GSP1282

Übersicht
Sensitive Data Protection
ist ein vollständig verwalteter Dienst, mit dem Sie sensible Daten erkennen,
klassifizieren und schützen können. Zu den wichtigsten Optionen gehören die
Erkennung sensibler Daten, um kontinuierlich Profile für vertrauliche Daten zu
erstellen, die De-Identifikation sensibler Daten einschließlich ihrer
Entfernung und die Cloud Data Loss Prevention (DLP) API, mit der Sie die
Erkennung, Prüfung und De-Identifikation dieser Daten in benutzerdefinierte
Arbeitslasten und Anwendungen einbinden können.
Sie können sensible Daten in BigQuery schützen, indem Sie Sensitive Data
Protection zusammen mit Identity and Access Management (IAM) in Google Cloud
verwenden. So ist es möglich, sensible Daten bei Erkennungsscans automatisch
zu taggen und Nutzerinnen und Nutzern in Ihrer Organisation bedingten Zugriff
auf BigQuery-Daten zu gewähren.
In diesem Lab erstellen Sie zuerst eine Konfiguration für einen Erkennungsscan
für BigQuery im pausierten Modus. Anschließend erstellen Sie ein Tag, um
sensible Daten in BigQuery zu kennzeichnen, und aktualisieren die
Konfiguration des Erkennungsscans, damit das erstellte Tag für automatisierte
Scans verwendet wird. Zum Schluss verwenden Sie das erstellte Tag, um
zusätzlichen Nutzerinnen und Nutzern bedingten Zugriff auf BigQuery-Daten zu
gewähren.
Lerninhalte
Aufgaben in diesem Lab:
-
Konfiguration für einen Erkennungsscan für BigQuery im pausierten Modus
erstellen
-
Tags erstellen und Rollen für automatisiertes Tagging während des
Erkennungsscans zuweisen
-
Pausierten Erkennungsscan aktualisieren, um die erstellten Tags für das
automatische Tagging zu verwenden, und Scan starten
- Mithilfe von Tags bedingten Zugriff auf BigQuery-Daten gewähren
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
- Schaltfläche „Google Cloud Console öffnen“
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Aufgabe 1: Konfiguration für einen Erkennungsscan für BigQuery im pausierten
Modus erstellen
Mit dem Erkennungsdienst von Sensitive Data Protection können Sie ermitteln,
wo sich sensible und risikoreiche Daten in Ihrer Organisation befinden. Wenn
Sie eine Konfiguration für einen Erkennungsscan erstellen, scannt Sensitive
Data Protection die von Ihnen ausgewählten Ressourcen und generiert
Datenprofile. Diese enthalten Informationen zu den erkannten
infoTypes
(Arten von sensiblen Daten) sowie Metadaten zum Datenrisiko und zur
Vertraulichkeitsstufe.
In dieser Aufgabe erstellen Sie einen Erkennungsscan, um in BigQuery
automatisch Datenprofile zu erstellen. Da es einige Zeit dauern kann, bis die
vollständigen Erkennungsergebnisse generiert wurden, erhalten Sie in der
letzten Aufgabe des Labs Hervorhebungen und Zusammenfassungen für die
wichtigsten Ergebnisse.
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü ( ) > Sicherheit.
) > Sicherheit.
-
Klicken Sie unter Datenschutz auf
Sensitive Data Protection.
-
Klicken Sie auf den Tab Erkennung.
-
Klicken Sie unter BigQuery auf
Aktivieren.
-
Lassen Sie für Erkennungstyp auswählen die Option für
BigQuery aktiviert und klicken Sie auf
Weiter.
-
Lassen Sie unter Bereich auswählen die Option
Ausgewähltes Projekt scannen aktiviert und klicken Sie
auf Weiter.
-
Übernehmen Sie für Verwaltete Zeitpläne die
Standardeinstellung und klicken Sie auf Weiter.
In diesem Lab legen Sie fest, dass der Erkennungsscan sofort nach der
Erstellung ausgeführt wird. Es gibt aber viele Möglichkeiten, Scans
regelmäßig (zum Beispiel täglich oder wöchentlich) oder nach bestimmten
Ereignissen (zum Beispiel bei Aktualisierung einer Inspektionsvorlage)
auszuführen.
-
Lassen Sie unter Inspektionsvorlage auswählen die Option
Neue Inspektionsvorlage erstellen aktiviert.
-
Übernehmen Sie alle anderen Standardeinstellungen und klicken Sie auf
Weiter.
Standardmäßig enthält die neue Inspektionsvorlage alle vorhandenen
infoTypes.
Beim Konfidenzgrenzwert ist die
Mindestwahrscheinlichkeit
standardmäßig auf Möglich eingestellt. Das bedeutet, dass
Sie nur die Ergebnisse erhalten, die als Möglich,
Wahrscheinlich oder
Sehr wahrscheinlich bewertet wurden.
In einer späteren Aufgabe ändern Sie diese Inspektionsvorlage, um andere
Optionen für infoTypes und den Konfidenzgrenzwert zu testen.
-
Aktivieren Sie unter Aktionen hinzufügen die Option
In Security Command Center veröffentlichen.
