GSP1281

Visão geral
Proteção de Dados Sensíveis
é um serviço totalmente gerenciado criado para ajudar a descobrir, classificar
e proteger informações sensíveis. As principais opções incluem a descoberta de
dados sensíveis para a caracterização contínua de perfil dos seus dados
sensíveis, a desidentificação de dados sensíveis, incluindo encobrimento, e a
API Cloud Data Loss Prevention (DLP) para permitir a descoberta, inspeção e
desidentificação em cargas de trabalho e aplicativos personalizados.
Imagine que você tem dados brutos no Cloud Storage que contêm dados sensíveis
e quer identificar, proteger e encobrir esses dados antes que os arquivos
sejam usados por usuários finais para análise ou para treinar modelos de
machine learning. A Proteção de Dados Sensíveis pode ajudar.
Neste laboratório, você vai começar ativando a descoberta para o monitoramento
contínuo de dados sensíveis no Cloud Storage. Com base nos resultados da
descoberta, você cria e modifica modelos personalizados e reutilizáveis para
inspeção e desidentificação (encobrimento) de arquivos do Cloud Storage. Por
fim, você usa esses modelos para executar jobs de inspeção e encobrimento mais
detalhados de tipos específicos de dados sensíveis nos seus arquivos do Cloud
Storage.
O que você vai aprender
Neste laboratório, você vai aprender a:
-
Ativar a descoberta para monitoramento contínuo de dados sensíveis em
arquivos do Cloud Storage
-
Criar e modificar modelos reutilizáveis para jobs de inspeção e
desidentificação
- Analisar e interpretar os resultados da descoberta
-
Executar jobs de inspeção e desidentificação com a opção ativada para gravar
os resultados do job no BigQuery
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Tarefa 1: ativar a descoberta para monitoramento contínuo do Cloud Storage
O serviço de descoberta da Proteção de Dados Sensíveis permite identificar
onde na sua organização estão os dados sensíveis e de alto risco. Ao criar uma
configuração de verificação de descoberta, a Proteção de Dados Sensíveis
verifica os recursos selecionados para análise e gera
perfis dos dados, que são um conjunto de insights sobre os
InfoTypes
(tipos de dados sensíveis) identificados e metadados sobre o risco de dados e
o nível de sensibilidade.
Nesta tarefa, você vai criar uma verificação de descoberta para criar perfis
de dados automaticamente em todos os buckets do Cloud Storage no projeto. Como
pode levar algum tempo para que os resultados completos da descoberta sejam
gerados, você recebe destaques e resumos dos principais resultados na última
seção desta tarefa.
Criar e programar uma configuração de verificação
-
No console do Google Cloud, clique no
Menu de navegação ( ) > Segurança.
) > Segurança.
-
Em Proteção de dados, clique em
Proteção de Dados Sensíveis.
-
Clique na guia Descoberta.
-
Em Cloud Storage, clique em Ativar.
-
Em Selecionar um tipo de descoberta, deixe a opção
ativada para Cloud Storage e clique em
Continuar.
-
Em Selecionar escopo, deixe a opção ativada para
Verificar o projeto selecionado e clique em
Continuar.
-
Em Programações gerenciadas, mantenha o padrão e clique
em Continuar.
Neste laboratório, você vai programar a verificação de descoberta para ser
executada imediatamente após a criação, mas há muitas opções para
programar verificações a serem executadas periodicamente (diariamente ou
semanalmente) ou após determinados eventos (como quando um modelo de
inspeção é atualizado).
-
Em Selecionar modelo de inspeção, deixe a opção ativada
para Criar um novo modelo de inspeção. Mantenha os outros
valores como o padrão e clique em Continuar.
Por padrão, o novo modelo de inspeção inclui aproximadamente 80 InfoTypes
predefinidos.
No Limite de confiança, o padrão para
Probabilidade
mínima
é Possível, o que significa que você recebe apenas as
descobertas avaliadas como Possível,
Provável e Muito provável.
Em uma tarefa posterior, você vai modificar esse modelo de inspeção para
conhecer outras opções de InfoTypes e limite de confiança.
-
Em Adicionar ações, ative
Publicar no Security Command Center.
-
Em Adicionar ações, ative também
Salvar cópias do perfil dos dados no BigQuery e forneça o
conjunto de dados e a tabela (que foram pré-criados neste laboratório)
para salvar os resultados no BigQuery.
| Propriedade |
Valor |
| ID do projeto |
|
| ID do conjunto de dados |
cloudstorage_discovery |
| ID da tabela |
data_profiles |
-
Clique em Continuar.
-
Em Definir locais de processamento de fallback, mantenha
os padrões e clique em Continuar.
-
Em Definir local para armazenar a configuração, deixe a
opção us (várias regiões nos Estados Unidos) ativada e
clique em Continuar.
-
Forneça um nome de exibição para esta configuração:
Descoberta do Cloud Storage
-
Clique em Criar e confirme clicando em
Criar configuração.
-
Clique na guia Perfis.
-
Em Tipo de local, selecione Região >
para visualizar os perfis.
-
Na tabela chamada
Perfis de dados para
, clique na guia Repositórios de arquivos.
Observação: depois de clicar para visualizar a guia
Repositórios de arquivos, confira as capturas de tela na
próxima seção para ter uma visão geral do que os resultados da descoberta
podem dizer sobre seus dados e, em seguida, prossiga para a Tarefa 2.
Não é necessário esperar a conclusão total da verificação de descoberta
para clicar na verificação de progresso abaixo e continuar na Tarefa
2.
