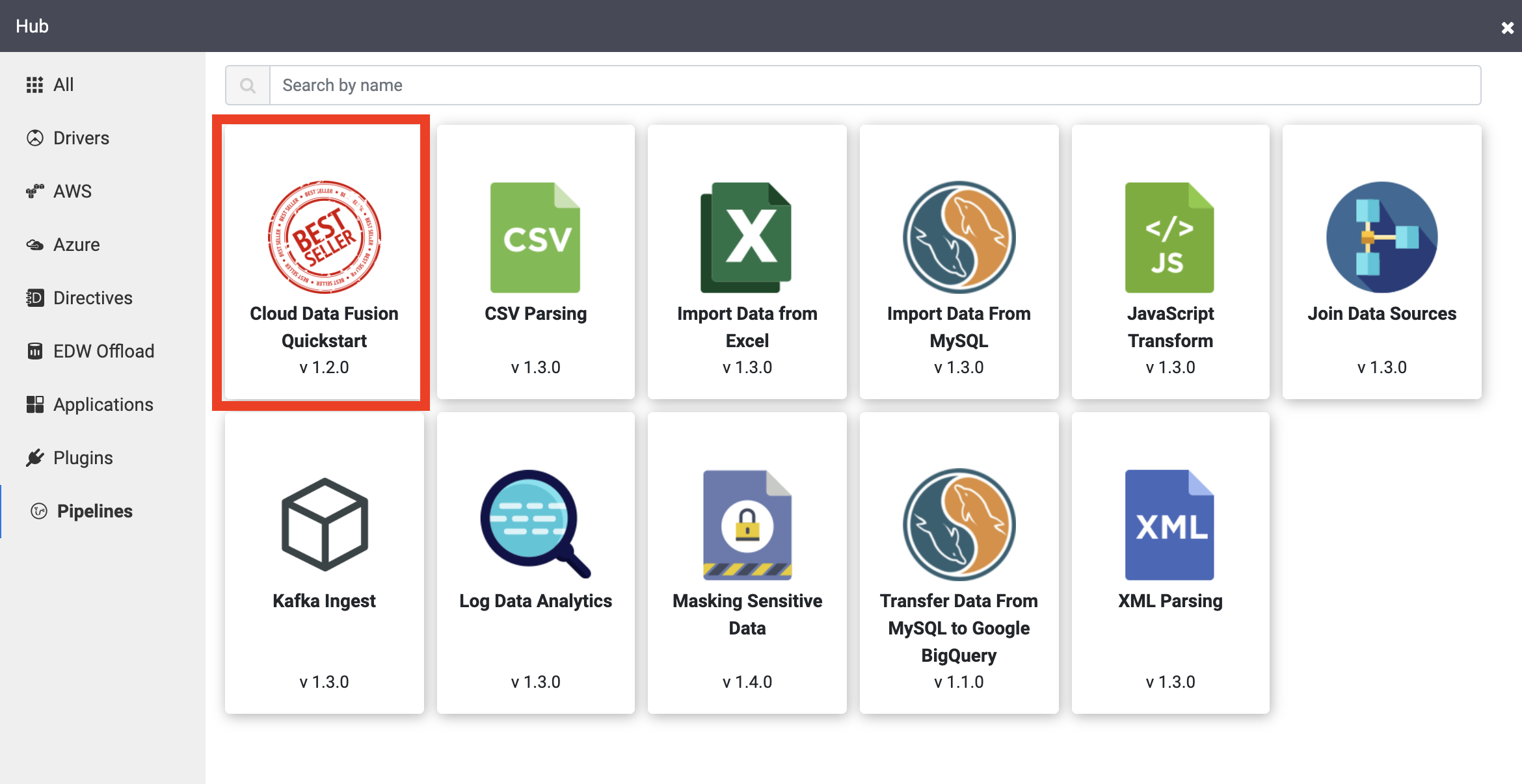
Os canais de amostra estão disponíveis usando o Hub do Cloud Data Fusion, que permite compartilhar soluções, plug-ins e pipelines reutilizáveis do Cloud Data Fusion.