-
Aktivieren Sie unter Aktionen hinzufügen auch die Option
Datenprofilkopien in BigQuery speichern und geben Sie das
Dataset und die Tabelle an (für dieses Lab im Voraus erstellt), um die
Ergebnisse in BigQuery zu speichern.
| Attribut |
Wert |
| Projekt-ID |
|
| Dataset-ID |
bq_discovery |
| Tabellen-ID |
data_profiles |
Unter der Aktion Ressourcen taggen wird eine Meldung
angezeigt, dass der Dienst-Agent eine bestimmte Rolle benötigt, um das
automatische Tagging durchzuführen.
In der nächsten Aufgabe erstellen Sie die Tags und weisen dem Dienstkonto die
erforderliche Rolle für das automatische Tagging während des Erkennungsscans
zu.
-
Übernehmen Sie alle anderen Standardeinstellungen und klicken Sie auf
Weiter.
-
Lassen Sie für
Speicherort für Konfiguration festlegen die Option für
us (mehrere Regionen in den USA) aktiviert und klicken
Sie auf Weiter.
-
Geben Sie einen Anzeigenamen für diese Konfiguration an:
BigQuery-Erkennung.
-
Aktivieren Sie Scan im pausierten Modus erstellen.
Dadurch wird die Konfiguration für den Erkennungsscan erstellt, der Scan wird
aber noch nicht gestartet. So haben Sie Zeit, die Tags zu erstellen und der
Dienst-Agent-ID für den Erkennungsscan die entsprechende IAM-Rolle zu
gewähren.
-
Klicken Sie auf Erstellen und bestätigen Sie die Erstellung
mit einem Klick auf Konfiguration erstellen.
Klicken Sie auf Fortschritt prüfen.
Konfiguration für einen Erkennungsscan für BigQuery erstellen
Aufgabe 2: Tags erstellen und Rolle für automatische Tagging während des
Erkennungsscans gewähren
In IAM können Sie ein
Tag für die Vertraulichkeitsstufe
erstellen, mit dem Sie Ressourcen bei Erkennungsscans ggf. automatisch getaggt
werden sollen. So lässt sich der Zugriff auf bestimmte Ressourcen, die mit dem
Tag für die Vertraulichkeitsstufe versehen sind, gewähren oder verweigern.
In dieser Aufgabe erstellen Sie in IAM ein Tag für die Vertraulichkeitsstufe
mit vier Tag-Werten, die unterschiedliche Vertraulichkeitsstufen darstellen:
niedrig, moderat, hoch und unbekannt.
Tag für die Vertraulichkeitsstufe in IAM erstellen
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü () > IAM und Verwaltung > Tags.
-
Klicken Sie auf + Erstellen.
-
Geben Sie unter Tag-Schlüssel einen Anzeigenamen für das
Tag ein: sensitivity-level.
-
Geben Sie unter Tag-Beschreibung eine Beschreibung für
dieses Tag ein:
Sensitivity level tagged as low, moderate, high, and unknown.
-
Klicken Sie auf + Wert hinzufügen.
-
Geben Sie unter Tag-Wert einen Anzeigenamen für den
ersten Tag-Wert ein: low.
-
Geben Sie für Beschreibung des Tag-Werts eine
Beschreibung für diesen Tag-Wert ein:
Tag value to attach to low-sensitivity data.
-
Wiederholen Sie die Schritte 5 bis 7, um drei weitere Tag-Werte zu
erstellen:
| Tag-Wert |
Tag-Beschreibung |
moderate |
Tag value to attach to moderate-sensitivity data
|
high |
Tag value to attach to high-sensitivity data
|
unknown |
Tag value to attach to resources with an unknown sensitivity
level
|
- Klicken Sie auf Tag-Schlüssel erstellen.
Es kann einen Moment dauern, bis der Tag-Schlüssel erstellt wurde.
-
Nachdem der Tag-Schlüssel erstellt wurde, klicken Sie auf den Namen des
Tag-Schlüssels, um die Details aufzurufen.
Der Tag-Schlüssel hat einen Tag-Schlüsselpfad (/sensitivity-level) und die folgenden Tag-Werte: high,
low, moderate, unknown.
Wenn Sie den Tag-Schlüsselpfad mit dem Tag-Wert kombinieren, erhalten Sie den
Tag-Wertpfad, den Sie in der nächsten Aufgabe verwenden. Beispiel:
Klicken Sie auf Fortschritt prüfen.
Tag für die Vertraulichkeitsstufe in IAM erstellen
Dienstkonto über IAM Rolle für Erkennungsscan gewähren
Um Ressourcen automatisch zu taggen, benötigt der Dienst-Agent die Rolle
resourcemanager.tagUser. In diesem Abschnitt folgen Sie den
Schritten in der Dokumentation
IAM-Zugriff basierend auf der Datensensibilität steuern, um diese Rolle zu gewähren.
-
Klicken Sie oben in der Google Cloud Console auf
Cloud Shell aktivieren
 .
.
Wenn Sie dazu aufgefordert werden, klicken Sie auf Weiter.
