Add Cloud Data Fusion API Service Agent role to service account
Fortschritt prüfen
/ 25
Deploy a sample pipeline
Fortschritt prüfen
/ 25
View the result
Fortschritt prüfen
/ 25
Create a cloud data fusion instance
Fortschritt prüfen
/ 25
Add Cloud Data Fusion API Service Agent role to service account
Fortschritt prüfen
/ 25
Deploy a sample pipeline
Fortschritt prüfen
/ 25
View the result
Fortschritt prüfen
/ 25
Dieses Lab kann KI-Tools enthalten, die den Lernprozess unterstützen.
Übersicht
In diesem Lab erfahren Sie, wie Sie eine Data Fusion-Instanz erstellen und eine zur Verfügung gestellte Beispielpipeline bereitstellen.
Die Pipeline liest eine JSON-Datei mit Daten zu NYT-Bestsellern aus Cloud Storage. Die Pipeline führt dann Transformationen an der Datei aus, um die Daten zu analysieren und zu bereinigen. Schließlich wird eine Teilmenge der Datensätze in BigQuery geladen.
Ziele
Aufgaben in diesem Lab:
Data Fusion-Instanz erstellen
Eine Beispielpipeline bereitstellen, die einige Transformationen an einer JSON-Datei ausführt, und übereinstimmende Ergebnisse in BigQuery herausfiltern
Einrichtung
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
Melden Sie sich über ein Inkognitofenster bei Google Skills an.
Beachten Sie die Zugriffszeit (z. B. 1:15:00). Das Lab muss in dieser Zeit abgeschlossen werden.
Es gibt keine Pausenfunktion. Sie können bei Bedarf neu starten, müssen dann aber von vorn beginnen.
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Notieren Sie sich Ihre Anmeldedaten (Nutzername und Passwort). Mit diesen Daten melden Sie sich in der Google Cloud Console an.
Klicken Sie auf Google Console öffnen.
Klicken Sie auf Anderes Konto verwenden. Kopieren Sie den Nutzernamen und das Passwort für dieses Lab und fügen Sie beides in die entsprechenden Felder ein.
Wenn Sie andere Anmeldedaten verwenden, tritt ein Fehler auf oder es fallen Kosten an.
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen.
Lab starten und bei der Google Cloud Console anmelden
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
Schaltfläche „Google Cloud Console öffnen“
Restzeit
Temporäre Anmeldedaten für das Lab
Ggf. weitere Informationen für dieses Lab
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
Klicken Sie auf Weiter.
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
Klicken Sie sich durch die nachfolgenden Seiten:
Akzeptieren Sie die Nutzungsbedingungen.
Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.
Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Cloud Shell bietet Ihnen Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen. gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
Klicken Sie in der Google Cloud Console im Navigationsbereich auf Cloud Shell aktivieren ().
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:
Bevor Sie mit der Arbeit in Google Cloud beginnen, müssen Sie sicherstellen, dass für Ihr Projekt im Rahmen von Identity and Access Management (IAM) die nötigen Berechtigungen vorliegen.
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf IAM und Verwaltung > IAM.
Prüfen Sie, ob das standardmäßige Compute-Dienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden und ihm die Rolle Bearbeiter zugewiesen ist. Das Kontopräfix ist die Projektnummer. Sie finden sie im Navigationsmenü unter Cloud-Übersicht.
Wenn das Konto nicht in IAM vorhanden ist oder nicht über die Bearbeiter-Rolle verfügt, weisen Sie die erforderliche Rolle so zu:
Klicken Sie in der Google Cloud Console im Navigationsmenü auf Cloud-Übersicht.
Kopieren Sie auf der Karte Projektinformationen die Projektnummer.
Klicken Sie im Navigationsmenü auf IAM und Verwaltung > IAM.
Klicken Sie oben auf der Seite IAM auf Hinzufügen.
Ersetzen Sie {project-number} durch die entsprechende Projektnummer.
Wählen Sie unter Rolle auswählen die Option Basic (oder „Projekt“) > Editor aus.
Klicken Sie auf Speichern.
Aufgabe 1: Cloud Data Fusion API aktivieren
Klicken Sie in der Cloud Console im Navigationsmenü () auf APIs & Dienste > Bibliothek.
Geben Sie im Suchfeld den Begriff Data Fusion ein, um die Cloud Data Fusion API zu suchen. Klicken Sie dann auf den Hyperlink.
Die API ist bereits aktiviert. Klicken Sie auf Verwalten und dann auf API deaktivieren. Bestätigen Sie Deaktivieren.
Nachdem die API deaktiviert wurde, klicken Sie auf Aktivieren, um sie wieder zu aktivieren.
Aufgabe 2: Cloud Data Fusion-Instanz erstellen
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf Alle Produkte ansehen. Klicken Sie unter Analytics auf Data Fusion.