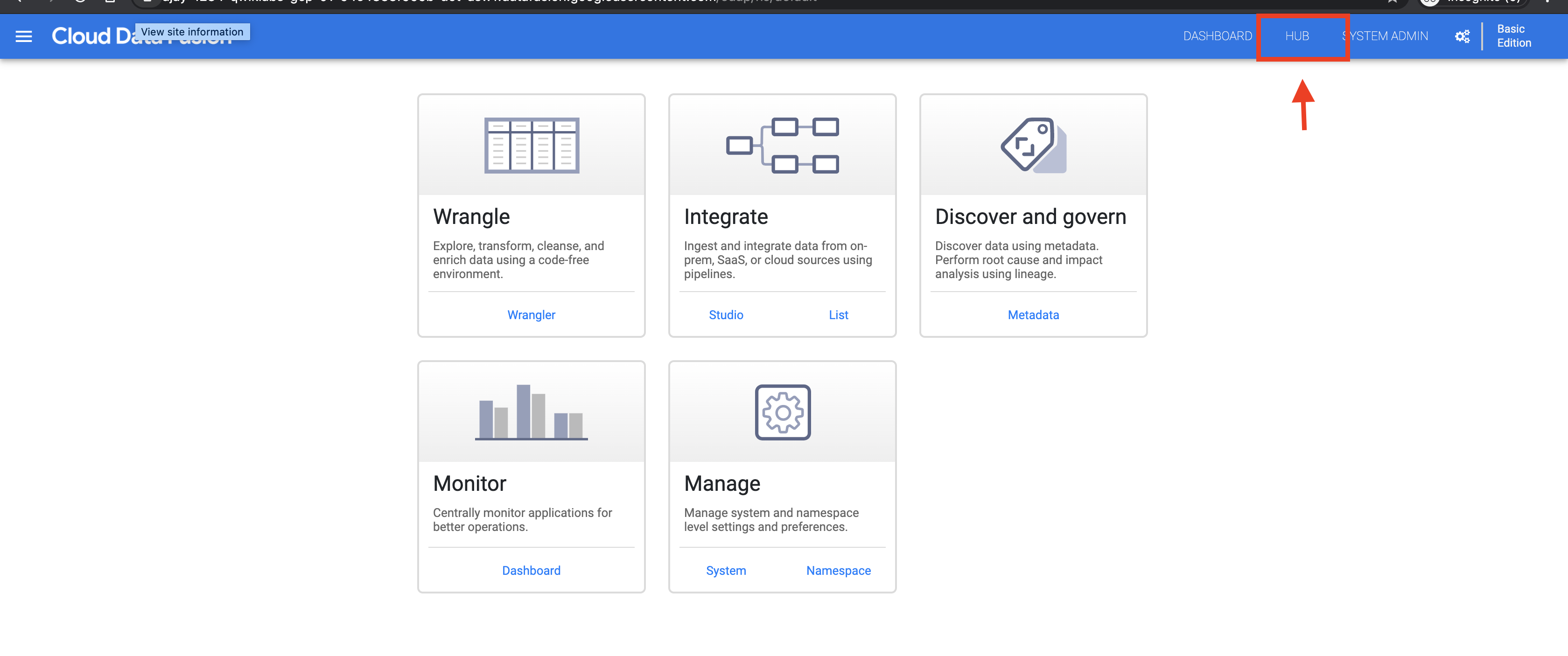
Na interface da web do Cloud Data Fusion, clique em HUB no canto superior direito.
No painel esquerdo, clique em Pipelines.
Clique no pipeline do Guia de início rápido do Cloud Data Fusion e depois em Criar no pop-up que aparece.
No painel de configuração do Guia de início rápido do Cloud Data Fusion, clique em Concluir.