Se você decidir deixar esta página aberta para acompanhar o progresso ao longo
do tempo, atualize a página periodicamente para ver as novas informações à
medida que forem preenchidas.
Clique em Verificar meu progresso para conferir o objetivo.
Criar e programar uma configuração de verificação.
O que os resultados da descoberta podem dizer sobre seus dados
Observação: depois que a verificação de configuração
começa, pode levar um tempo até que os resultados completos sejam
disponibilizados.
As imagens abaixo mostram os principais resultados da ativação da descoberta
para o Cloud Storage neste ambiente de laboratório.
Para os dados do Cloud Storage incluídos neste ambiente de laboratório, os
resultados sinalizaram a possível presença de vários InfoTypes, incluindo
números de SSN dos EUA, que são dados altamente sensíveis.
Imagem 1. Guia "Perfis" dos resultados da descoberta
A guia Perfis identifica os níveis de sensibilidade e risco
de cada nome de bucket específico do Cloud Storage: um com baixa sensibilidade
(bucket vazio para receber a saída dos jobs) e outro com alta sensibilidade
(bucket com dados brutos, incluindo SSN dos EUA).
Neste ambiente de laboratório, selecione Tipo de local como
Região >
para visualizar os perfis.
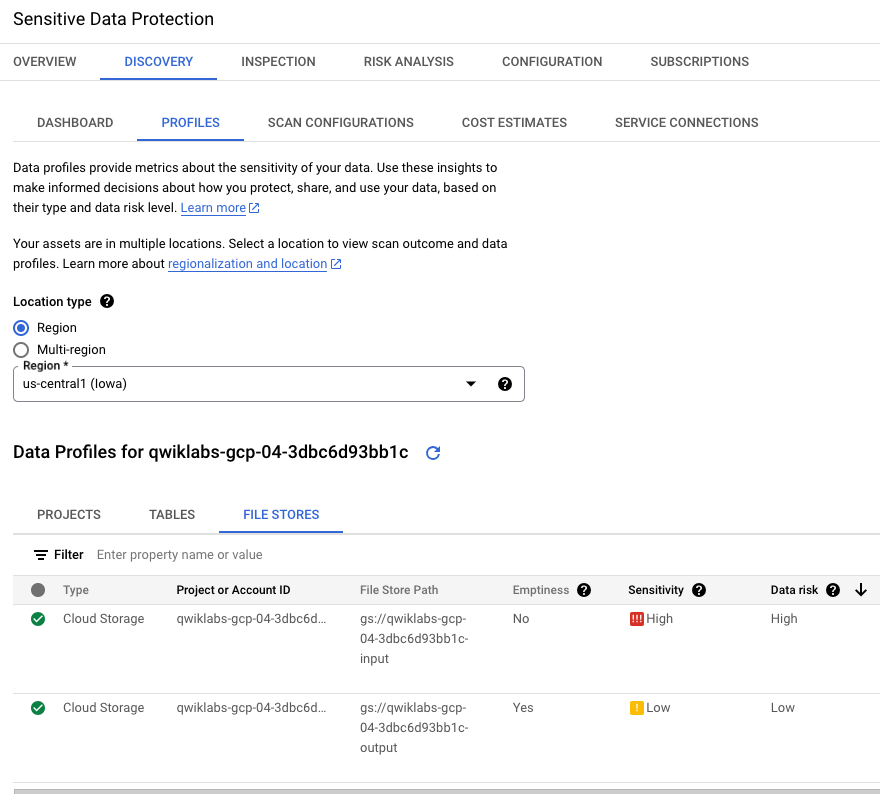
Imagem 2. Descoberta para o Cloud Storage ativada na interface
Dois perfis foram identificados para o Cloud Storage: um com baixa
sensibilidade (bucket vazio para receber a saída dos jobs) e outro com alta
sensibilidade (bucket com dados brutos).
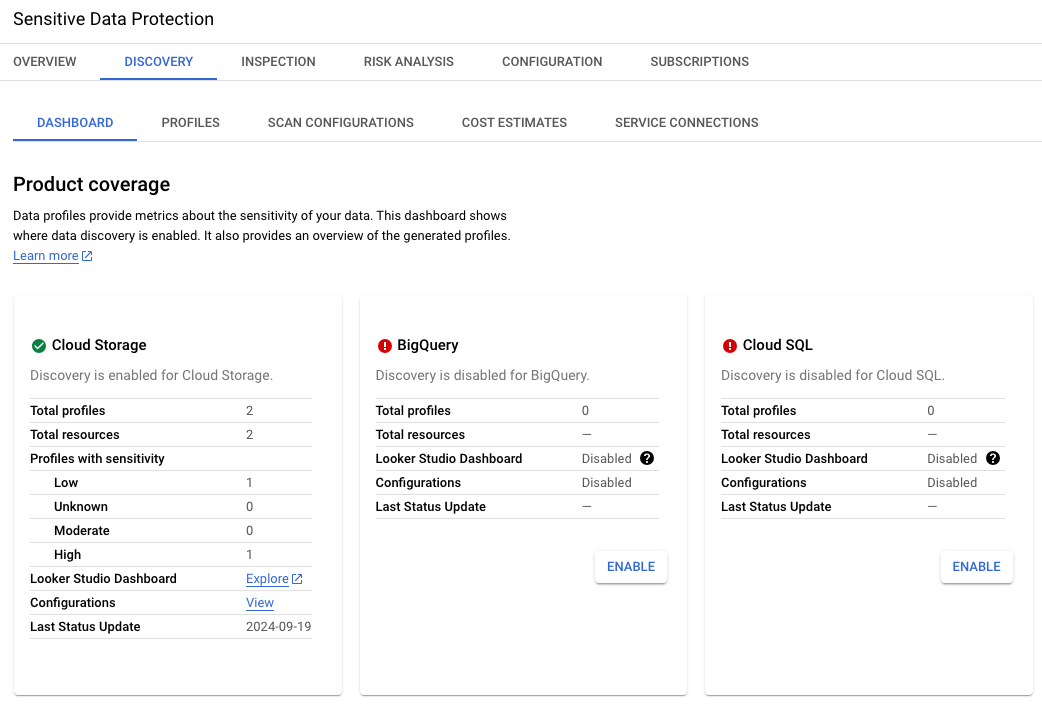
Imagem 3. Detalhes do inventário de dados sensíveis
Esta seção dos resultados mostra a localização global dos dois perfis de
dados. Neste exemplo, ambos estão na região us-central1.