-
Führen Sie den folgenden Befehl aus, um eine Variable für die Projektnummer
Ihres aktuellen Projekts zu erstellen:
export PROJECT_NUMBER=$(gcloud projects describe {{{project_0.project_id | Project ID}}} --format="get(projectNumber)")
Wenn Sie dazu aufgefordert werden, klicken Sie auf
Autorisieren.
-
Führen Sie den folgenden Befehl aus, um dem Dienstkonto für den
Erkennungsscan die Rolle „Tag-Nutzer“ zuzuweisen:
gcloud projects add-iam-policy-binding {{{project_0.project_id | Project ID}}} --member=serviceAccount:service-$PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com --role=roles/resourcemanager.tagUser
Klicken Sie auf Fortschritt prüfen.
Dienstkonto über IAM Rolle für Erkennungsscan gewähren
Aufgabe 3: Pausierten Erkennungsscan mit automatischem Tagging aktualisieren
und Scan starten
Nachdem Sie dem Dienstkonto die entsprechende Rolle für das automatische
Tagging zugewiesen haben, können Sie im Erkennungsscan die Optionen für
„Ressourcen taggen“ aktivieren.
Tag-Werte hinzufügen und Erkennungsscan starten
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück.
-
Suchen Sie auf dem Tab Erkennung >
Scankonfigurationen nach der Zeile
BigQuery-Erkennung. Klicken Sie in dieser Zeile auf
Aktionen ansehen (Symbol mit drei vertikalen Punkten) und
wählen Sie Bearbeiten aus.
-
Aktivieren Sie unter Aktionen hinzufügen die Option
Ressourcen taggen sowie die folgenden zugehörigen
Optionen:
| Attribut |
Wert |
|
Ressourcen mit hoher Vertraulichkeit taggen
|
Geben Sie
/sensitivity-level/high
an.
|
|
Ressourcen mit mittlerer Vertraulichkeit taggen
|
Geben Sie
/sensitivity-level/moderate
an.
|
|
Ressourcen mit niedriger Vertraulichkeit taggen
|
Geben Sie
/sensitivity-level/low
an.
|
|
Ressourcen mit unbekannter Vertraulichkeit taggen
|
Geben Sie
/sensitivity-level/unknown
an.
|
-
Aktivieren Sie außerdem die folgenden beiden Optionen:
-
„Beim Anwenden eines Tags auf eine Ressource das Datenrisiko ihres
Profils auf NIEDRIG setzen.“
-
„Ressource taggen, wenn zum ersten Mal ein Profil für sie erstellt
wird.“
-
Klicken Sie auf Speichern und dann auf
Bearbeitung bestätigen.
-
Klicken Sie auf Scan fortsetzen, um den Erkennungsscan zu
starten.
Klicken Sie auf Fortschritt prüfen.
Pausierten Erkennungsscan mit automatischem Tagging aktualisieren und Scan
starten
Was die Erkennungsergebnisse über Ihre Daten aussagen
Hinweis: Nachdem der Konfigurationsscan gestartet wurde, kann es einige Zeit dauern, bis die vollständigen Ergebnisse verfügbar sind.
Die Bilder unten zeigen die wichtigsten Ergebnisse der Aktivierung der Erkennung für BigQuery in dieser Lab-Umgebung.
Für die in dieser Lab-Umgebung enthaltenen BigQuery-Daten wurde in den
Ergebnissen das potenzielle Vorhandensein mehrerer InfoTypes gemeldet,
darunter US-Sozialversicherungsnummern, was sehr vertrauliche Daten sind.
Bild 1. Erkennung für BigQuery in der UI aktiviert
Für BigQuery wurden drei Profile identifiziert: zwei mit niedriger
Vertraulichkeit (ein Dataset für die Erkennungsergebnisse und ein Dataset für
Metadaten von Bildern beschädigter Autos) und eines mit hoher Vertraulichkeit
(Dataset mit Details zu Autokäufern).
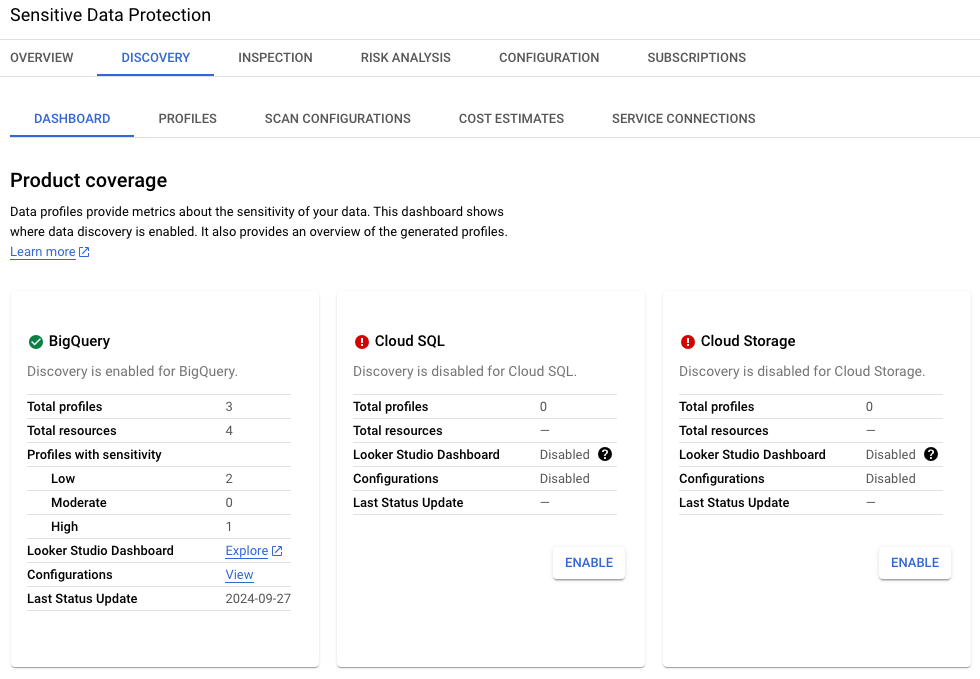
Bild 2. Details zum Inventar sensibler Daten
In diesem Abschnitt der Ergebnisse wird der globale Standort der drei
Datenprofile angegeben. In diesem Beispiel befinden sich beide in der Region
us-central1.