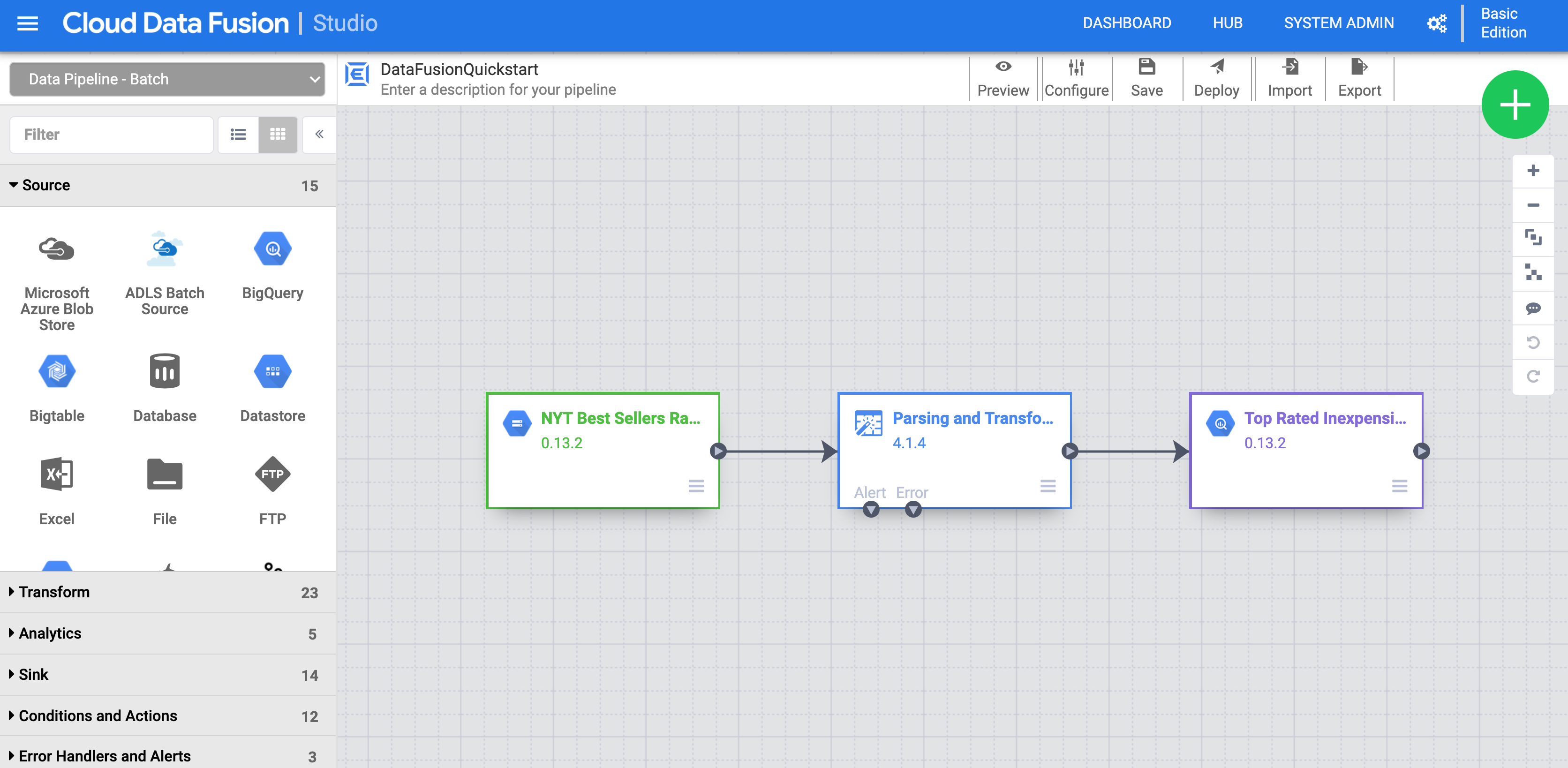
Clique em Personalizar pipeline. Uma representação visual do pipeline é exibida no Pipeline Studio, que é uma interface gráfica para desenvolver pipelines de integração de dados. Os plug-ins de pipeline disponíveis estão listados à esquerda, e o pipeline é exibido na área da tela. Para explorar o pipeline, mantenha o ponteiro sobre cada nó do pipeline e clique no botão Propriedades exibido. O menu de propriedades de cada nó permite visualizar os objetos e as operações associadas ao nó.
Observação : um nó em um pipeline é um objeto conectado em uma sequência para produzir um gráfico acíclico dirigido. Por exemplo, origem, coletor, transformação, ação etc.
No menu superior direito, clique em Implantar. Isso envia o pipeline para o Cloud Data Fusion. Você vai executar o pipeline na próxima seção.
