GSP1281

Übersicht
Sensitive Data Protection
ist ein vollständig verwalteter Dienst, mit dem Sie sensible Daten erkennen,
klassifizieren und schützen können. Zu den wichtigsten Optionen gehören die
Erkennung sensibler Daten, um kontinuierlich Profile für sensible Daten zu
erstellen, die De‑Identifikation sensibler Daten einschließlich ihrer
Entfernung und die Cloud Data Loss Prevention (DLP) API, mit der Sie die
Erkennung, Prüfung und De‑Identifikation dieser Daten in benutzerdefinierte
Arbeitslasten und Anwendungen einbinden können.
Angenommen, Sie haben Rohdaten in Cloud Storage, die sensible Daten enthalten.
Sie möchten diese Daten identifizieren, schützen und entfernen, bevor die
Dateien von Endnutzerinnen und -nutzern für Analysen oder zum Trainieren von
Machine-Learning-Modellen verwendet werden. Sensitive Data Protection kann
Ihnen dabei helfen.
In diesem Lab aktivieren Sie zuerst die Erkennung für die kontinuierliche
Überwachung sensibler Daten in Cloud Storage. Auf der Grundlage der
Erkennungsergebnisse erstellen und ändern Sie benutzerdefinierte,
wiederverwendbare Vorlagen für die Prüfung und De‑Identifikation (Entfernung
sensibler Daten) von Cloud Storage-Dateien. Zuletzt verwenden Sie diese
Vorlagen, um Jobs auszuführen, mit denen Sie bestimmte sensible Datentypen in
Ihren Cloud Storage-Dateien genauer untersuchen und entfernen können.
Lerninhalte
Aufgaben in diesem Lab:
-
Erkennung für die kontinuierliche Überwachung sensibler Daten in Cloud
Storage-Dateien aktivieren
-
Wiederverwendbare Vorlagen für Inspektions- und De‑Identifikationsjobs
erstellen und anpassen
- Erkennungsergebnisse ansehen und interpretieren
-
Inspektions- und De‑Identifikationsjobs mit aktivierter Option zum Schreiben
von Jobergebnissen in BigQuery ausführen
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
- Schaltfläche „Google Cloud Console öffnen“
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Aufgabe 1: Erkennung für die kontinuierliche Überwachung von Cloud Storage
aktivieren
Mit dem Erkennungsdienst von Sensitive Data Protection können Sie ermitteln,
wo sich sensible und risikoreiche Daten in Ihrer Organisation befinden. Wenn
Sie eine Konfiguration für einen Erkennungsscan erstellen, scannt Sensitive
Data Protection die von Ihnen ausgewählten Ressourcen und generiert
Datenprofile. Diese enthalten Informationen zu den erkannten
infoTypes
(Arten von sensiblen Daten) sowie Metadaten zum Datenrisiko und zur
Vertraulichkeitsstufe.
In dieser Aufgabe erstellen Sie einen Erkennungsscan, um automatisch für die
Daten in allen Cloud Storage-Buckets im Projekt Profile zu erstellen. Da es
einige Zeit dauern kann, bis die vollständigen Erkennungsergebnisse generiert
wurden, erhalten Sie in im letzten Abschnitt dieser Aufgabe Hervorhebungen und
Zusammenfassungen für die wichtigsten Ergebnisse.
Scankonfiguration erstellen und planen
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü ( ) > Sicherheit.
) > Sicherheit.
-
Klicken Sie unter Datenschutz auf
Sensitive Data Protection.
-
Klicken Sie auf den Tab Erkennung.
-
Klicken Sie unter Cloud Storage auf
Aktivieren.
-
Lassen Sie unter Erkennungstyp auswählen die Option für
Cloud Storage aktiviert und klicken Sie auf
Weiter.
-
Lassen Sie unter Bereich auswählen die Option
Ausgewähltes Projekt scannen aktiviert und klicken Sie
auf Weiter.
-
Übernehmen Sie für Verwaltete Zeitpläne die
Standardeinstellung und klicken Sie auf Weiter.
In diesem Lab legen Sie fest, dass der Erkennungsscan sofort nach der
Erstellung ausgeführt wird. Es gibt aber viele Möglichkeiten, Scans
regelmäßig (zum Beispiel täglich oder wöchentlich) oder nach bestimmten
Ereignissen (zum Beispiel bei Aktualisierung einer Inspektionsvorlage)
auszuführen.
-
Lassen Sie unter Inspektionsvorlage auswählen die Option
Neue Inspektionsvorlage erstellen aktiviert. Übernehmen
Sie alle anderen Standardeinstellungen und klicken Sie auf
Weiter.
Standardmäßig enthält die neue Inspektionsvorlage etwa 80 vordefinierte
infoTypes.
Beim Konfidenzgrenzwert ist die
Mindestwahrscheinlichkeit
standardmäßig auf Möglich eingestellt. Das bedeutet, dass
Sie nur die Ergebnisse erhalten, die als Möglich,
Wahrscheinlich oder
Sehr wahrscheinlich bewertet wurden.
In einer späteren Aufgabe ändern Sie diese Inspektionsvorlage, um andere
Optionen für infoTypes und den Konfidenzgrenzwert zu testen.
-
Aktivieren Sie unter Aktionen hinzufügen die Option
In Security Command Center veröffentlichen.
-
Aktivieren Sie unter Aktionen hinzufügen auch die Option
Datenprofilkopien in BigQuery speichern und geben Sie das
Dataset und die Tabelle an (für dieses Lab im Voraus erstellt), um die
Ergebnisse in BigQuery zu speichern.
| Attribut |
Wert |
| Projekt-ID |
|
| Dataset-ID |
cloudstorage_discovery |
| Tabellen-ID |
data_profiles |
-
Klicken Sie auf Weiter.
-
Übernehmen Sie für
Fallback-Standorte für die Verarbeitung festlegen die
Standardeinstellungen und klicken Sie auf Weiter.
-
Lassen Sie für
Speicherort für Konfiguration festlegen die Option für
us (mehrere Regionen in den USA) aktiviert und klicken
Sie auf Weiter.
-
Geben Sie einen Anzeigenamen für diese Konfiguration an:
Cloud Storage-Erkennung.
-
Klicken Sie auf Erstellen und bestätigen Sie die
Erstellung mit einem Klick auf Konfiguration erstellen.
-
Klicken Sie auf den Tab Profile.
-
Wählen Sie als Standorttyp die Option
Region
aus, um die Profile aufzurufen.