Klicken Sie oben im Abschnitt auf den Link Instanz erstellen, um eine Cloud Data Fusion-Instanz zu erstellen.
Führen Sie auf der daraufhin angezeigten Seite Data Fusion-Instanz erstellen die folgenden Schritte aus:
a. Geben Sie einen Namen für die Instanz ein (z. B. cdf-lab-instance).
b. Wählen Sie unter Region den Eintrag us-central1 aus.
c. Wählen Sie unter Version die Option Einfach aus.
d. Klicken Sie im Abschnitt Autorisierung auf Berechtigung gewähren, falls erforderlich.
e. Klicken Sie auf das Drop-down-Symbol neben Erweiterte Optionen. Aktivieren Sie unter Erweitertes Monitoring und Logging das Kästchen für Managed Service for Spark Cloud Logging.
f. Lassen Sie alle anderen Felder unverändert und klicken Sie auf Erstellen.
Klicken Sie auf Fortschritt prüfen.
Cloud Data Fusion-Instanz erstellen
Hinweis: Das Erstellen der Instanz dauert etwa 10 Minuten. Während Sie warten, können Sie sich diese Präsentation zu Cloud Data Fusion von der Next '19 ansehen (ab 15:31). Sehen Sie regelmäßig nach der Instanz. Sie können sich den Rest des Videos auch nach Abschluss des Labs ansehen.
Hinweis: Dieses Lab hat ein Zeitlimit. Wenn die Zeit abläuft, gehen Ihre Änderungen verloren.
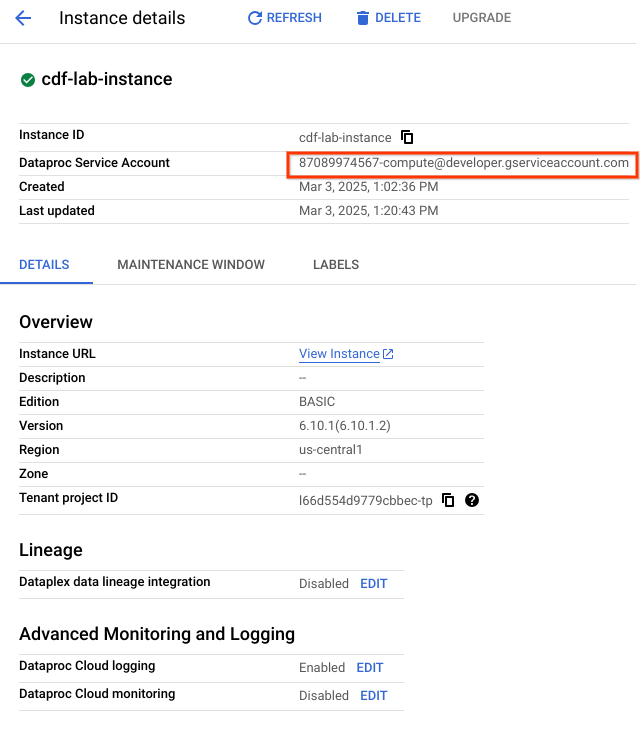
Als Nächstes gewähren Sie dem Dienstkonto, das der Instanz zugeordnet ist, Berechtigungen. Gehen Sie dazu so vor:
Klicken Sie auf den Instanznamen. Kopieren Sie auf der Seite „Instanzdetails“ das Managed Service for Spark-Dienstkonto in die Zwischenablage.
Klicken Sie in der Cloud Console im Navigationsmenü () auf IAM und Verwaltung > IAM.
Klicken Sie auf der Seite „IAM-Berechtigungen“ auf Zugriff erlauben.
Fügen Sie im Feld „Neue Hauptkonten“ das Managed Service for Spark-Dienstkonto ein.
Klicken Sie in das Feld „Rolle auswählen“ und geben Sie Cloud Data Fusion API-Dienst-Agent ein. Wählen Sie dann die Rolle aus.
Klicken Sie auf Speichern.
Klicken Sie auf Fortschritt prüfen.
Rolle „Cloud Data Fusion API-Dienst-Agent“ zum Dienstkonto hinzufügen
Aufgabe 3: Benutzeroberfläche von Cloud Data Fusion verwenden
Wenn Sie mit Cloud Data Fusion arbeiten, verwenden Sie sowohl die Cloud Console als auch die separate Benutzeroberfläche von Cloud Data Fusion.
In der Cloud Console können Sie Cloud Data Fusion-Instanzen erstellen und löschen sowie Details zu Cloud Data Fusion-Instanzen aufrufen.
In der Benutzeroberfläche von Cloud Data Fusion können Sie auf verschiedenen Seiten wie Pipeline Studio oder Wrangler die Funktionen von Cloud Data Fusion nutzen.
So verwenden Sie die Benutzeroberfläche von Cloud Data Fusion:
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf Alle Produkte ansehen. Klicken Sie unter Analytics auf Data Fusion.