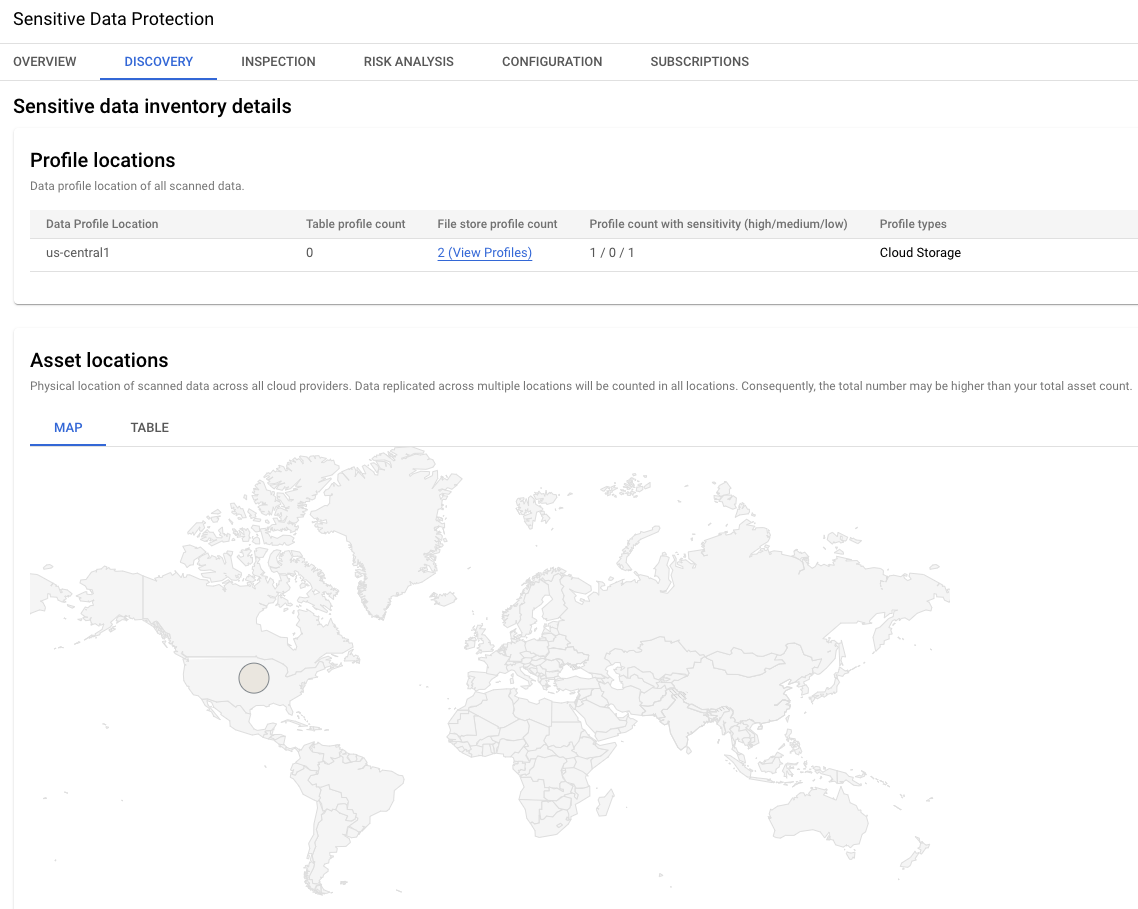
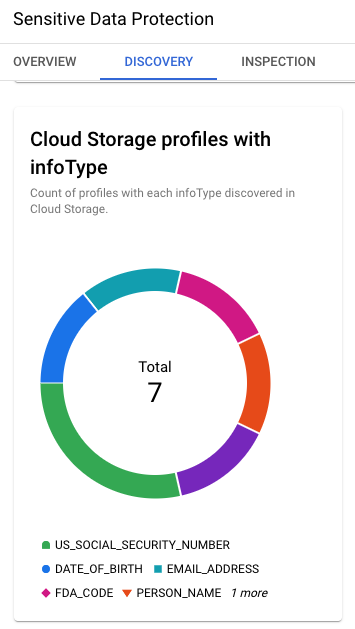
Imagem 4. Perfis do Cloud Storage com InfoTypes
Os resultados da descoberta também fornecem os principais InfoTypes
identificados no Cloud Storage: SSN dos EUA, data de nascimento, endereço de
e-mail, nome etc.
Tarefa 2: criar e modificar modelos reutilizáveis para inspeção e encobrimento
de InfoTypes específicos
Agora que você sabe que os números SSN dos EUA foram identificados nos seus
arquivos do Cloud Storage, comece a criar um plano para inspecionar e encobrir
esses dados sensíveis antes que os arquivos sejam usados para treinar modelos
de machine learning.