-
Klicken Sie in der Tabelle
Datenprofile für
auf den Tab Dateispeicher.
Hinweis: Nachdem Sie auf den Tab
Dateispeicher geklickt haben, sehen Sie sich die
Screenshots im nächsten Abschnitt an, um einen Überblick darüber zu
erhalten, was die Ergebnisse der Erkennung über Ihre Daten aussagen können.
Fahren Sie dann mit Aufgabe 2 fort.
Sie müssen nicht warten, bis der Erkennungsscan vollständig abgeschlossen
ist, um auf die Fortschrittsanzeige unten zu klicken und mit Aufgabe 2
fortzufahren.
Wenn Sie diese Seite geöffnet lassen, um den Fortschritt im Laufe der Zeit zu
sehen, sollten Sie die Seite regelmäßig aktualisieren, damit die aktuellen
Informationen abgerufen werden.
Klicken Sie auf Fortschritt prüfen.
Scankonfiguration erstellen und planen
Was die Erkennungsergebnisse über Ihre Daten aussagen
Hinweis: Nachdem der Konfigurationsscan gestartet wurde,
kann es einige Zeit dauern, bis die vollständigen Ergebnisse verfügbar sind.
Die Bilder unten zeigen die wichtigsten Ergebnisse der Aktivierung der
Erkennung für Cloud Storage in dieser Lab-Umgebung.
Für die in dieser Lab-Umgebung enthaltenen Cloud Storage-Daten wurde in den
Ergebnissen das potenzielle Vorhandensein mehrerer InfoTypes gemeldet,
darunter US-Sozialversicherungsnummern, was sehr sensible Daten sind.
Bild 1. Tab „Profile“ der Erkennungsergebnisse
Auf dem Tab Profile werden die Vertraulichkeits- und
Risikostufen für jeden spezifischen Cloud Storage-Bucket-Namen angegeben:
einen mit niedriger Vertraulichkeit (leerer Bucket für die Ausgabe von Jobs)
und einen mit hoher Vertraulichkeit (Bucket mit Rohdaten, einschließlich
US-Sozialversicherungsnummer).
Wählen Sie in dieser Lab-Umgebung als Standorttyp die Option
Region >
aus, um die Profile aufzurufen.
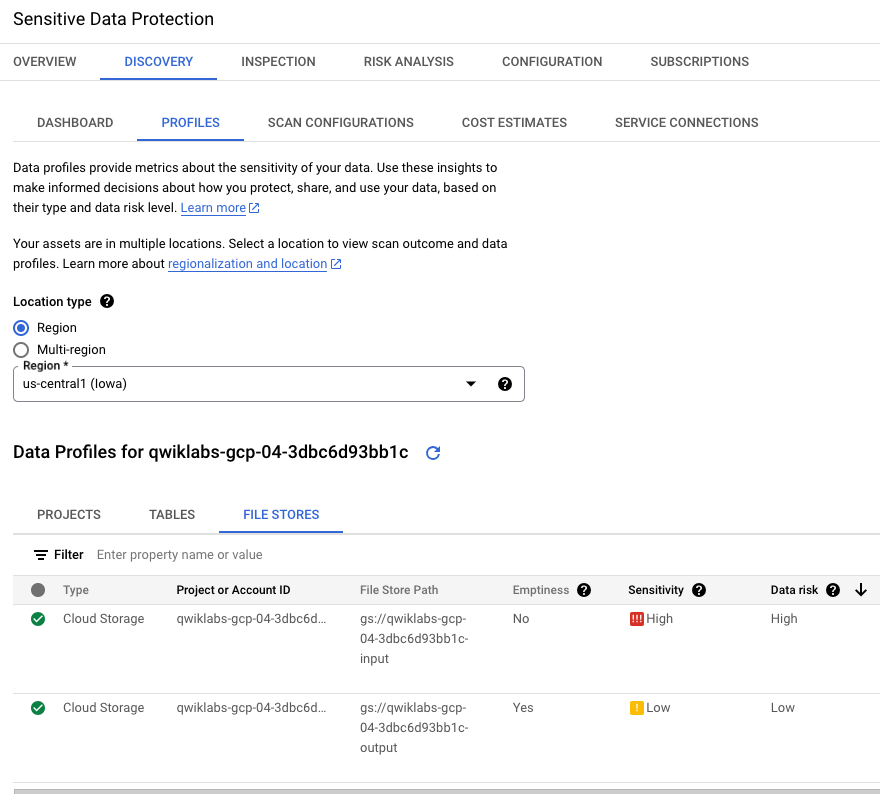
Bild 2. Erkennung für Cloud Storage in der UI aktiviert
Für Cloud Storage wurden zwei Profile identifiziert: eines mit niedriger
Vertraulichkeit (leerer Bucket zum Empfangen der Ausgabe von Jobs) und eines
mit hoher Vertraulichkeit (Bucket mit Rohdaten).
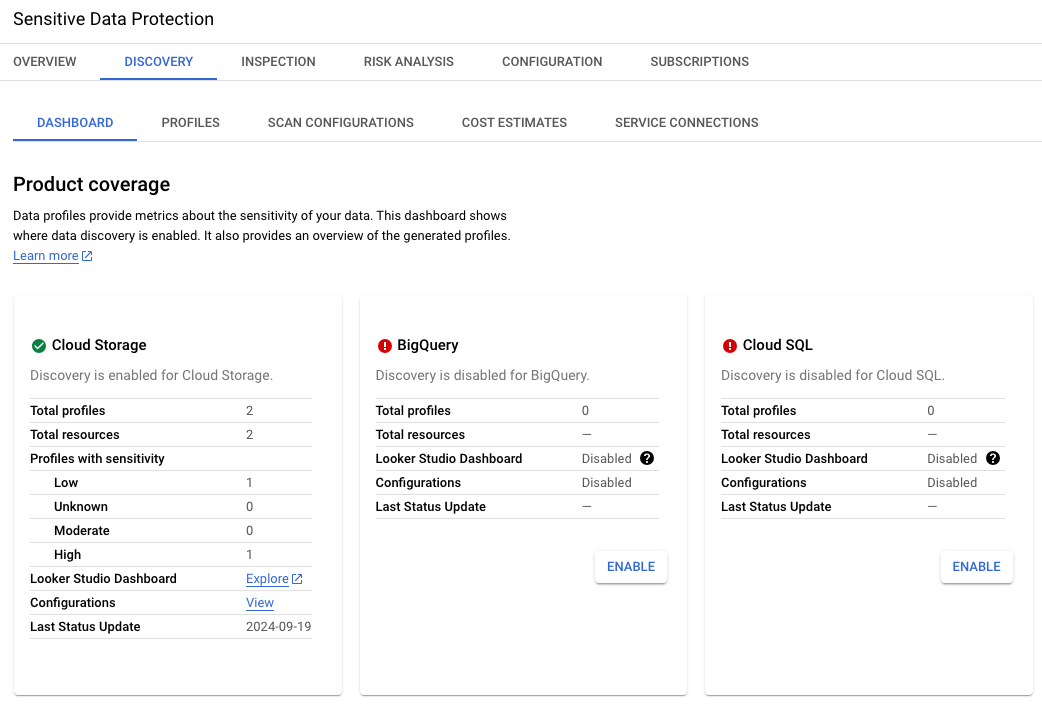
Bild 3. Details zum Inventar sensibler Daten
In diesem Abschnitt der Ergebnisse wird der globale Standort der zwei
Datenprofile angegeben. In diesem Beispiel befinden sich beide in der Region
us-central1.