Tarefa 5: visualizar o pipeline
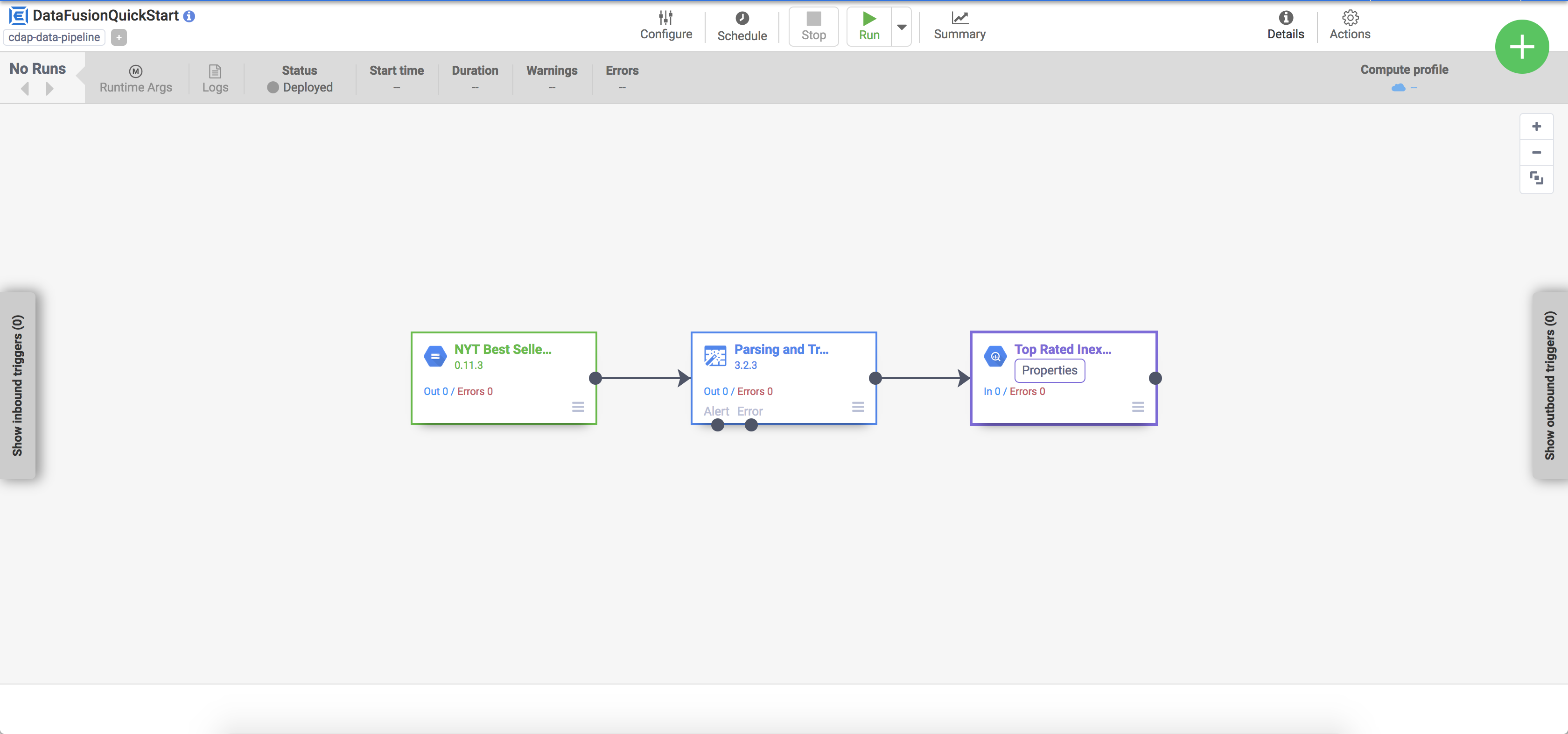
O pipeline implantado aparece na visualização de detalhes do pipeline, onde é possível fazer o seguinte:
Visualizar a estrutura e configuração do pipeline.
Executar o pipeline manualmente ou configurar uma programação ou um gatilho.
Ver um resumo das execuções históricas do pipeline, incluindo ambientes de execução, registros e métricas.