Nesta tarefa, você vai configurar dois
modelos:
-
Modificar um modelo de inspeção atual para encontrar todas as instâncias de
números SSN dos EUA nos seus arquivos do Cloud Storage.
-
Criar um modelo de desidentificação para encobrir SSNs dos EUA em arquivos
de dados estruturados (como texto e CSV).
Mais adiante no laboratório, você vai usar esses modelos para inspecionar e
encobrir ainda mais SSNs dos EUA executando jobs de inspeção e
desidentificação.
Modificar um modelo de inspeção atual
Quando você ativou a descoberta para o Cloud Storage, um novo modelo de
inspeção foi criado com vários valores padrão, incluindo os de InfoTypes e
limite de confiança.
Nesta seção, imagine que você já analisou todos os resultados da descoberta e
agora quer modificar o modelo de inspeção para que se concentre nos SSNs dos
EUA.
-
Volte para a página de visão geral da
Proteção de Dados Sensíveis
clicando em Menu de navegação () > Segurança >
Proteção de Dados Sensíveis (em
Proteção de dados).
-
Clique na guia Configuração.
-
Na guia Modelos, localize a linha do modelo gerado pela
descoberta (como o ID do modelo 7216194786087173213).
Anote o ID do modelo para usar depois na Tarefa 4.
-
Em Ações para esse ID de modelo, clique nos três pontos
verticais e selecione Editar.
-
Atualize o Nome de exibição para
Inspection Template for US SSN.
-
Atualize o campo Descrição para
This template was created as part of a Sensitive Data Protection
profiler configuration and was modified for deeper inspection for US
Social Security numbers.
-
Para InfoTypes, clique em
Gerenciar InfoTypes.
-
Marque a caixa de seleção US_SOCIAL_SECURITY_NUMBER e
desmarque todas as outras opções.
Você pode desmarcar todas as outras opções clicando em
Selecionar todas as linhas (abaixo do ícone de filtro) e
clicando novamente para desmarcar todos os valores.
-
Clique em Concluído para retornar ao modelo de inspeção.
-
Em Limite de confiança ("probabilidade mínima"),
selecione Improvável.
Além das descobertas avaliadas como Possível,
Provável e Muito provável, os resultados
agora vão incluir Improvável para ajudar na análise de
possíveis instâncias de SSNs dos EUA.
-
Mantenha os outros valores como padrão e clique em
Salvar.
-
Clique em Confirmar salvamento.
Criar um modelo de desidentificação para dados estruturados
-
Volte para a página de visão geral da
Proteção de Dados Sensíveis.
-
Clique na guia Configuração.
-
Na guia Modelos, clique em Criar modelo.
-
Forneça os seguintes valores para criar o modelo de desidentificação:
| Propriedade |
Valor |
| Tipo de modelo |
Desidentificar (remover dados sensíveis)
|
| Tipo de transformação de dados |
Gravar |
| ID do modelo |
us_ssn_deidentify |
| Nome de exibição |
Modelo de desidentificação para SSNs dos EUA
|
| Tipo de local |
Multi_region > global (Global) |
-
Mantenha os outros valores como padrão e clique em
Continuar.
-
Em Configurar desidentificação >
Regra de transformação, adicione os seguintes nomes de
campo digitando o nome e pressionando a tecla enter:
ssn e email
-
Em Tipo de transformação, selecione
Transformação de campo primitiva.
-
Em Método de transformação >
Transformação, selecione Substituir.
Essa opção substitui o conteúdo de cada instância dos campos que você
forneceu na etapa 6 (ssn e e-mail).
-
Em Método de transformação >
Tipo de substituição, selecione String.
-
Em Método de transformação >
Valor da string, mantenha o valor
[redacted] como padrão.
-
Clique em + Adicionar regra de transformação para
adicionar uma segunda regra.
-
Para a Regra de transformação desta segunda regra,
adicione o seguinte nome de campo digitando o nome e pressionando a tecla
enter: message
Neste ambiente de laboratório, há arquivos CSV no Cloud Storage que contêm uma
coluna (ou campo) chamada message, que armazena as mensagens
de chat de exemplo entre clientes e agentes de serviço.
-
Em Tipo de transformação, selecione
Correspondência no InfoType e clique em
Adicionar transformação.
-
Em Método de transformação, selecione
Substituir pelo nome do InfoType.
-
Em InfoTypes para transformar, selecione
Os InfoTypes detectados em um modelo ou uma configuração de inspeção
que não foram especificados em outras regras.
Essa opção aplica a inspeção e o encobrimento de InfoType a todos os
arquivos com um campo denominado message quando esse
modelo é usado para executar um job.
-
Clique em Criar.
Clique em Verificar meu progresso para conferir o objetivo.
Modificar o modelo de inspeção atual e criar um modelo de desidentificação
para dados estruturados.
Tarefa 3: analisar os resultados iniciais da descoberta
Observação: como já mencionado, depois que a verificação de
configuração começa, pode levar um tempo até que os resultados completos
sejam disponibilizados.
Agora que já passou um tempo desde que você criou os modelos, alguns
resultados estarão disponíveis no painel do Looker gerado pela verificação da
descoberta.
Nesta tarefa, você vai analisar os resultados iniciais da descoberta
fornecidos em um painel do Looker com base nas informações do perfil dos dados
salvas no BigQuery na Tarefa 1.
Ver o resumo dos resultados no painel do Looker
-
Volte para a página de visão geral da
Proteção de Dados Sensíveis.