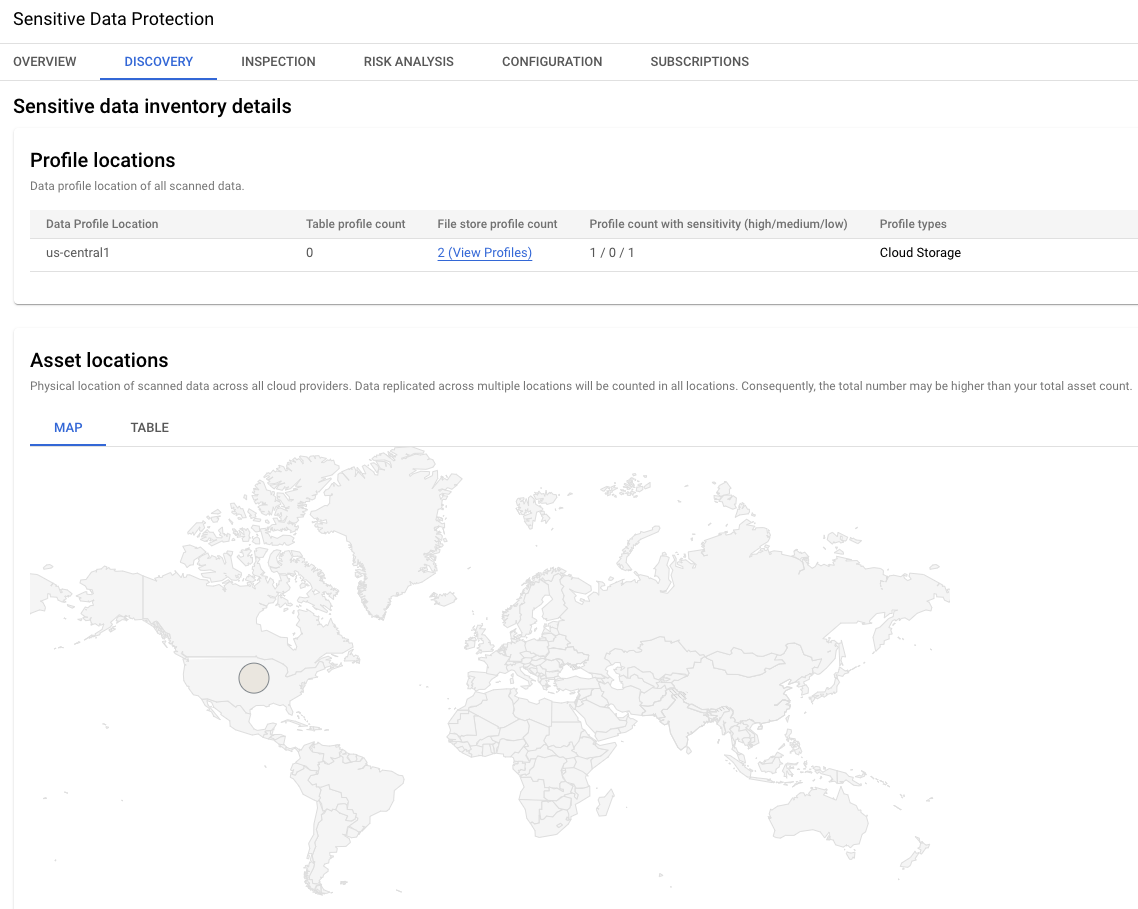
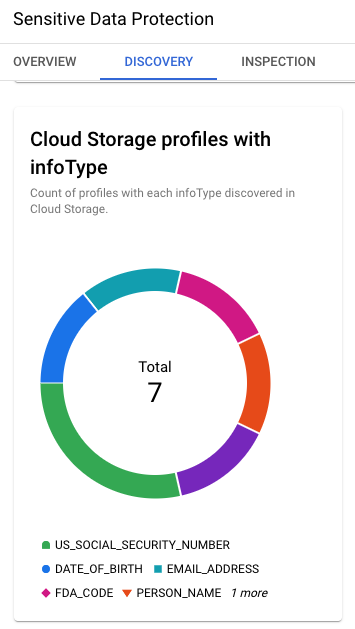
Bild 4. Cloud Storage-Profile mit infoTypes
Die Ergebnisse der Erkennung enthalten auch die wichtigsten in Cloud Storage
identifizierten InfoTypes: US-Sozialversicherungsnummer, Geburtsdatum,
E‑Mail-Adresse, Name und andere.
Aufgabe 2: Wiederverwendbare Vorlagen zum Prüfen von InfoTypes und Entfernen
sensibler Daten erstellen und anpassen
Nachdem Sie nun wissen, dass in Ihren Cloud Storage-Dateien
US-Sozialversicherungsnummern gefunden wurden, können Sie einen Plan
erstellen, um diese sensiblen Daten zu entfernen, bevor die Dateien zum
Trainieren von Machine-Learning-Modellen verwendet werden.
In dieser Aufgabe konfigurieren Sie zwei
Vorlagen. Gehen Sie dabei so vor:
-
Passen Sie eine vorhandene Inspektionsvorlage an, um alle Instanzen von
US-Sozialversicherungsnummern in Ihren Cloud Storage-Dateien zu finden.
-
Erstellen Sie eine De‑Identifikationsvorlage, um
US-Sozialversicherungsnummern aus Dateien mit strukturierten Daten (zum
Beispiel Text- und CSV-Dateien) zu entfernen.