Tarefa 6: executar o pipeline
Na visualização de detalhes do pipeline, clique em Executar na parte superior central para executar o pipeline.
Observação: quando você executar um pipeline, o Cloud Data Fusion provisiona um cluster temporário do Managed Service for Spark, executa o pipeline no cluster usando o Apache Hadoop MapReduce ou Apache Spark e exclui o cluster. Quando o pipeline muda para o estado Em execução, é possível monitorar a criação e a exclusão do cluster do Managed Service for Spark. Esse cluster existe apenas enquanto o pipeline durar.
Observação: se o status do pipeline falhar, execute-o novamente.
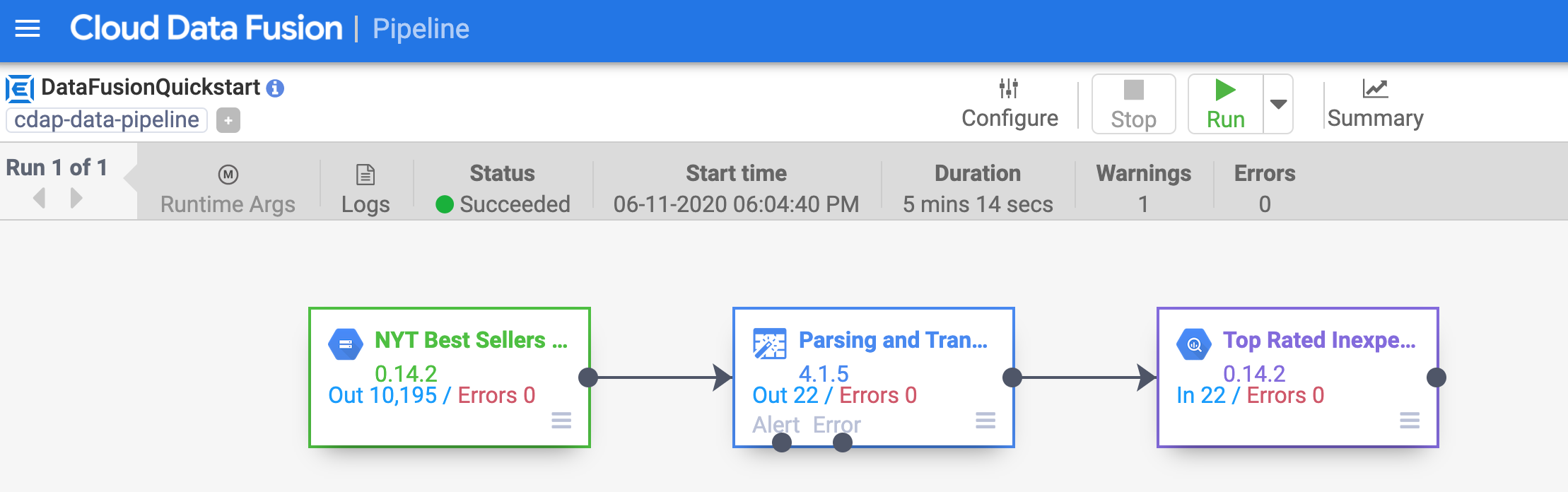
Após alguns minutos, o pipeline é concluído. O status do pipeline muda para Concluído e o número de registros processados por cada nó é exibido.
Clique em Verificar meu progresso para conferir o objetivo.