-
Na guia Descoberta >
Configurações de verificação, localize a linha denominada
Descoberta do Cloud Storage. Em
Data Studio, clique em Looker na linha.
-
Em Solicitar autorização, clique em
Autorizar.
-
Na janela de diálogo Escolha uma conta no qwiklabs.net,
selecione
.
-
Em Analisar acesso aos dados, clique em
Confirmar.
-
Em Conceder consentimento, clique em
Permitir.
-
Revise a página Visão geral do resumo.
Há blocos de dados que resumem informações importantes, como risco e
sensibilidade de dados e tipos de recursos.
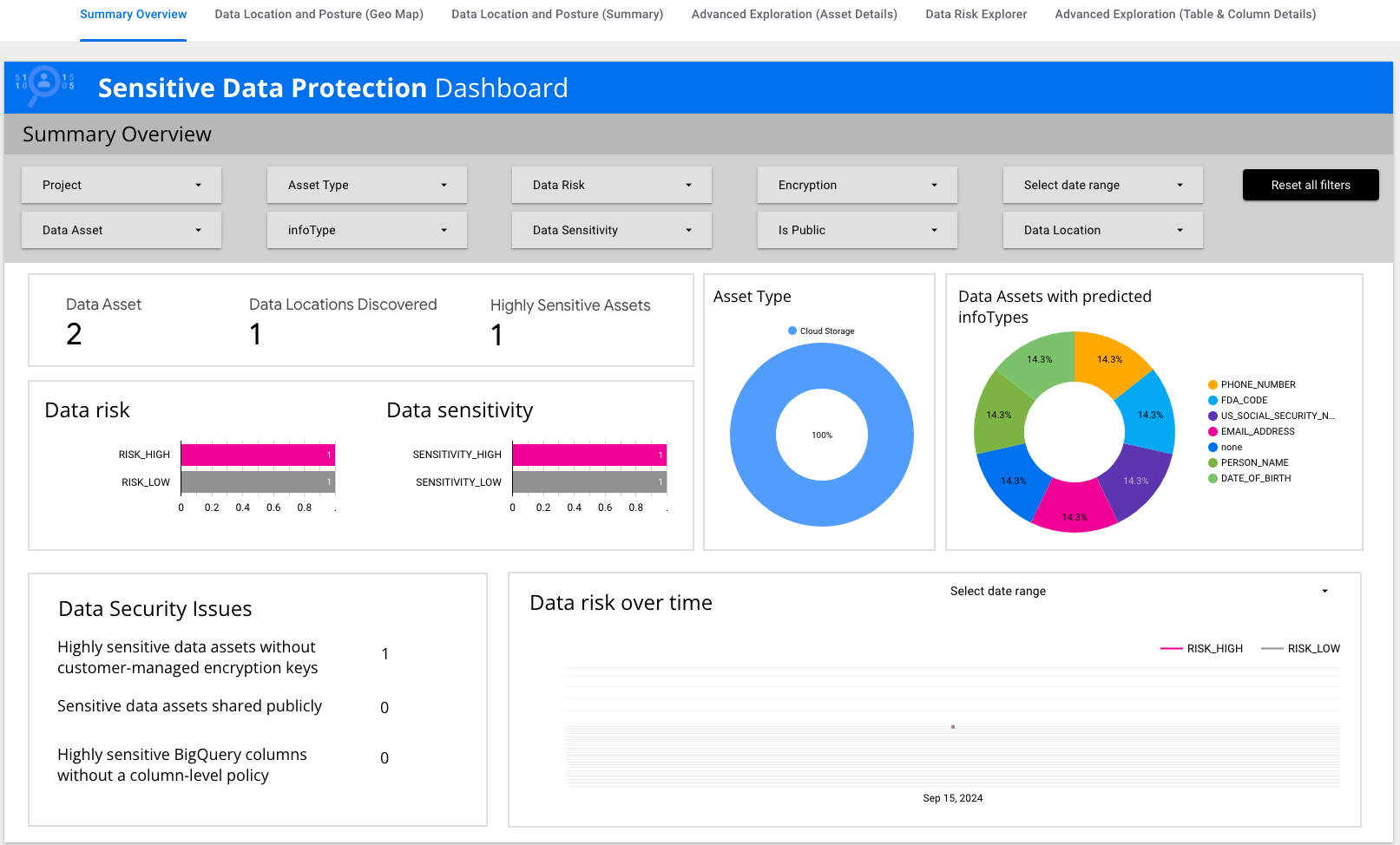
-
Clique em Análise detalhada (detalhes do recurso) e confira
a tabela.
Observe que há um InfoType de US_SOCIAL_SECURITY_NUMBER.
-
Clique em Editar e compartilhar.
-
Em Insira suas informações básicas, selecione qualquer
país e forneça um nome de empresa, como NA.
-
Marque a caixa para concordar com os Termos de Serviço e clique em
Continuar.
-
Selecione Não para todas as preferências de e-mail e
clique em Continuar.
-
Em Analisar o acesso aos dados antes de salvar, clique em
Confirmar e salvar.
-
No Data Studio, clique em Ver para conferir o relatório.
-
Identifique a linha com o InfoType
US_SOCIAL_SECURITY_NUMBER e clique em
Abrir na primeira coluna dessa linha.