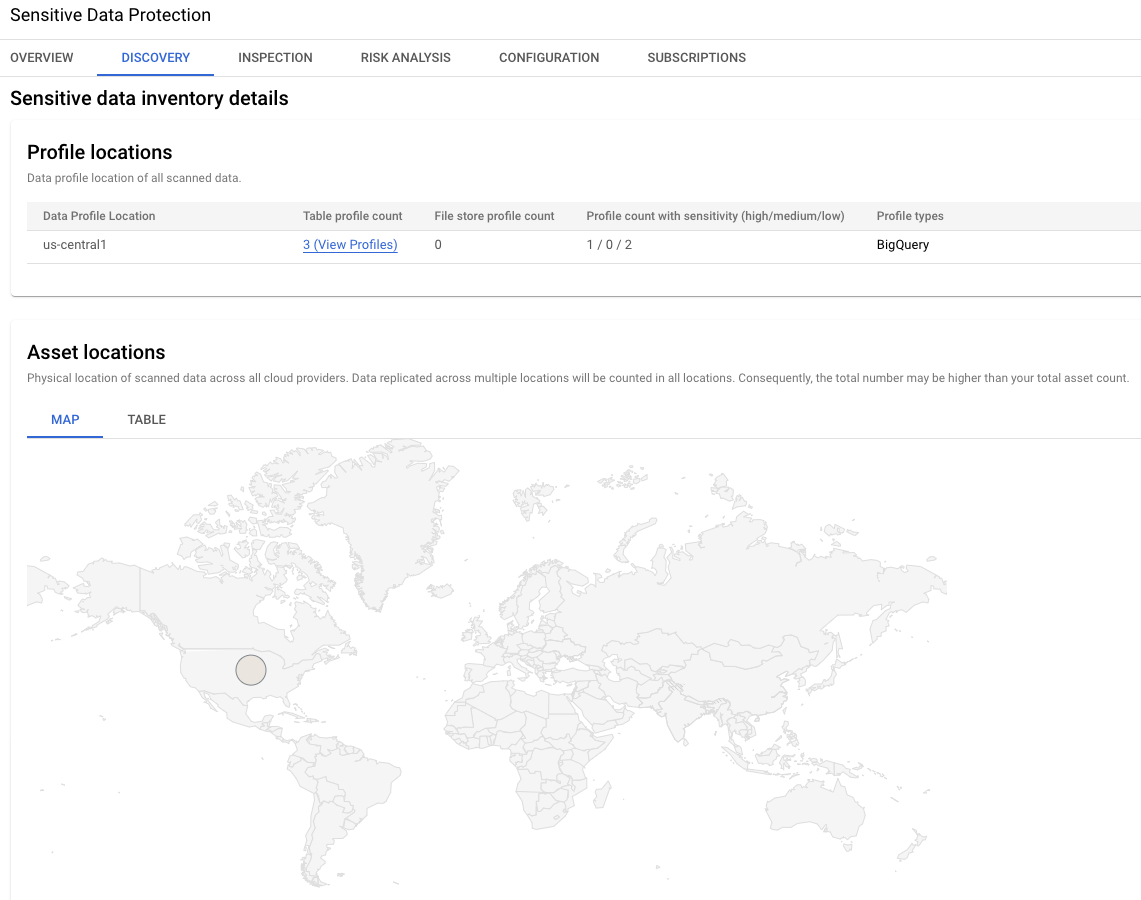
Bild 3. BigQuery-Profile mit infoTypes
Die Ergebnisse der Erkennung enthalten auch die wichtigsten in BigQuery
identifizierten InfoTypes: US-Sozialversicherungsnummer, E‑Mail-Adresse, Name
und andere.