Später im Lab verwenden Sie diese Vorlagen, um die
US-Sozialversicherungsnummern durch Ausführen von Inspektions- und
De‑Identifikationsjobs weiter zu prüfen und zu entfernen.
Vorhandene Inspektionsvorlage ändern
Als Sie die Erkennung für Cloud Storage aktiviert haben, wurde eine neue
Inspektionsvorlage mit mehreren Standardwerten erstellt, darunter für
infoTypes und den Konfidenzgrenzwert.
In diesem Abschnitt gehen wir davon aus, dass Sie sich die vollständigen
Erkennungsergebnisse bereits angesehen haben und die Inspektionsvorlage nun so
anpassen möchten, dass sie sich auf US-Sozialversicherungsnummern
konzentriert.
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück, indem Sie auf das Navigationsmenü () > Sicherheit >
Sensitive Data Protection (unter
Datenschutz) klicken.
-
Klicken Sie auf den Tab Konfiguration.
-
Suchen Sie auf dem Tab Vorlagen nach der Zeile für die
durch die Erkennung generierte Vorlage (zum Beispiel Vorlagen-ID
7216194786087173213).
Notieren Sie sich diese Vorlagen-ID für Aufgabe 4.
-
Klicken Sie für diese Vorlagen-ID unter Aktionen auf das
Dreipunkt-Menü und wählen Sie Bearbeiten aus.
-
Ändern Sie den Anzeigenamen in
Inspection Template for US SSN.
-
Ändern Sie die Beschreibung in
This template was created as part of a Sensitive Data Protection
profiler configuration and was modified for deeper inspection for US
Social Security numbers..
-
Klicken Sie unter InfoTypes auf
InfoTypes verwalten.
-
Aktivieren Sie das Kästchen für
US_SOCIAL_SECURITY_NUMBER und heben Sie die Auswahl aller
anderen Optionen auf.
Sie können die Auswahl aller anderen Optionen ganz einfach aufheben, indem
Sie zweimal auf Alle Zeilen auswählen (unter dem
Filtersymbol) klicken.
-
Klicken Sie auf Fertig, um zur Inspektionsvorlage
zurückzukehren.
-
Wählen Sie für
Konfidenzgrenzwert („Mindestwahrscheinlichkeit“) die
Option Unwahrscheinlich aus.
Zusätzlich zu den Ergebnissen, die als Möglich,
Wahrscheinlich und
Sehr wahrscheinlich bewertet werden, enthalten die
Ergebnisse jetzt auch Unwahrscheinlich, um eine weitere
Überprüfung potenzieller Vorkommen von US-Sozialversicherungsnummern zu
unterstützen.
-
Übernehmen Sie alle anderen Standardeinstellungen und klicken Sie auf
Speichern.
-
Klicken Sie auf Speichern bestätigen.
De‑Identifikationsvorlage für strukturierte Daten erstellen
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück.
-
Klicken Sie auf den Tab Konfiguration.
-
Klicken Sie auf dem Tab Vorlagen auf
Vorlage erstellen.
-
Geben Sie die folgenden Werte ein, um die De‑Identifikationsvorlage zu
erstellen:
| Attribut |
Wert |
| Vorlagentyp |
De‑identifizieren (sensible Daten entfernen)
|
| Datentransformationstyp |
Record |
| Vorlagen-ID |
us_ssn_deidentify |
| Anzeigename |
De-identification Template for US SSN |
| Standorttyp |
Multi_region > global (Global) |
-
Übernehmen Sie für alle anderen Einstellungen die Standardwerte und
klicken Sie auf Weiter.
-
Fügen Sie unter De‑Identifikation konfigurieren >
Transformationsregel die folgenden Feldnamen hinzu, indem
Sie den Namen eingeben und dann die Eingabetaste drücken:
ssn und email.
-
Wählen Sie als Transformationstyp die Option
Transformation eines einfachen Feldes aus.
-
Wählen Sie unter Transformationsmethode >
Transformation die Option Ersetzen aus.
Durch diese Option wird der Inhalt jeder Instanz für die Felder ersetzt,
die Sie in Schritt 6 angegeben haben („ssn“ und „email“).
-
Wählen Sie unter Transformationsmethode >
Typ ersetzen die Option String aus.
-
Übernehmen Sie für Transformationsmethode >
Stringwert den Standardwert [redacted].
-
Klicken Sie auf + Transformationsregel hinzufügen, um
eine zweite Regel hinzuzufügen.
-
Fügen Sie für diese zweite Regel für
Transformationsregel den Feldnamen
message hinzu, indem Sie den Namen eingeben und dann die
Eingabetaste drücken.
In dieser Lab-Umgebung gibt es in Cloud Storage CSV-Dateien, die eine Spalte
(oder ein Feld) mit dem Namen message enthalten. Darin sind
die Beispielchatnachrichten zwischen Kundinnen oder Kunden sowie
Servicepersonal gespeichert.
-
Wählen Sie als Transformationstyp die Option
Übereinstimmung mit infoType aus und klicken Sie auf
Transformation hinzufügen.
-
Wählen Sie als Transformationsmethode die Option
Durch infoType-Namen ersetzen aus.
-
Wählen Sie unter infoTypes für die Transformation die
Option
Alle erkannten InfoTypes, die in einer Inspektionsvorlage oder
Inspektionskonfiguration definiert und nicht in anderen Regeln angegeben
sind
aus.
Dadurch werden alle Dateien, die ein Feld mit dem Namen
message enthalten, auf infoTypes geprüft und sensible
Daten entfernt, wenn diese Vorlage zum Ausführen eines Jobs verwendet
wird.
-
Klicken Sie auf Erstellen.
Klicken Sie auf Fortschritt prüfen.
Vorhandene Inspektionsvorlage anpassen und De‑Identifikationsvorlage für
strukturierte Daten erstellen
Aufgabe 3: Erste Erkennungsergebnisse ansehen
Hinweis: Wie bereits erwähnt, kann es nach Beginn des
Konfigurationsscans einige Zeit dauern, bis die vollständigen Ergebnisse
verfügbar sind.
Es ist etwas Zeit vergangen, während Sie die Vorlagen erstellt haben. Jetzt
sind im Looker-Dashboard, das durch den Erkennungsscan generiert wurde, einige
Ergebnisse verfügbar.