Implantar e executar um pipeline de amostra
Tarefa 7: conferir os resultados
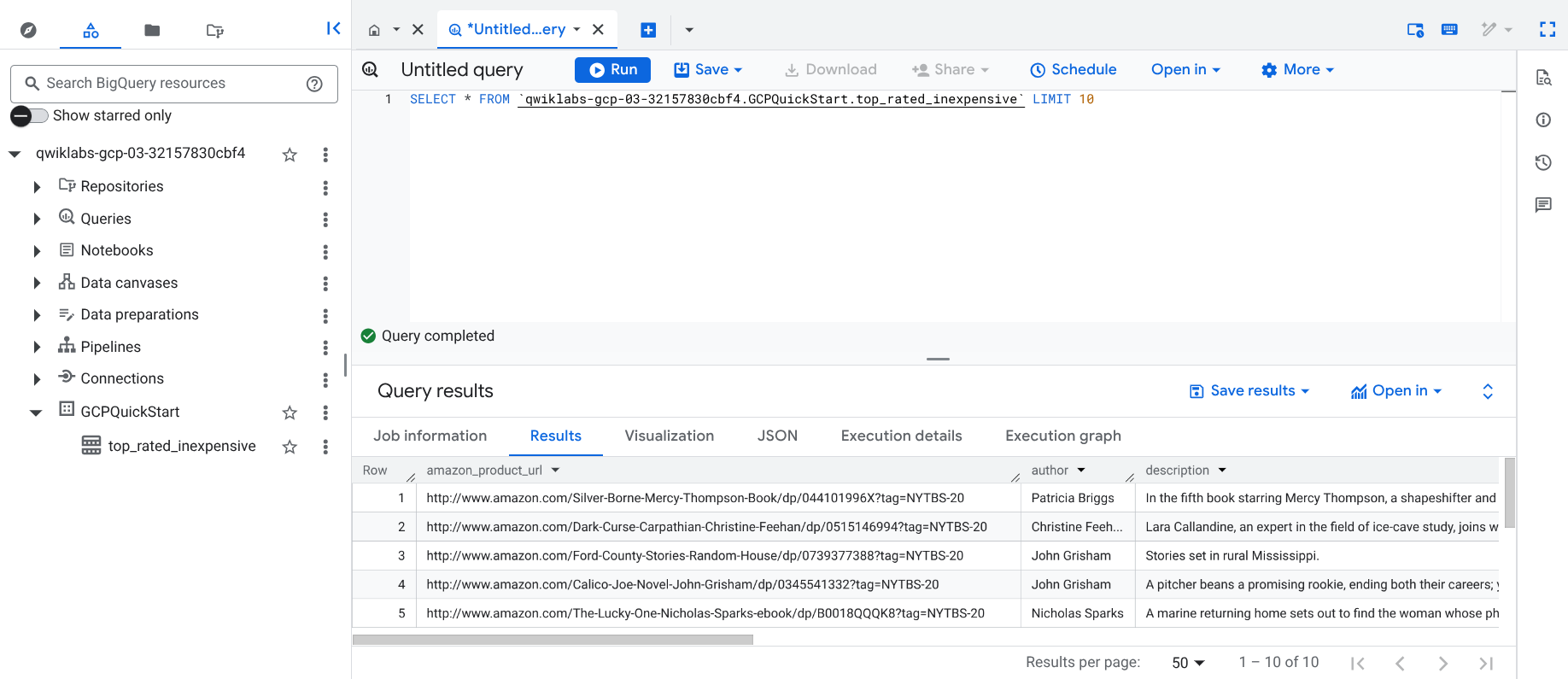
O pipeline grava a saída em uma tabela do BigQuery. Você pode verificar isso seguindo estas etapas.
No painel Análises clássicas, clique no ID do projeto (que começa com qwiklabs).
No conjunto de dados GCPQuickstart do projeto, clique na tabela top_rated_inexpensive.
Clique em + Consulta SQL, cole a consulta abaixo e clique em Executar.
SELECT * FROM `{{{project_0.project_id | "PROJECT_ID"}}}.GCPQuickStart.top_rated_inexpensive` LIMIT 10
Aguarde a conclusão da consulta. Uma página de resultados semelhante vai aparecer.
Clique em Verificar meu progresso para conferir o objetivo.
Conferir o resultado
Parabéns!
Neste laboratório, você aprendeu a criar uma instância do Data Fusion e implantar um pipeline de amostra que lê um arquivo de entrada do Cloud Storage, além de transrformar e filtrar os dados para gerar um subconjunto dos dados no BigQuery.
Finalize o laboratório
Após concluir o laboratório, clique em Terminar o laboratório. O Google Skills remove os recursos usados e limpa a conta para você.
Você poderá classificar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Manual atualizado em 17 de dezembro de 2025
Laboratório testado em 17 de dezembro de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Antes de começar
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender a criar uma instância do Data Fusion e implantar um pipeline de amostra
Duração:
Configuração: 1 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 90 minutos


 ).
).
 ) e clique em IAM e administrador > IAM.
) e clique em IAM e administrador > IAM.