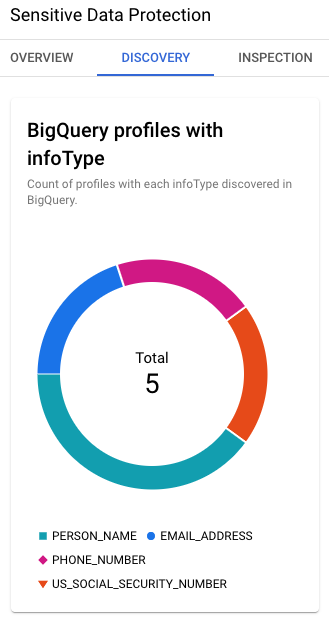
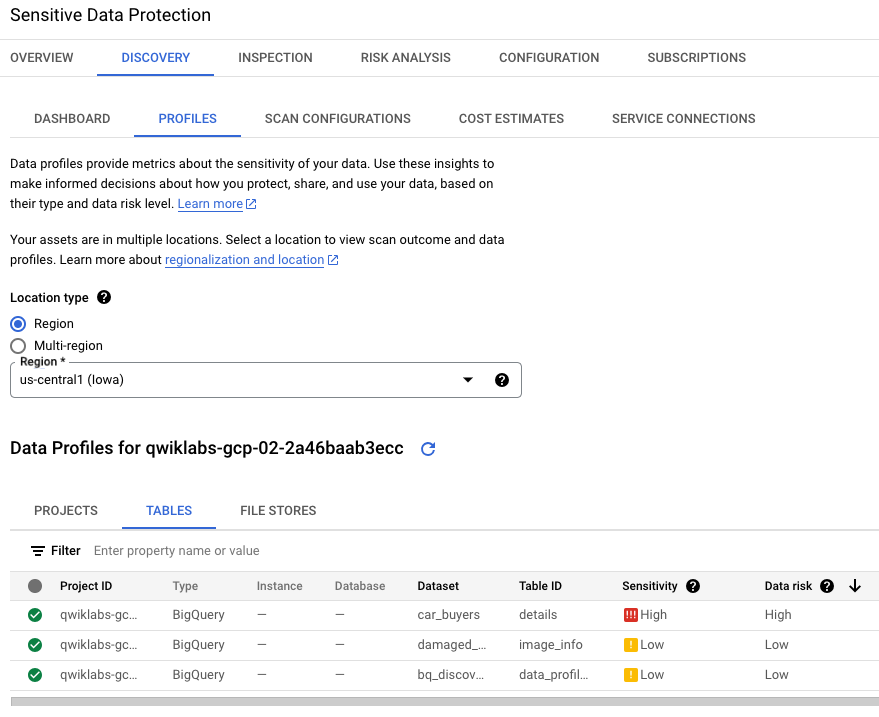
Bild 4. Tab „Profile“ der Erkennungsergebnisse
Auf dem Tab Profile werden die Vertraulichkeits- und
Risikostufen für jeden spezifischen BigQuery-Dataset-Namen angegeben: einen
mit niedriger Vertraulichkeit (leerer Bucket für die Ausgabe von Jobs) und
einen mit hoher Vertraulichkeit (Bucket mit Rohdaten, einschließlich
US-Sozialversicherungsnummer).
Wählen Sie in dieser Lab-Umgebung als Standorttyp die Option
Region >
aus, um die Profile aufzurufen.
Aufgabe 4: Bedingten Zugriff für BigQuery mit Tags untersuchen
Mit IAM können Sie einem Nutzerkonto eine Rolle basierend auf einem Tag für
die Vertraulichkeitsstufe zuweisen, das mithilfe
bedingter Rollenbindungen
an eine bestimmte Ressource angehängt ist. Sie können beispielsweise diesem
Nutzerkonto Zugriff nur auf BigQuery-Daten gewähren, die als wenig sensibel
getaggt wurden. Das Nutzerkonto hätte keinen Zugriff mehr auf
BigQuery-Ressourcen ohne dieses Tag, einschließlich nicht getaggter
BigQuery-Ressourcen.
In dieser Aufgabe sehen Sie sich zuerst die vorhandenen
BigQuery-Zugriffsberechtigungen an, die in dieser Lab-Umgebung Username 2
gewährt wurden. Anschließend aktualisieren Sie den Zugriff für Username 2,
sodass er vom Tag für Daten mit niedriger Vertraulichkeit abhängig ist, und
weisen einem der BigQuery-Datasets manuell dieses Tag zu. Zum Schluss testen
Sie den aktualisierten BigQuery-Zugriff für Username 2, um zu bestätigen, dass
es sich um bedingten Zugriff handelt.
Aktuellen BigQuery-Zugriff für Username 2 testen
Melden Sie sich für diesen Abschnitt im Google Cloud-Projekt als
Username 2 () an. Wenn Sie Hilfe beim Wechseln zu einem neuen Nutzerkonto benötigen,
maximieren Sie den unten stehenden Hinweis.
Vollständige Lösung (maximieren, um alle Schritte zu sehen)
Führen Sie als Username 2 die folgenden Schritte aus, um den vorhandenen
BigQuery-Zugriff zu prüfen, der Username 2 gewährt wurde.
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü () > BigQuery.
-
Klicken Sie im Bereich „Explorer“ auf den Pfeil neben der Projekt-ID
(), um die Liste der BigQuery-Datasets aufzurufen.