In dieser Aufgabe sehen Sie sich die ersten Erkennungsergebnisse an, die in
einem Looker-Dashboard bereitgestellt wurden. Die Daten stammen aus den
Datenprofilinformationen, die in Aufgabe 1 in BigQuery gespeichert wurden.
Zusammenfassung der Ergebnisse im Looker-Dashboard ansehen
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück.
-
Suchen Sie auf dem Tab Erkennung >
Scankonfigurationen nach der Zeile
Cloud Storage-Erkennung. Klicken Sie unter
Data Studio in der entsprechenden Zeile auf
Looker.
-
Klicken Sie unter Autorisierung anfordern auf
Autorisieren.
-
Wählen Sie im Dialogfeld
Konto aus qwiklabs.net auswählen die Option
aus.
-
Klicken Sie unter Datenzugriff prüfen auf
Bestätigen.
-
Klicken Sie für Einwilligung erteilen auf
Zulassen.
-
Sehen Sie sich die Seite
Übersicht der Zusammenfassung an.
Es gibt Datenkacheln, auf denen wichtige Informationen wie Datenrisiko,
Datenvertraulichkeit und Assettypen zusammengefasst sind.
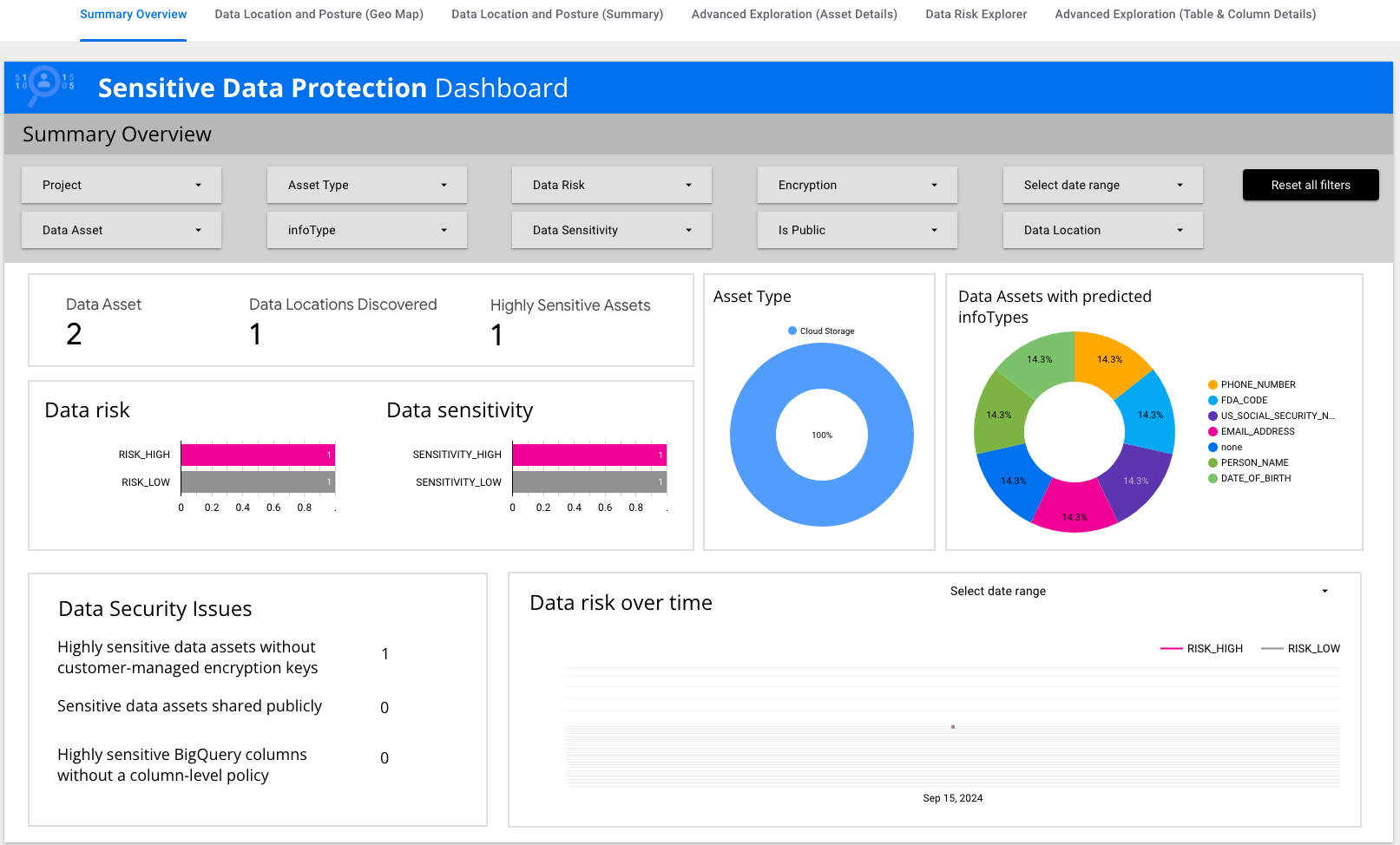
-
Klicken Sie auf Erweiterte Analyse (Assetdetails) und sehen
Sie sich die Tabelle an.
Dort gibt es den infoType US_SOCIAL_SECURITY_NUMBER.
-
Klicken Sie auf Bearbeiten und freigeben.
-
Wählen Sie unter Allgemeine Angaben machen ein beliebiges
Land aus und geben Sie einen Unternehmensnamen ein, z. B. KA.
-
Klicken Sie das Kästchen an, um den Nutzungsbedingungen zuzustimmen, und
klicken Sie dann auf Weiter.
-
Wählen Sie für alle E‑Mail-Einstelungen Nein aus und
klicken Sie dann auf Weiter.
-
Klicken Sie unter
Vor dem Speichern Datenzugriff prüfen auf
Bestätigen und speichern.
-
Klicken Sie in Data Studio auf Ansehen, um den Bericht
aufzurufen.
-
Suchen Sie die Zeile mit dem infoType
US_SOCIAL_SECURITY_NUMBER und klicken Sie in der ersten
Spalte dieser Zeile auf Öffnen.