Klicken Sie neben Ihrer Data Fusion-Instanz auf den Link Instanz aufrufen. Wählen Sie die Anmeldedaten des Labs aus, um sich anzumelden. Aktivieren Sie gegebenenfalls das Kästchen neben Verwaltung Ihrer Google Service Control-Daten. Klicken Sie auf Weiter.
Wenn Ihnen eine Tour zum Dienst angeboten wird, klicken Sie auf Abbrechen. Sie sollten sich jetzt in der Cloud Data Fusion-Benutzeroberfläche befinden.
Die Web-Benutzeroberfläche von Cloud Data Fusion hat einen eigenen Navigationsbereich (links), über den Sie die gewünschte Seite aufrufen können.
Aufgabe 4: Beispielpipeline bereitstellen
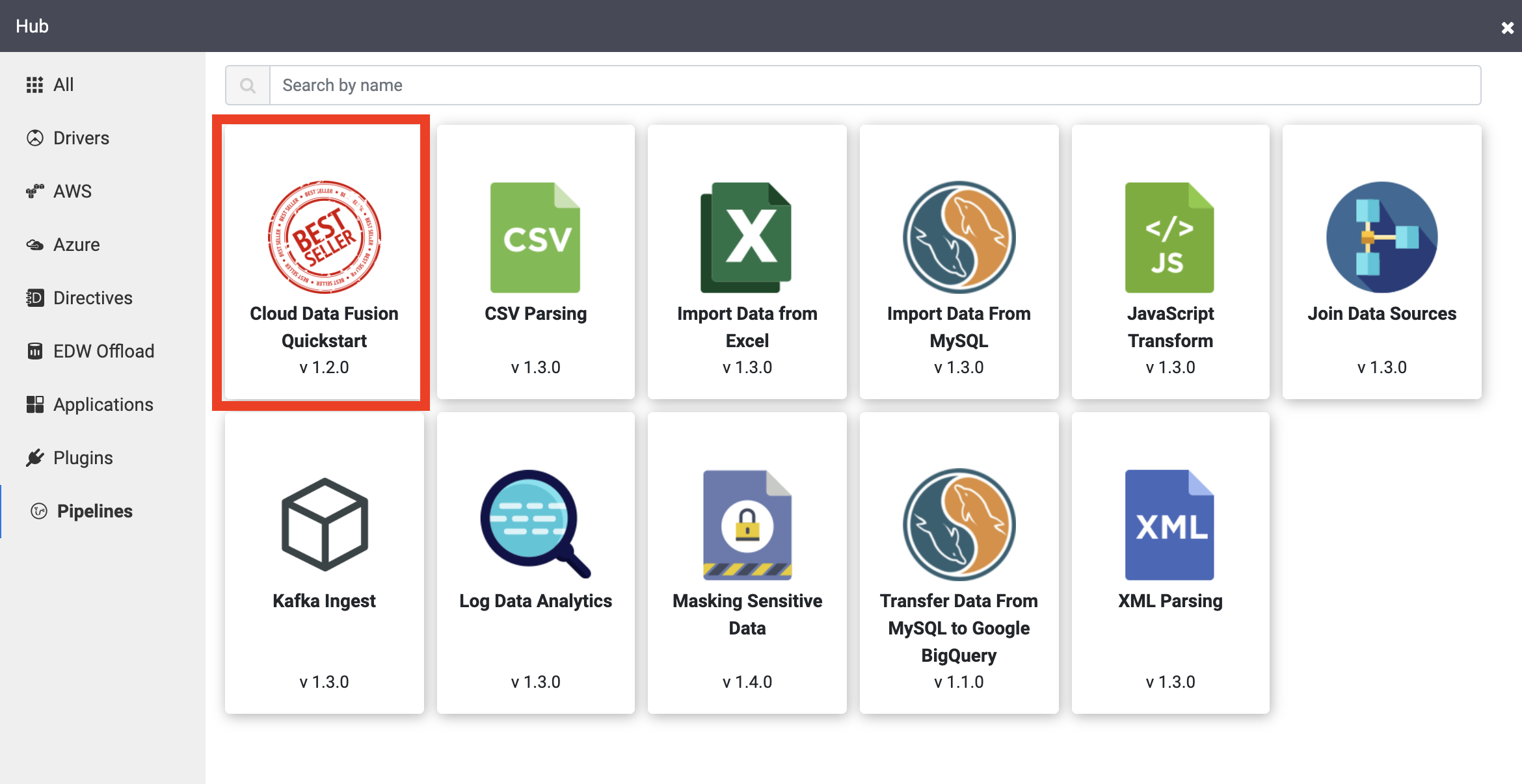
Beispielpipelines sind über den Hub von Cloud Data Fusion verfügbar, über den Sie wiederverwendbare Pipelines, Plug-ins und Lösungen für Cloud Data Fusion teilen können.