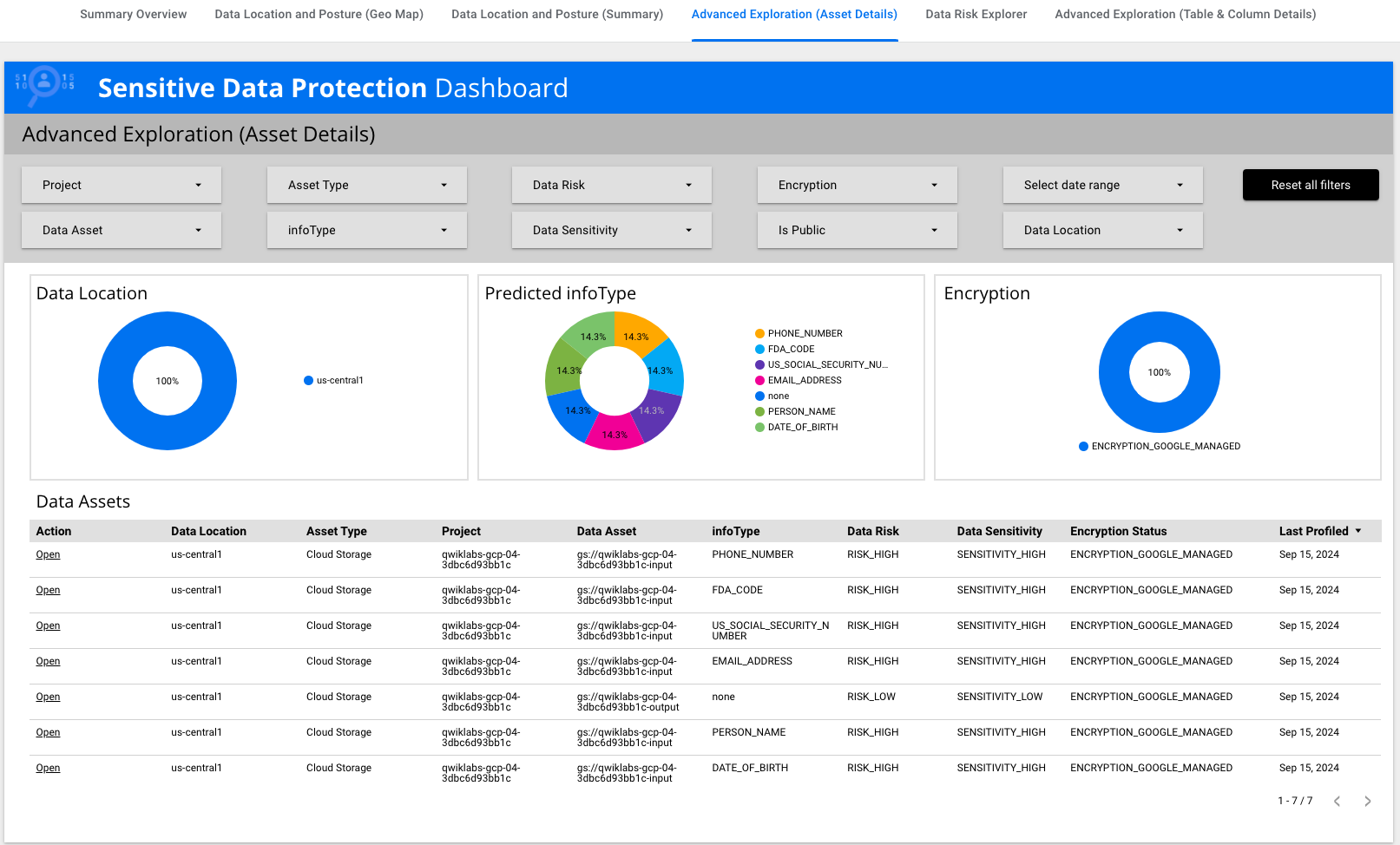
Veja os resultados detalhados na Proteção de Dados Sensíveis
-
Na página
Descoberta de Dados Sensíveis: detalhes do perfil de armazenamento de
arquivos do Cloud Storage, verifique se Selecionar um projeto (barra de menu
superior) está definido como o ID do projeto
e analise a página.
Há muitos detalhes fornecidos sobre os recursos verificados, incluindo
permissões do IAM.
-
Expanda a seta ao lado de
Ver permissões detalhadas do IAM.
-
Expanda a seta ao lado de Administrador do Storage.
Você pode ver que outro usuário () está listado como administrador do Cloud Storage e, portanto, tem acesso
total aos dados.