Es gibt vier BigQuery-Datasets:
-
bq_discovery: zum Speichern der durch den
Erkennungsscan generierten Profile
-
bq_inspection: zum Speichern der durch die Prüfung
generierten Ergebnisse
-
car_buyers: enthält sensible Daten von Autokäufern, zum
Beispiel US-Sozialversicherungsnummern
-
damaged_car_image_info: enthält nicht sensible Daten zu
beschädigten Autos
IAM-Rollen für Username 2 aktualisieren
Melden Sie sich für diesen Abschnitt wieder im Google Cloud-Projekt als
Username 1 () an. Wenn Sie Hilfe beim Wechseln zu einem neuen Nutzerkonto benötigen,
maximieren Sie den unten stehenden Hinweis.
Vollständige Lösung (maximieren, um alle Schritte zu sehen)
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü () > IAM und Verwaltung > IAM.
-
Suchen Sie die Zeile für Username 2 () und klicken Sie auf
Hauptkonto bearbeiten (Stiftsymbol).
-
Suchen Sie die Zeile für die Rolle Betrachter und klicken
Sie auf Rolle löschen (Papierkorbsymbol).
-
Klicken Sie auf Weitere Rolle hinzufügen.
-
Wählen Sie unter Rolle auswählen die Option
Einfach > Sucher aus.
-
Suchen Sie die Zeile für die Rolle
BigQuery-Datenbetrachter und klicken Sie auf
IAM-Bedingung hinzufügen.
-
Geben Sie als Titel Folgendes ein:
Low Sensitivity Data Access Only.
-
Wählen Sie unter Tool zur Bedingungserstellung für
Bedingungstyp 1 die Option Tag und für
Operator die Option hat einen Wert aus.
-
Geben Sie für Wertpfad den Tag-Wert für Ressourcen mit
niedriger Vertraulichkeit ein, den Sie in Aufgabe 3 verwendet haben.
Maximieren Sie den Hinweis, um den Tag-Wert zu sehen, falls Sie eine
Erinnerung benötigen.
-
Klicken Sie auf Speichern und anschließend noch einmal auf
Speichern.
Tag mit niedriger Vertraulichkeit dem BigQuery-Dataset hinzufügen
Bleiben Sie für diesen Abschnitt als Username 1 () angemeldet.
Der vollständige Erkennungsscan dauert wie gesagt eine Weile. Daher gibt es
noch keine BigQuery-Datasets, die mit den Tags für die Vertraulichkeitsstufe
versehen wurden.
Um den bedingten Zugriff zu testen, weisen Sie dem BigQuery-Dataset
damaged_car_image_info, das keine sensiblen Daten enthält,
manuell das Tag für niedrige Vertraulichkeit zu.
-
Klicken Sie in der Google Cloud Console auf das
Navigationsmenü () > BigQuery.
-
Klicken Sie im Bereich „Explorer“ auf den Pfeil neben der Projekt-ID
(), um die Liste der BigQuery-Datasets aufzurufen.
-
Klicken Sie auf damaged_car_image_info, um den Tab mit
den Dataset-Informationen zu öffnen, und klicken Sie dann auf
Details bearbeiten (Stiftsymbol).
-
Klicken Sie unter Tags auf
Bereich auswählen >
Aktuelles Projekt auswählen.
-
Wählen Sie die folgenden Details aus.
| Attribut |
Wert |
| Schlüssel 1 |
sensitivity-level |
| Wert 1 |
low |
- Klicken Sie auf Speichern.
Bedingten BigQuery-Zugriff als Username 2 testen
Melden Sie sich für diesen Abschnitt ein letztes Mal im Google Cloud-Projekt
als Username 2 () an. Wenn
Sie Hilfe beim Wechseln zu einem neuen Nutzerkonto benötigen, maximieren Sie
den unten stehenden Hinweis.
Vollständige Lösung (maximieren, um alle Schritte zu sehen)
Führen Sie als Username 2 die folgenden Schritte aus, um den bedingten
BigQuery-Zugriff zu prüfen, der Username 2 gewährt wurde.
-
Kehren Sie zu BigQuery zurück, indem Sie auf das
Navigationsmenü () > BigQuery klicken.
-
Klicken Sie im Bereich des Daten-Explorers auf den Pfeil neben der
Projekt-ID (), um die Liste der BigQuery-Datasets aufzurufen.
Nachdem die IAM-Rolle mit der entsprechenden Bedingung aktualisiert wurde,
wird nur ein BigQuery-Dataset aufgeführt, da es das einzige mit dem Tag
für niedrige Vertraulichkeit ist:
Hinweis: Es kann 5 bis 10 Minuten dauern, bis die Aktualisierungen der IAM-Rolle vollständig wirksam werden. Aktualisieren Sie die BigQuery-Seite. Es sollte nur noch ein BigQuery-Dataset vorhanden sein: damaged_car_image_info.
- Melden Sie sich als Username 2 vom Projekt ab.
Klicken Sie auf Fortschritt prüfen.
Bedingten Zugriff für BigQuery mit Tags untersuchen
Aufgabe 5: Erste Erkennungsergebnisse ansehen
Hinweis: Wie bereits erwähnt, kann es nach Beginn des Konfigurationsscans einige Zeit dauern, bis die vollständigen Ergebnisse verfügbar sind.