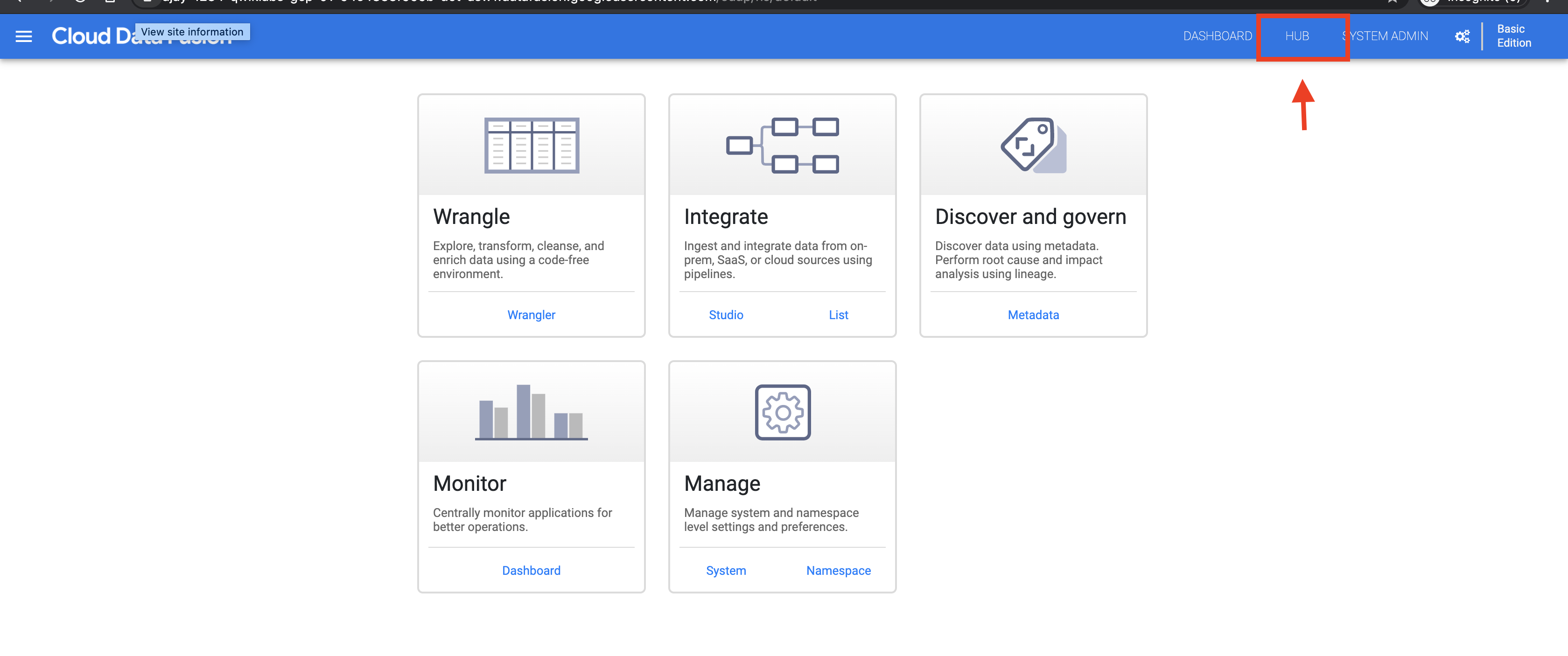
Klicken Sie in der Web-Benutzeroberfläche von Cloud Data Fusion rechts oben auf HUB.
Klicken Sie im linken Bereich auf Pipelines.
Klicken Sie auf die Pipeline Cloud Data Fusion Quickstart und dann im eingeblendeten Pop-up auf Create.
Klicken Sie im Konfigurationsbereich für „Cloud Data Fusion Quickstart“ auf Finish.