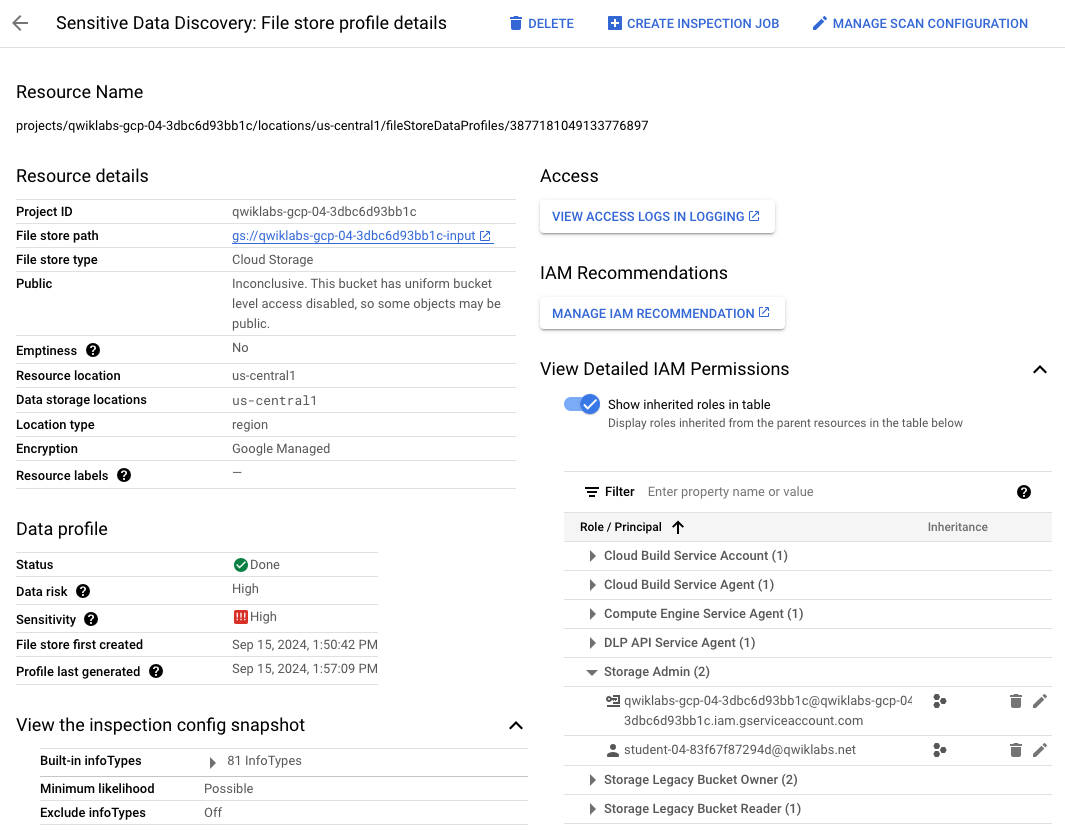
Tarefa 4: criar e executar um job de inspeção
Para a Proteção de Dados Sensíveis, um fluxo de trabalho típico após uma
verificação de descoberta é executar um
job de inspeção
mais detalhado para uma investigação mais profunda de InfoTypes específicos.
Na Tarefa 2, você criou um modelo de inspeção para uma inspeção mais detalhada
dos SSNs dos EUA. Nesta tarefa, você vai usar esse modelo para criar e
executar o job de inspeção.
Criar e executar um job de inspeção
-
Volte para a página de visão geral da
Proteção de Dados Sensíveis.
-
Clique na guia Inspeção e em
Criar gatilhos de jobs e jobs.
-
Em Escolher dados de entrada, forneça os seguintes
valores:
| Propriedade |
Valor |
| ID do job |
us_ssn_inspection |
| Tipo de local |
Multi_region > us (várias regiões nos Estados Unidos)
|
| Tipo de armazenamento |
Google Cloud Storage |
| Tipo de local |
Verifique um único caminho do arquivo ou da pasta
|
| URL |
gs://-input/
(não se esqueça de adicionar uma / no final do URL)
|
| Verificar recorrentemente |
Ative essa opção (não se esqueça de adicionar uma / ao URL
acima para que essa opção possa ser ativada)
|
| Amostragem |
Aumente o valor para 100%
|
| Método de amostragem |
Sem amostras |
| Arquivos |
Selecione TEXTO e CSV (e desmarque
todas as outras opções) e clique em OK
|
-
Clique em Continuar.
-
Em Modelo de inspeção > Nome do modelo,
adicione o caminho para o modelo de inspeção conforme fornecido abaixo,
substituindo TEMPLATE_ID pelo ID do modelo de inspeção que
você modificou na Tarefa 2 (como 7216194786087173213):
projects//locations/global/inspectTemplates/TEMPLATE_ID
Para visualizar o ID do modelo de novo, navegue até a guia
Configuração da página de visão geral da
Proteção de Dados Sensíveis.
Observação: não deixe espaços no caminho do modelo de inspeção ao
adicioná-lo ao Nome do modelo.
-
Mantenha os outros valores como padrão e clique em
Continuar.
-
Em Adicionar ações, ative a opção
Salvar no BigQuery e marque a caixa de seleção
Incluir citação.
Essa opção permite que o job copie a localização e o conteúdo dos dados
possivelmente sensíveis para o BigQuery.
-
Forneça o conjunto de dados e a tabela (que foram pré-criados neste
laboratório) para salvar os resultados no BigQuery:
| Propriedade |
Valor |
| ID do projeto |
|
| ID do conjunto de dados |
cloudstorage_inspection |
| ID da tabela |
us_ssn |
-
Para Adicionar ações, também ative
Publicar no Security Command Center.
-
Clique em Continuar.
-
Mantenha o padrão de Programação como
Nenhuma (executar o job único imediatamente após a criação)
para executar o job imediatamente e clique em Continuar.
Assim como as verificações de descoberta, é possível programar a execução de
jobs de inspeção em uma programação específica. Nesse caso, você executa o job
imediatamente depois que é criado.
-
Clique em Criar e confirme a criação clicando em
Confirmar criação.
Permaneça nesta página e aguarde a conclusão do job.
Quando o job tiver o status Concluído, prossiga para a
próxima seção.
Ver os resultados do job de inspeção no BigQuery
Na seção anterior, você selecionou a opção de salvar os resultados da inspeção
na tabela do BigQuery denominada us_ssn. Com um clique
abaixo, você pode ir facilmente para o BigQuery para analisar os resultados.
-
Clique em Ver descobertas no BigQuery.
-
No BigQuery, clique em Visualização para ver o conteúdo
da tabela.
Observe a coluna quote, que contém uma cópia do valor
exato que foi sinalizado pelo job de inspeção para análise adicional. Você
também pode rolar para a direita da tabela e analisar a coluna
container name para conferir a localização
(especificamente o nome do arquivo) que contém o valor citado.