Es ist etwas Zeit vergangen, während Sie einem anderen Nutzerkonto bedingten Zugriff gewährt und diesen getestet haben. Jetzt sind im Looker-Dashboard, das durch den Erkennungsscan generiert wurde, einige Ergebnisse verfügbar.
Melden Sie sich für diesen Abschnitt wieder im Google Cloud-Projekt als
Username 1 () an.
Wenn Sie Hilfe beim Wechseln zu einem neuen Nutzerkonto benötigen, maximieren
Sie den unten stehenden Hinweis.
Vollständige Lösung (maximieren, um alle Schritte zu sehen)
Zusammenfassung der Ergebnisse im Looker-Dashboard ansehen
-
Kehren Sie zur Übersichtsseite von
Sensitive Data Protection
zurück.
-
Suchen Sie auf dem Tab Erkennung >
Scankonfigurationen nach der Zeile
BigQuery-Erkennung. Klicken Sie unter
Data Studio in der entsprechenden Zeile auf
Looker.
-
Klicken Sie unter Autorisierung anfordern auf
Autorisieren.
-
Wählen Sie im Dialogfeld
Konto aus qwiklabs.net auswählen die Option
aus.
-
Sehen Sie sich die Zusammenfassungsübersicht an.
Es gibt Datenkacheln, auf denen wichtige Informationen wie Datenrisiko,
Datenvertraulichkeit und Assettypen zusammengefasst sind.
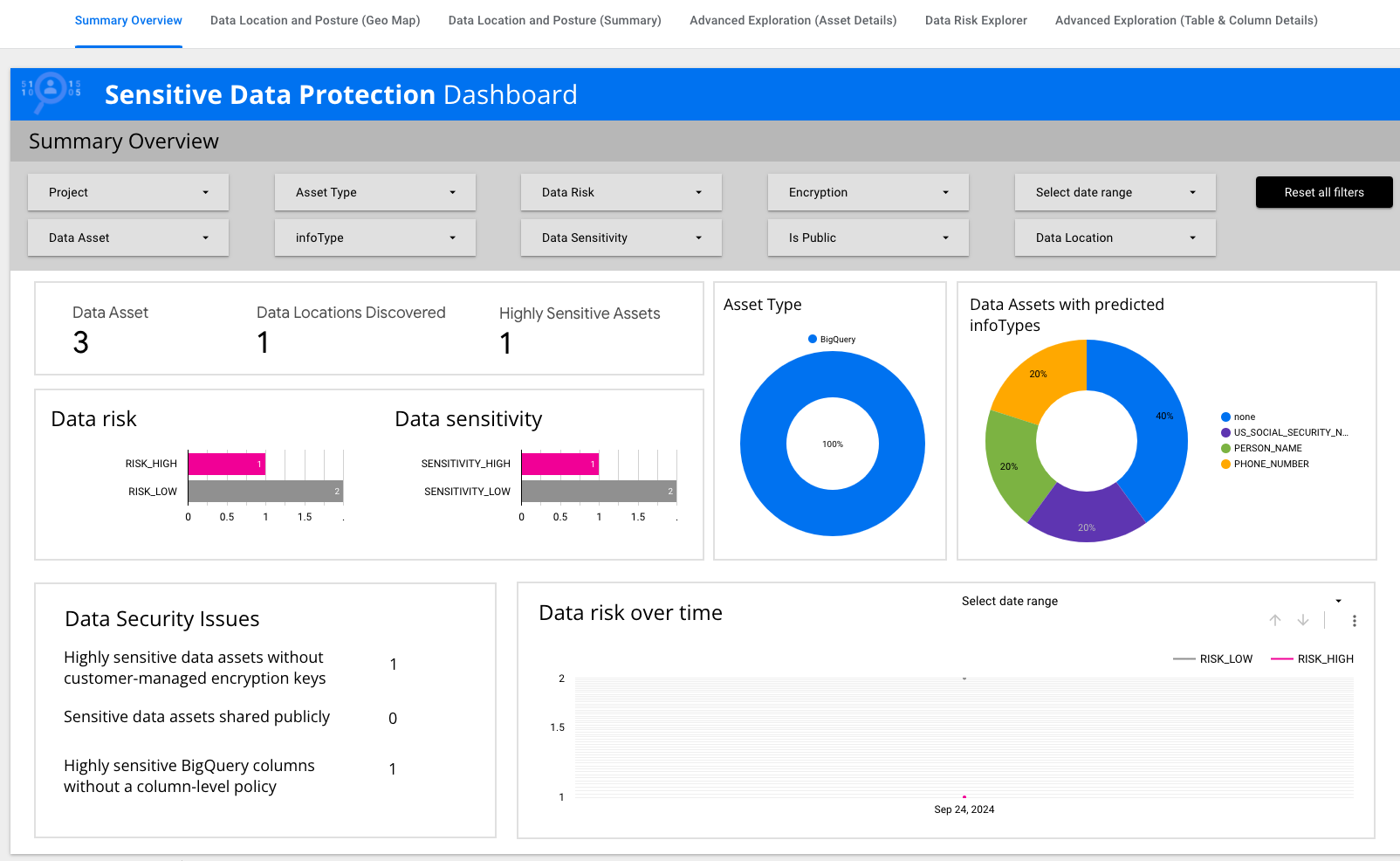
-
Klicken Sie auf Erweiterte Analyse (Assetdetails).