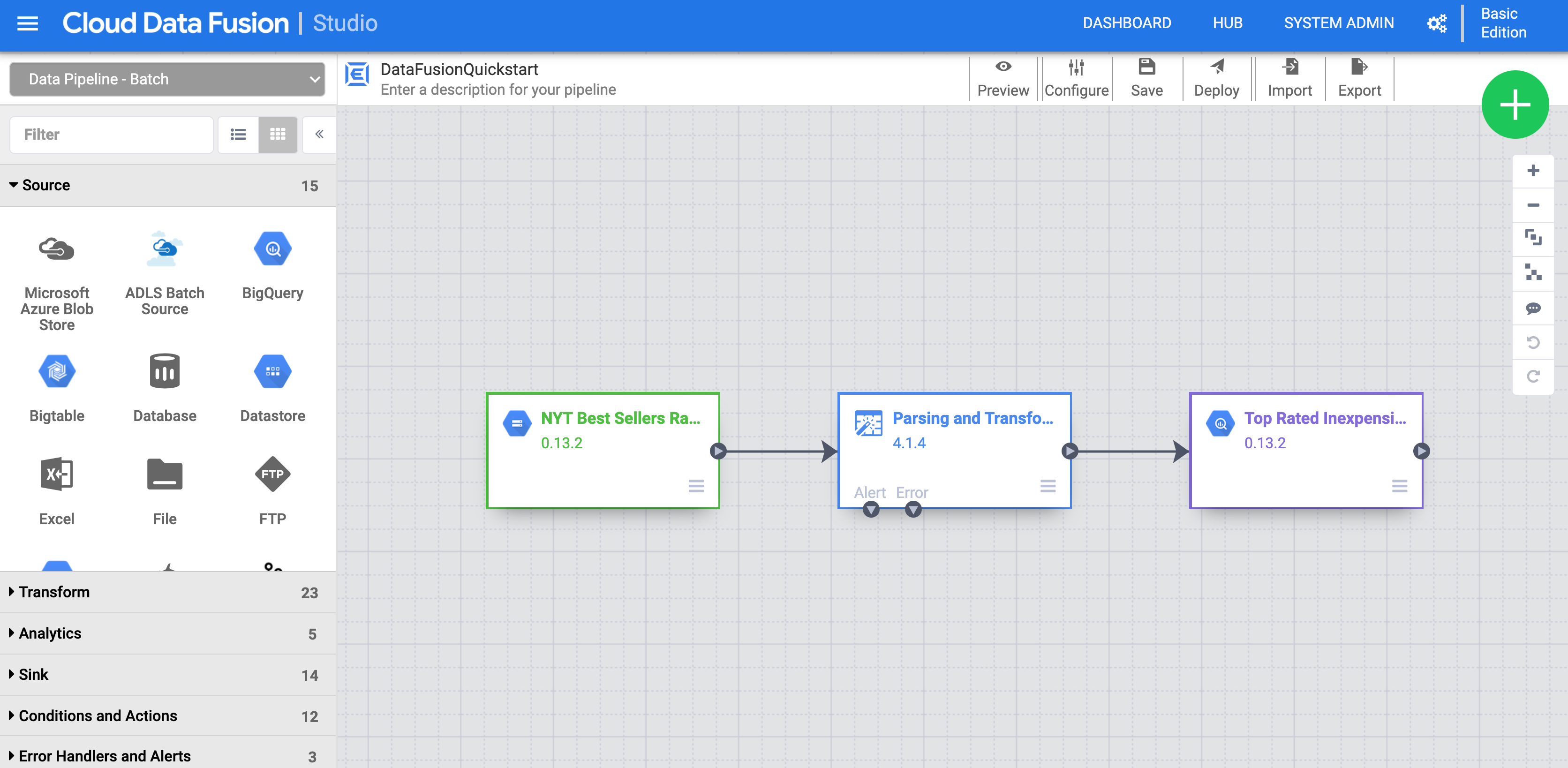
Klicken Sie auf Customize Pipeline. Eine visuelle Darstellung Ihrer Pipeline wird in Pipeline Studio angezeigt. Dies ist eine grafische Benutzeroberfläche zur Entwicklung von Pipelines für die Datenintegration. Auf der linken Seite sind die Pipeline-Plug-ins aufgelistet und Ihre Pipeline wird im Hauptbereich angezeigt. Sie können Ihre Pipeline untersuchen, indem Sie den Mauszeiger auf die einzelnen Knoten der Pipeline bewegen und auf den Button Properties klicken. Über das Menü „Properties“ für jeden Knoten können Sie die mit dem Knoten verknüpften Objekte und Vorgänge aufrufen.
Hinweis:
Ein Knoten in einer Pipeline ist ein Objekt, das in einer Sequenz verbunden ist, um einen gerichteten azyklischen Graphen zu erzeugen. Beispiele: Quelle, Senke, Transformation, Aktion usw.
Klicken Sie im Menü rechts oben auf Deploy. Dadurch wird die Pipeline an Cloud Data Fusion gesendet. Im nächsten Abschnitt führen Sie die Pipeline aus.