Clique em Verificar meu progresso para conferir o objetivo.
Criar e executar um job de inspeção.
Tarefa 5: criar e executar um job de desidentificação
Além da descoberta, você pode usar outro serviço da Proteção de Dados
Sensíveis chamado
desidentificação. Com esse serviço, é possível reduzir as vulnerabilidades de dados sensíveis
no Cloud Storage executando um job de desidentificação para criar novas cópias
dos arquivos do Cloud Storage com os dados sensíveis encobertos. Essas novas
cópias podem ser compartilhadas com fluxos de trabalho downstream, em vez das
versões originais que contêm os dados sensíveis.
Nesta tarefa, você vai criar e executar um job de desidentificação usando o
modelo de desidentificação criado na Tarefa 2.
-
Volte para a página de visão geral da
Proteção de Dados Sensíveis.
-
Clique na guia Inspeção e em
Criar gatilhos de jobs e jobs.
-
Em Escolher dados de entrada, forneça os seguintes
valores:
| Propriedade |
Valor |
| ID do job |
us_ssn_deidentify |
| Tipo de local |
Multi_region > us (várias regiões nos Estados Unidos)
|
| Tipo de armazenamento |
Google Cloud Storage |
| Tipo de local |
Verifique um bucket com regras de inclusão/exclusão opcionais
|
| Nome do bucket |
-input
|
| Amostragem |
Aumente o valor para 100%
|
| Método de amostragem |
Sem amostras |
| Arquivos |
Selecione TEXTO e CSV (e desmarque
todas as outras opções) e clique em OK
|
Observação: não deixe espaços no nome do bucket.
-
Em Excluir caminhos, clique em
Adicionar regex de exclusão. Em
Excluir caminhos, digite:
ignore
O valor de Excluir caminhos 1 agora é:
gs://-input/ignore
Com essa opção, você pode instruir o job de desidentificação a ignorar os
arquivos no subdiretório denominado ignore.
-
Mantenha os outros valores como padrão e clique em
Continuar.
Não adicione um valor para o modelo de inspeção. Em uma etapa futura, você vai
definir o valor do modelo de desidentificação.
-
Em Configurar detecção, deixe todos os valores padrão e
clique em Continuar.
-
Em Adicionar ações, role a página para baixo para
encontrar e ativar Fazer uma cópia de desidentificação.
-
Em Modelo de desidentificação estruturado, insira o
modelo de desidentificação criado anteriormente para arquivos estruturados
(como arquivos CSV e de texto):
projects//locations/global/deidentifyTemplates/us_ssn_deidentify
Observação: não deixe espaços no caminho do modelo de desidentificação.
-
Ative a opção
Exportar detalhes da transformação para o BigQuery e
forneça o conjunto de dados e a tabela (que foram pré-criados neste
laboratório) para salvar os resultados no BigQuery.
| Propriedade |
Valor |
| ID do projeto |
|
| ID do conjunto de dados |
cloudstorage_transformations |
| ID da tabela |
deidentify_ssn_csv |
- No local de saída do Cloud Storage, especifique:
gs://-output
Esse valor instrui o job a gravar a saída encoberta no segundo bucket que foi
pré-criado neste laboratório para arquivos de saída.
-
Em Arquivos, selecione TEXTO e
CSV (e desmarque todas as outras opções) e clique em
OK.
-
Clique em Continuar.
-
Mantenha o padrão de Programação como
Nenhuma para executar o job imediatamente e clique em
Continuar.
Semelhante aos jobs de inspeção, as opções de programação incluem a execução
do job de desidentificação periodicamente (como semanalmente).
-
Clique em Criar e confirme a criação clicando em
Confirmar criação.
Permaneça nesta página e aguarde a conclusão do job.
Quando o job tiver o status Concluído, deixe essa guia do
navegador aberta e siga para a próxima seção.
Ver detalhes da transformação desidentificada no BigQuery
Na seção anterior, você selecionou para salvar os detalhes da desidentificação
na tabela do BigQuery denominada deidentify_ssn_csv. Nesta
seção, você vai acessar o BigQuery para conferir os detalhes da transformação.
-
No console do Google Cloud, clique em
Menu de navegação () > BigQuery.
-
No painel Análises, expanda
> cloudstorage_transformations
e clique na tabela chamada deidentify_ssn_csv.
-
Clique em Visualizar para ver os resultados.
Observe as colunas container_name e
transformation.type, que fornecem detalhes sobre os
arquivos que foram desidentificados usando regras de transformação
específicas.
Visualizar saída desidentificada
-
Volte para a página de resultados do job de inspeção e clique em
Configuração.
-
Role para baixo até a seção Ações >
Bucket de saída para dados desidentificados do Cloud Storage.
-
Clique no link do bucket (gs://-output) para ir a esse bucket do Cloud Storage e revisar os arquivos de
desidentificação.
Clique em Verificar meu progresso para conferir o objetivo.
Criar e executar um job de desidentificação.
Parabéns!
Neste laboratório, você ativou a descoberta para monitoramento contínuo de
dados sensíveis em arquivos do Cloud Storage. Você também criou e modificou
modelos reutilizáveis para inspeção e desidentificação e executou jobs de
inspeção e desidentificação com a opção ativada para gravar os resultados do
job no BigQuery para maior investigação.
Próximas etapas/Saiba mais
Confira os seguintes recursos para saber mais sobre a Proteção de Dados
Sensíveis para o Cloud Storage:
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 10 de março de 2026
Laboratório testado em 10 de março de 2026
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