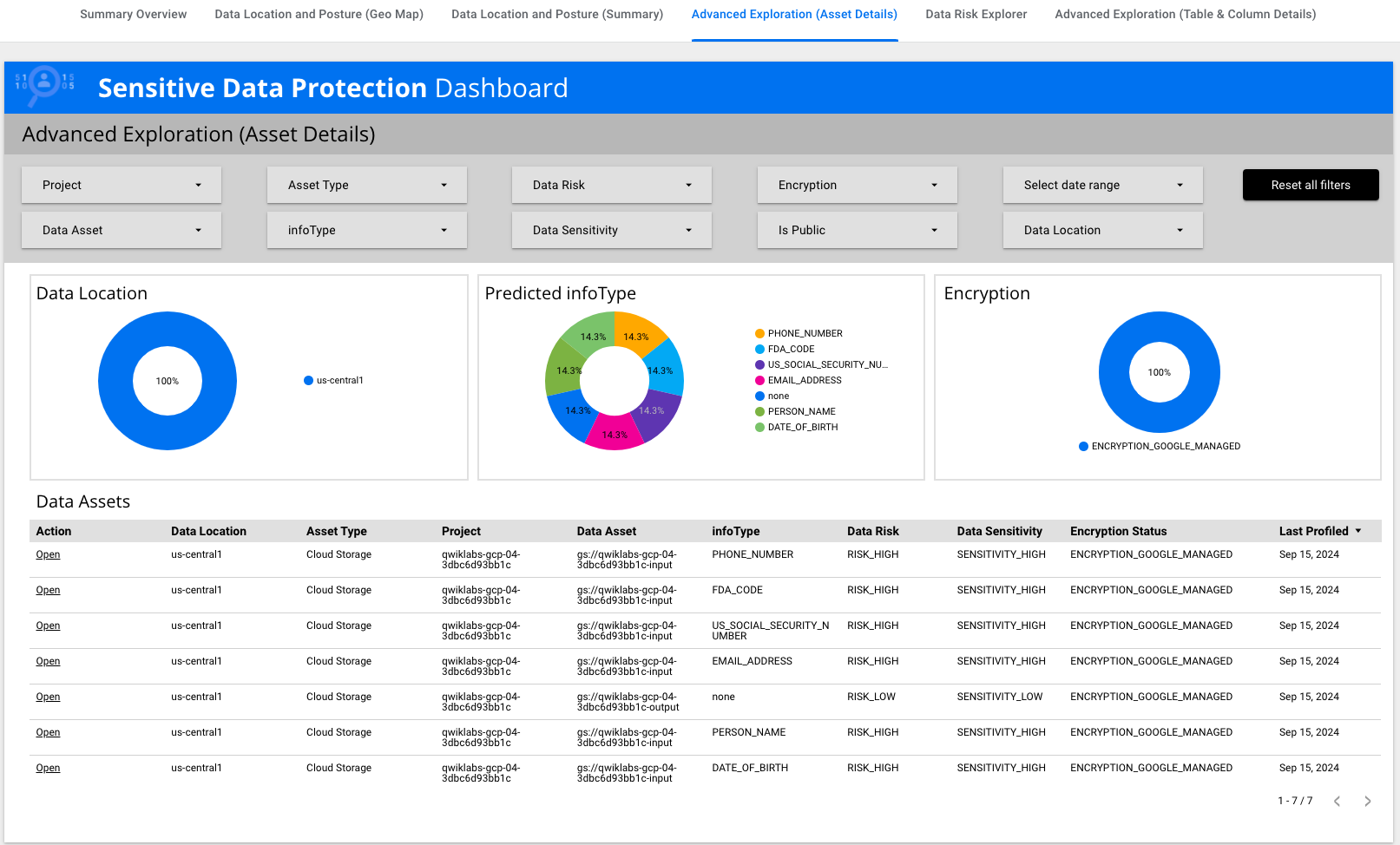
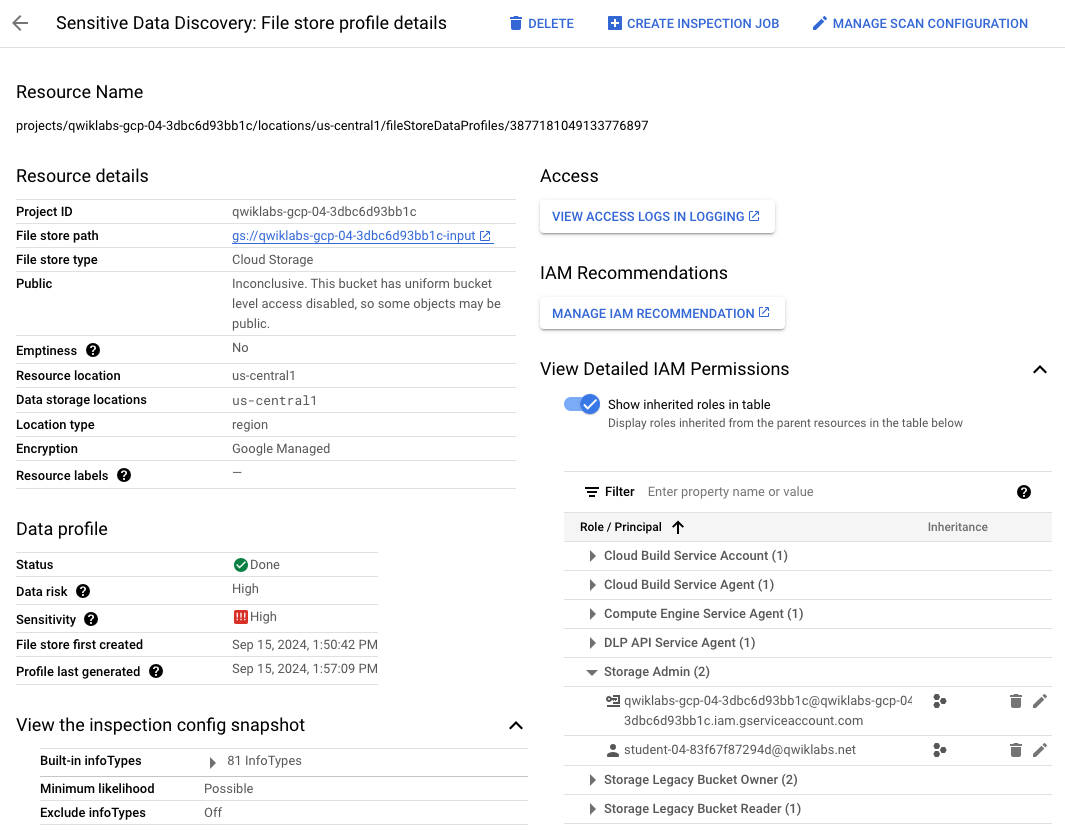
Detaillierte Ergebnisse in Sensitive Data Protection ansehen
-
Achten Sie auf der Seite
Erkennung sensibler Daten: Details zum Dateispeicherprofil in Cloud
Storage
darauf, dass die Projekt-ID
unter Projekt auswählen (in der oberen Menüleiste)
ausgewählt ist, und lesen Sie dann die Seite.