Aufgabe 5: Pipeline anzeigen
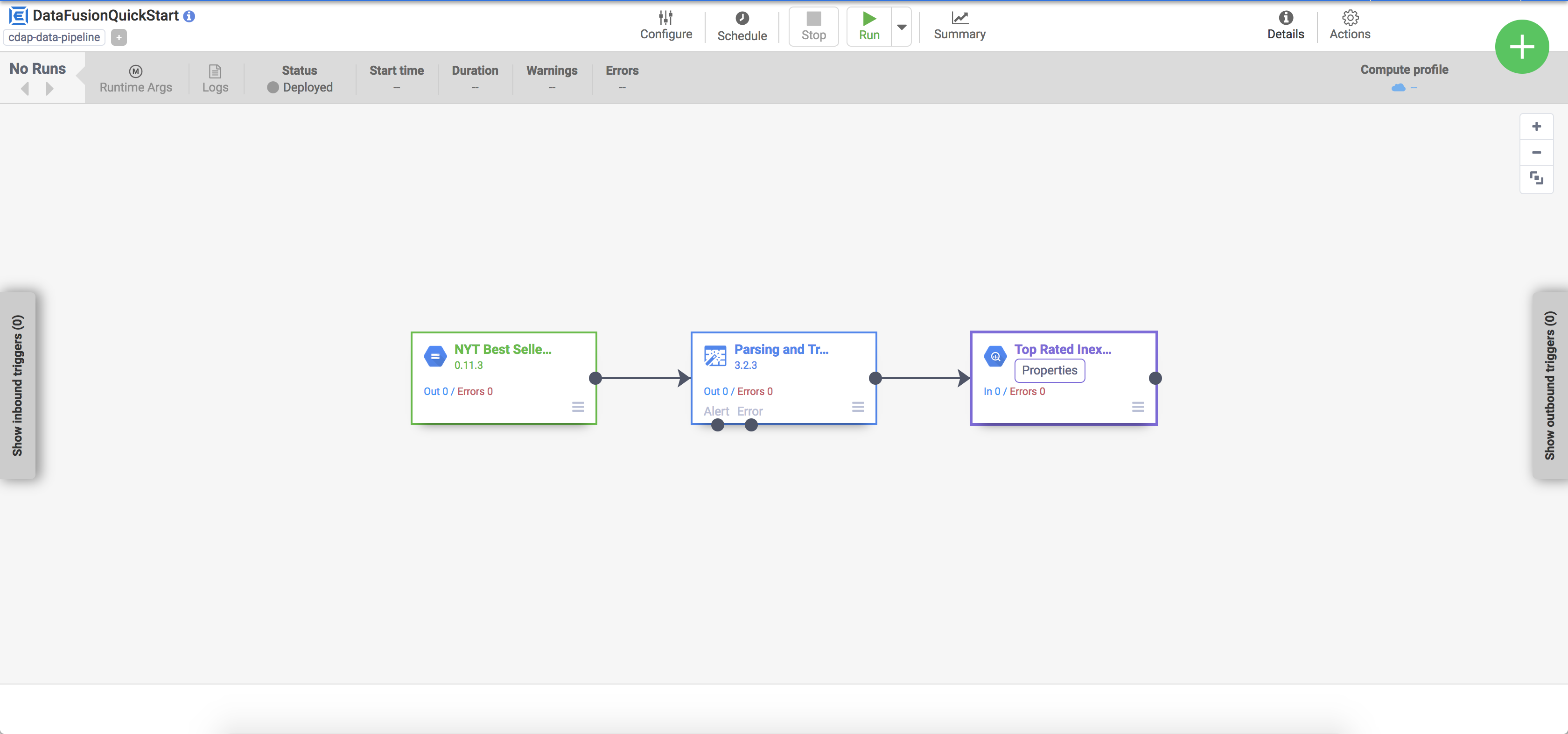
Die bereitgestellte Pipeline wird in der Ansicht der Pipelinedetails angezeigt. Hier können Sie Folgendes tun:
Struktur und Konfiguration der Pipeline anzeigen
Pipeline manuell ausführen oder einen Zeitplan bzw. Trigger einrichten
Eine Zusammenfassung des Ausführungsverlaufs der Pipeline ansehen, einschließlich Ausführungszeiten, Logs und Messwerten
Aufgabe 6: Pipeline ausführen
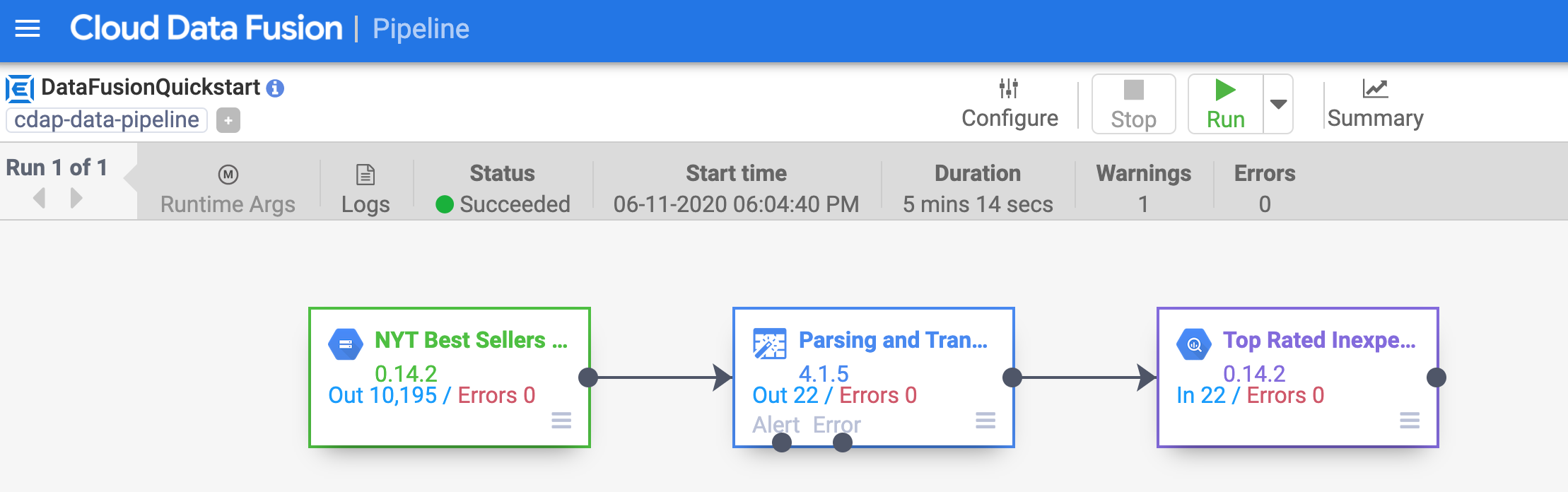
Klicken Sie in der Ansicht der Pipelinedetails oben in der Mitte auf Run, um die Pipeline auszuführen.