Beachten Sie, dass viele Details zu den gescannten Ressourcen angegeben
werden, einschließlich IAM-Berechtigungen.
-
Klicken Sie auf den Pfeil neben
Detaillierte IAM-Berechtigungen ansehen.
-
Klicken Sie zum Maximieren auf den Pfeil neben
Storage-Administrator.
Sie sehen, dass ein anderes Nutzerkonto () als Cloud Storage-Administrator aufgeführt ist und daher vollen Zugriff auf
die Daten hat.
Aufgabe 4: Inspektionsjob erstellen und ausführen
Bei Sensitive Data Protection besteht ein typischer Workflow nach einem
Erkennungsscan darin, einen detaillierteren
Inspektionsjob
auszuführen, um bestimmte infoTypes genauer zu untersuchen.
In Aufgabe 2 haben Sie eine Inspektionsvorlage für eine detailliertere Prüfung
von US-Sozialversicherungsnummern erstellt. In dieser Aufgabe verwenden Sie
diese Vorlage, um den Inspektionsjob zu erstellen und auszuführen.
Inspektionsjob erstellen und ausführen
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück.
-
Klicken Sie auf den Tab Prüfung und dann auf
Job und Job-Trigger erstellen.
-
Geben Sie unter Eingabedaten auswählen die folgenden
Werte an:
| Attribut |
Wert |
| Job-ID |
us_ssn_inspection |
| Standorttyp |
Multi_region > us (mehrere Regionen in den USA)
|
| Speichertyp |
Google Cloud Storage |
| Standorttyp |
Eine einzelne Datei oder einen Ordnerpfad scannen
|
| URL |
gs://-input/
(darauf achten, am Ende der URL ein / hinzuzufügen)
|
| Rekursiv scannen |
Diese Option aktivieren (darauf achten, am Ende der obigen URL ein
/ hinzuzufügen, damit das möglich ist)
|
| Probenahme |
Wert auf 100 % erhöhen |
| Stichprobenmethode |
Keine Stichproben |
| Dateien |
Wählen Sie TEXT und CSV aus (heben Sie
die Auswahl aller anderen Optionen auf) und klicken Sie auf
OK.
|
-
Klicken Sie auf Weiter.
-
Fügen Sie unter Inspektionsvorlage >
Vorlagenname den Pfad zur Inspektionsvorlage wie unten
angegeben hinzu und ersetzen Sie TEMPLATE_ID durch die
Vorlagen-ID der Inspektionsvorlage, die Sie in Aufgabe 2 geändert haben
(zum Beispiel 7216194786087173213):
projects//locations/global/inspectTemplates/TEMPLATE_ID
Wenn Sie die Vorlagen-ID noch einmal aufrufen möchten, gehen Sie auf der
Übersichtsseite von
Sensitive Data Protection
zum Tab Konfiguration.
Hinweis: Achten Sie darauf, dass der Pfad der Inspektionsvorlage keine
Leerzeichen enthält, wenn Sie ihn dem Vorlagennamen hinzufügen.
-
Übernehmen Sie alle anderen Standardeinstellungen und klicken Sie auf
Weiter.
-
Aktivieren Sie unter Aktionen hinzufügen die Option
In BigQuery speichern sowie das Kästchen
Kontext einschließen.
Mit dieser Option kann der Job sowohl den Speicherort als auch den Inhalt
der potenziell sensiblen Daten in BigQuery kopieren.
-
Geben Sie das Dataset und die Tabelle an (für dieses Lab im Voraus
erstellt), um die Ergebnisse in BigQuery zu speichern:
| Attribut |
Wert |
| Projekt-ID |
|
| Dataset-ID |
cloudstorage_inspection |
| Tabellen-ID |
us_ssn |
-
Aktivieren Sie unter Aktionen hinzufügen auch die Option
In Security Command Center veröffentlichen.
-
Klicken Sie auf Weiter.
-
Lassen Sie die Standardeinstellung für Zeitplan auf
Keine Konfiguration (der Job wird sofort nach Erstellung
ausgeführt), um den Job sofort auszuführen, und klicken Sie auf
Weiter.
Ähnlich wie bei Erkennungsscans können Sie festlegen, dass Inspektionsjobs
nach einem bestimmten Zeitplan ausgeführt werden. In diesem Fall führen Sie
den Job sofort nach seiner Erstellung aus.
-
Klicken Sie auf Erstellen und bestätigen Sie die Erstellung
mit einem Klick auf Erstellung bestätigen.
Bleiben Sie auf dieser Seite und warten Sie, bis der Job abgeschlossen ist.
Wenn der Job den Status Fertig hat, fahren Sie mit dem
nächsten Abschnitt fort.
Ergebnisse des Inspektionsjobs in BigQuery ansehen
Im vorherigen Abschnitt haben Sie die Inspektionsergebnisse in der
BigQuery-Tabelle us_ssn gespeichert. Mit einem Klick unten
können Sie direkt zu BigQuery weitergehen, um sich die Ergebnisse anzusehen.
-
Klicken Sie auf Ergebnisse in BigQuery abrufen.
-
Klicken Sie in BigQuery auf Vorschau, um den Inhalt der
Tabelle zu sehen.
Beachten Sie die Spalte quote. Sie enthält eine Kopie des
genauen Werts, der vom Inspektionsjob zur weiteren Überprüfung
gekennzeichnet wurde. Sie können auch in der Tabelle nach rechts scrollen
und sich die Spalte container name ansehen, um den Namen
der Datei zu sehen, die den zitierten Wert enthält.
Klicken Sie auf Fortschritt prüfen.
Inspektionsjob erstellen und ausführen
Aufgabe 5: De‑Identifikationsjob erstellen und ausführen
Über die Erkennung hinaus können Sie einen weiteren Sensitive Data
Protection-Dienst namens
De‑Identifikation
nutzen. Mit diesem Dienst können Sie das Risiko für sensible Daten in Cloud
Storage mindern, indem Sie einen De‑Identifikationsjob ausführen, der dann
Kopien von Cloud Storage-Dateien erstellt, in denen die sensiblen Daten
entfernt wurden. Diese neuen Kopien können anstelle der Originalversionen, die
die sensiblen Daten enthalten, für nachgelagerte Workflows freigegeben werden.