Hinweis: Wenn Sie eine Pipeline ausführen, stellt Cloud Data Fusion einen sitzungsspezifischen Managed Service for Spark-Cluster bereit, führt die Pipeline auf dem Cluster mit Apache Hadoop MapReduce oder Apache Spark aus und löscht den Cluster anschließend. Wenn der Status der Pipeline in „Running“ wechselt, können Sie das Erstellen und Löschen des Managed Service for Spark-Clusters beobachten. Dieser Cluster ist nur für die Dauer der Pipeline vorhanden.
Hinweis: Wenn die Pipeline fehlschlägt, führen Sie sie Pipeline noch einmal aus.
Nach einigen Minuten ist die Pipelineausführung abgeschlossen. Der Pipelinestatus ändert sich in Succeeded und die Anzahl der von jedem Knoten verarbeiteten Datensätze wird angezeigt.
Klicken Sie auf Fortschritt prüfen.
Beispielpipeline bereitstellen und ausführen
Aufgabe 7: Ergebnisse aufrufen
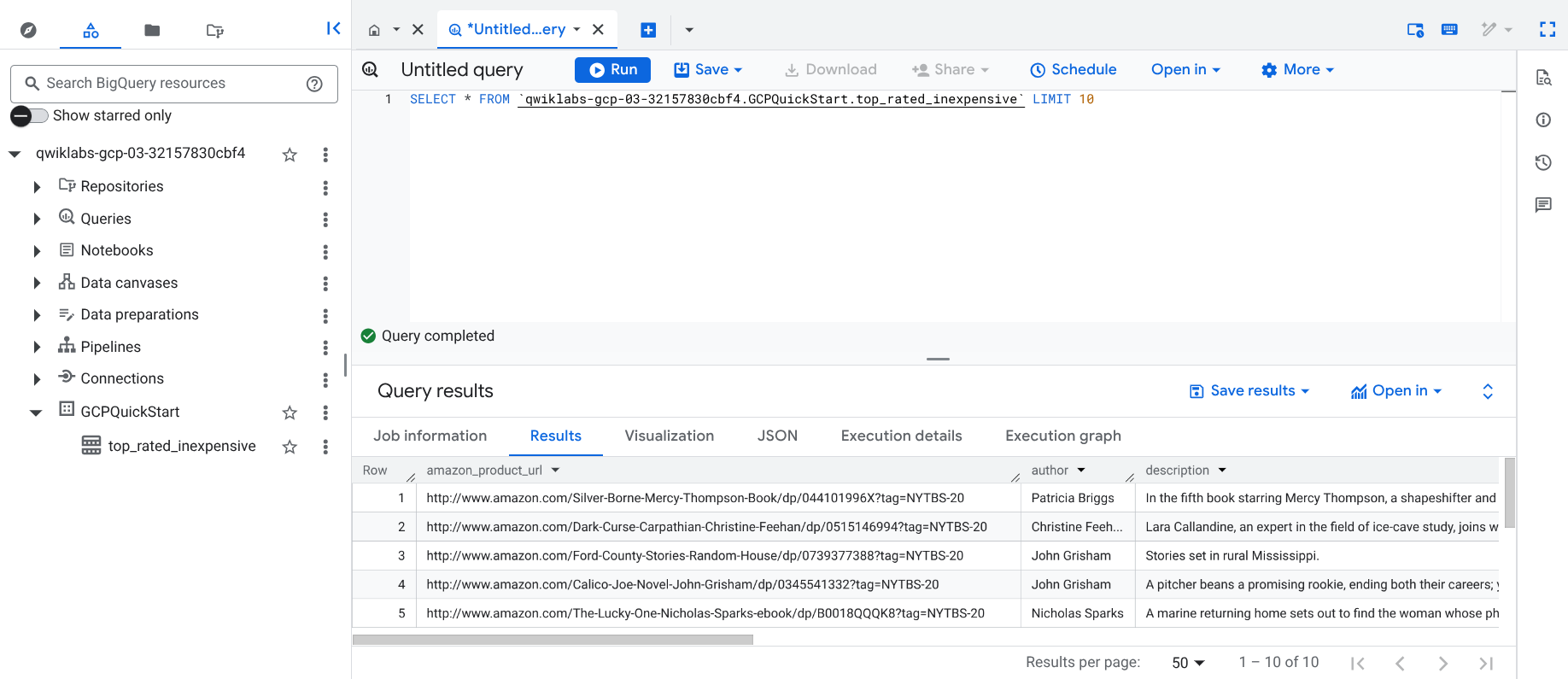
Die Pipeline schreibt die Ausgabe in eine BigQuery-Tabelle. Sie können dies mit den folgenden Schritten überprüfen.
Klicken Sie im Bereich Klassischer Explorer auf Ihre Projekt-ID (beginnt mit qwiklabs).
Klicken Sie unter dem Dataset GCPQuickstart in Ihrem Projekt auf die Tabelle top_rated_inexpensive.
Klicken Sie auf + SQL-Abfrage, fügen Sie die folgende Abfrage ein und klicken Sie auf Ausführen:
SELECT * FROM `{{{project_0.project_id | "PROJECT_ID"}}}.GCPQuickStart.top_rated_inexpensive` LIMIT 10
Warten Sie, bis die Abfrage abgeschlossen ist. Es werden ähnliche Ergebnisse wie diese angezeigt:
Klicken Sie auf Fortschritt prüfen.
Ergebnisse aufrufen
Glückwunsch!
In diesem Lab haben Sie gelernt, wie Sie eine Data Fusion-Instanz erstellen und eine Beispielpipeline bereitstellen, die eine Eingabedatei aus Cloud Storage liest, die Daten transformiert und filtert und eine Teilmenge der Daten in BigQuery ausgibt.
Lab beenden
Wenn Sie das Lab abgeschlossen haben, klicken Sie auf Lab beenden. Google Skills entfernt daraufhin die von Ihnen genutzten Ressourcen und bereinigt das Konto.
Anschließend erhalten Sie die Möglichkeit, das Lab zu bewerten. Wählen Sie die entsprechende Anzahl von Sternen aus, schreiben Sie einen Kommentar und klicken Sie anschließend auf Senden.
Die Anzahl der Sterne hat folgende Bedeutung:
1 Stern = Sehr unzufrieden
2 Sterne = Unzufrieden
3 Sterne = Neutral
4 Sterne = Zufrieden
5 Sterne = Sehr zufrieden
Wenn Sie kein Feedback geben möchten, können Sie das Dialogfeld einfach schließen.
Verwenden Sie für Feedback, Vorschläge oder Korrekturen den Tab Support.
Anleitung zuletzt am 17. Dezember 2025 aktualisiert
Labs erstellen ein Google Cloud-Projekt und Ressourcen für einen bestimmten Zeitraum
Labs haben ein Zeitlimit und keine Pausenfunktion. Wenn Sie das Lab beenden, müssen Sie von vorne beginnen.
Klicken Sie links oben auf dem Bildschirm auf Lab starten, um zu beginnen
Privates Surfen verwenden
Kopieren Sie den bereitgestellten Nutzernamen und das Passwort für das Lab
Klicken Sie im privaten Modus auf Konsole öffnen
In der Konsole anmelden
Melden Sie sich mit Ihren Lab-Anmeldedaten an. Wenn Sie andere Anmeldedaten verwenden, kann dies zu Fehlern führen oder es fallen Kosten an.
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen
Klicken Sie erst auf Lab beenden, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten. Andernfalls werden Ihre bisherige Arbeit und das Projekt gelöscht.
Diese Inhalte sind derzeit nicht verfügbar
Bei Verfügbarkeit des Labs benachrichtigen wir Sie per E-Mail
Sehr gut!
Bei Verfügbarkeit kontaktieren wir Sie per E-Mail
Es ist immer nur ein Lab möglich
Bestätigen Sie, dass Sie alle vorhandenen Labs beenden und dieses Lab starten möchten
Privates Surfen für das Lab verwenden
Am besten führen Sie dieses Lab in einem Inkognito- oder privaten Browserfenster aus. So vermeiden Sie Konflikte zwischen Ihrem privaten Konto und dem Teilnehmerkonto, die zusätzliche Kosten für Ihr privates Konto verursachen könnten.
In diesem Lab erfahren Sie, wie Sie eine Data Fusion-Instanz erstellen und eine Beispielpipeline bereitstellen.


 ).
).
 ) auf IAM und Verwaltung > IAM.
) auf IAM und Verwaltung > IAM.