In dieser Aufgabe erstellen und führen Sie einen De‑Identifikationsjob mit der
De‑Identifikationsvorlage aus, die Sie in Aufgabe 2 erstellt haben.
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück.
-
Klicken Sie auf den Tab Prüfung und dann auf
Job und Job-Trigger erstellen.
-
Geben Sie unter Eingabedaten auswählen die folgenden
Werte an:
| Attribut |
Wert |
| Job-ID |
us_ssn_deidentify |
| Standorttyp |
Multi_region > us (mehrere Regionen in den USA)
|
| Speichertyp |
Google Cloud Storage |
| Standorttyp |
Einen Bucket mit optionalen Ein- oder Ausschlussregeln
scannen
|
| Bucket-Name |
-input
|
| Probenahme |
Wert auf 100 % erhöhen |
| Stichprobenmethode |
Keine Stichproben |
| Dateien |
Wählen Sie TEXT und CSV aus (heben Sie
die Auswahl aller anderen Optionen auf) und klicken Sie auf
OK.
|
Hinweis: Der Bucket-Name darf keine Leerzeichen enthalten.
-
Klicken Sie unter Pfade ausschließen auf
RegEx für auszuschließende Dateimuster hinzufügen. Geben
Sie für Pfade ausschließen Folgendes ein:
ignore.
Der Wert Pfade ausschließen 1 lautet jetzt:
gs://-input/ignore
Mit dieser Option können Sie den De‑Identifikationsjob anweisen, Dateien im
Unterverzeichnis ignore zu ignorieren.
-
Übernehmen Sie für alle anderen Einstellungen die Standardwerte und klicken
Sie auf Weiter.
Sie fügen keinen Wert für die Inspektionsvorlage hinzu. In einem der nächsten
Schritte definieren Sie stattdessen den Wert für die
De‑Identifikationsvorlage.
-
Übernehmen Sie unter Erkennung konfigurieren alle
Standardeinstellungen und klicken Sie auf Weiter.
-
Scrollen Sie unter Aktionen hinzufügen nach unten und
aktivieren Sie De‑identifizierte Kopie erstellen.
-
Geben Sie unter
Strukturierte De‑Identifikationsvorlage die
De‑Identifikationsvorlage ein, die Sie zuvor für strukturierte Dateien
(zum Beispiel CSV- und Textdateien) erstellt haben:
projects//locations/global/deidentifyTemplates/us_ssn_deidentify
Hinweis: Achten Sie darauf, dass die Pfade der
De‑Identifikationsvorlage keine Leerzeichen enthalten.
-
Aktivieren Sie
Details zur Transformation nach BigQuery exportieren und
geben Sie das Dataset und die Tabelle an (für dieses Lab im Voraus
erstellt), um die Ergebnisse in BigQuery zu speichern.
| Attribut |
Wert |
| Projekt-ID |
|
| Dataset-ID |
cloudstorage_transformations |
| Tabellen-ID |
deidentify_ssn_csv |
-
Geben Sie für den
Cloud Storage-Ausgabespeicherort Folgendes an:
gs://-output
Dieser Wert weist den Job an, die Ausgabe ohne sensible Daten in den zweiten
Bucket zu schreiben, der in diesem Lab im Voraus für Ausgabedateien erstellt
wurde.
-
Wählen Sie unter Dateien die Optionen
TEXT und CSV aus (heben Sie die Auswahl
aller anderen Optionen auf) und klicken Sie auf OK.
-
Klicken Sie auf Weiter.
-
Übernehmen Sie für Zeitplan die Standardeinstellung
–, um den Job sofort auszuführen, und klicken Sie auf
Weiter.
Ähnlich wie bei Inspektionsjobs können Sie auch für De‑Identifikationsjobs
einen regelmäßigen Zeitplan (zum Beispiel wöchentlich) festlegen.
-
Klicken Sie auf Erstellen und bestätigen Sie die Erstellung
mit einem Klick auf Erstellung bestätigen.
Bleiben Sie auf dieser Seite und warten Sie, bis der Job abgeschlossen ist.
Wenn der Job den Status Fertig hat, lassen Sie diesen
Browsertab geöffnet und fahren Sie mit dem nächsten Abschnitt fort.
Transformationsdetails zur De‑Identifikation in BigQuery ansehen
Im vorherigen Abschnitt haben Sie die Option ausgewählt, die Details der
De‑Identifikation in der BigQuery-Tabelle
deidentify_ssn_csv zu speichern. In diesem Abschnitt rufen
Sie BigQuery auf, um sich die Transformationsdetails anzusehen.
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü () > BigQuery.
-
Maximieren Sie im Bereich Explorer die Option
> cloudstorage_transformations
und klicken Sie auf die Tabelle deidentify_ssn_csv.
-
Klicken Sie auf Vorschau, um die Ergebnisse zu sehen.
Beachten Sie die Spalten container_name und
transformation.type. Sie enthalten Details zu den
Dateien, die mithilfe bestimmter Transformationsregeln de-identifiziert
wurden.
De‑identifizierte Ausgabe ansehen
-
Kehren Sie zur Seite mit den Ergebnissen des Inspektionsjobs zurück und
klicken Sie auf Konfiguration.
-
Scrollen Sie nach unten zu Aktionen >
Ausgabe-Bucket für de‑identifizierte Cloud Storage-Daten.
-
Klicken Sie auf den Bucket-Link (gs://-output), um zum Cloud Storage-Bucket zu gelangen und sich die
de‑identifizierten Dateien anzusehen.
Klicken Sie auf Fortschritt prüfen.
De‑Identifikationsjob erstellen und ausführen
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
In diesem Lab haben Sie die Erkennung für die kontinuierliche Überwachung
sensibler Daten in Cloud Storage-Dateien aktiviert. Außerdem haben Sie
wiederverwendbare Vorlagen für die Prüfung und De‑Identifikation erstellt und
geändert und Inspektions- und De‑Identifikationsjobs mit der aktivierten
Option ausgeführt, die Jobergebnisse zur weiteren Untersuchung in BigQuery zu
schreiben.
Weitere Informationen
In den folgenden Ressourcen finden Sie weitere Informationen zu Sensitive Data
Protection für Cloud Storage:
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 10. März 2026 aktualisiert
Lab zuletzt am 10. März 2026 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