-
Suchen Sie die Zeile mit dem infoType
US_SOCIAL_SECURITY_NUMBER. Klicken Sie in der Spalte „Aktion“
auf Öffnen.
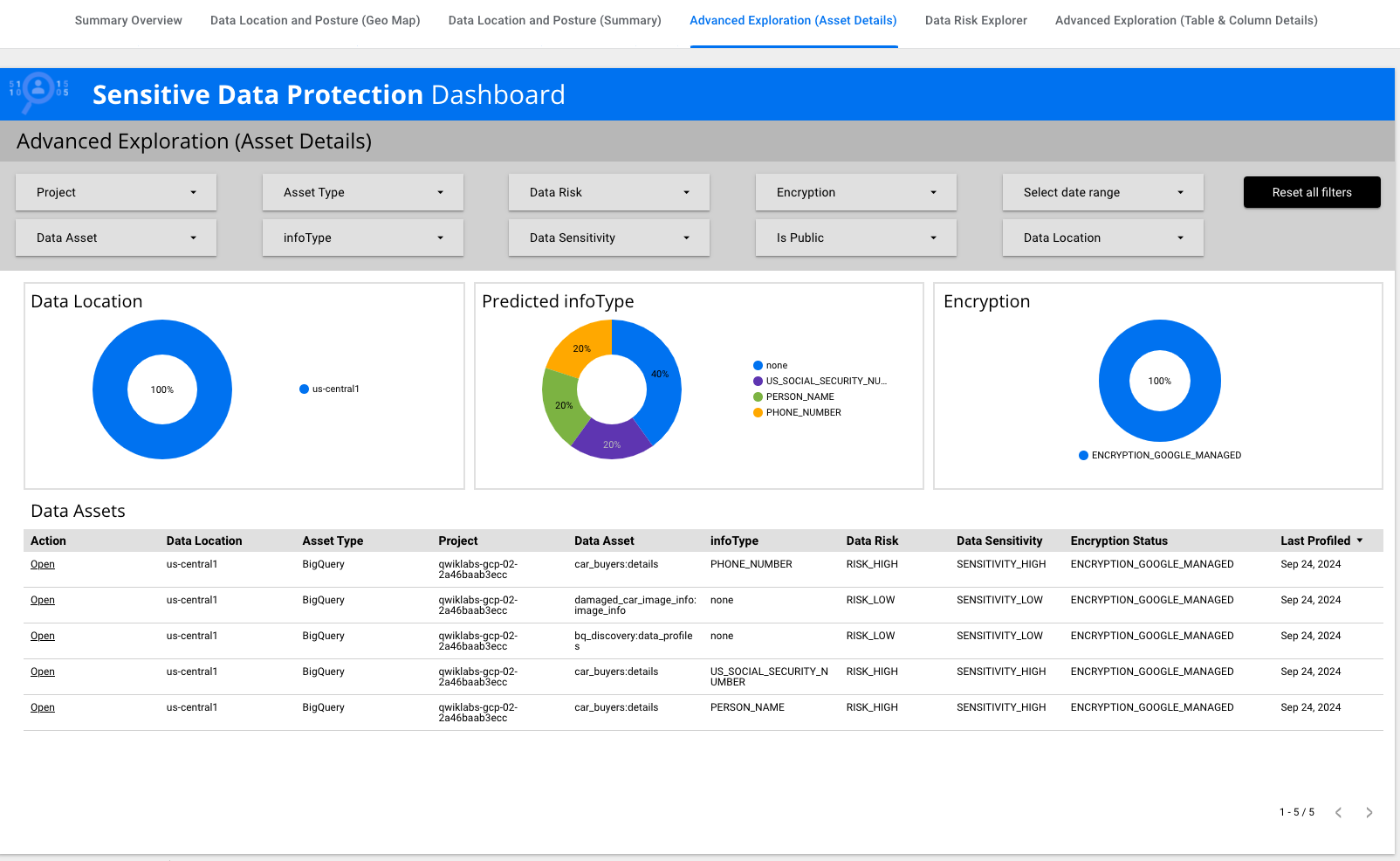
Detaillierte Ergebnisse in Sensitive Data Protection ansehen
-
Lesen Sie die Seite mit dem Titel
Erkennung sensibler Daten: Details zum Dateispeicherprofil.
Beachten Sie, dass viele Details zu den gescannten Ressourcen angegeben
werden, einschließlich IAM-Berechtigungen.
-
Klicken Sie auf den Pfeil neben
Detaillierte IAM-Berechtigungen ansehen.
-
Klicken Sie auf den Pfeil neben BigQuery-Datenbetrachter.
Ein anderes Nutzerkonto () ist als BigQuery-Datenbetrachter mit der in Aufgabe 3 festgelegten
Bedingung aufgeführt.
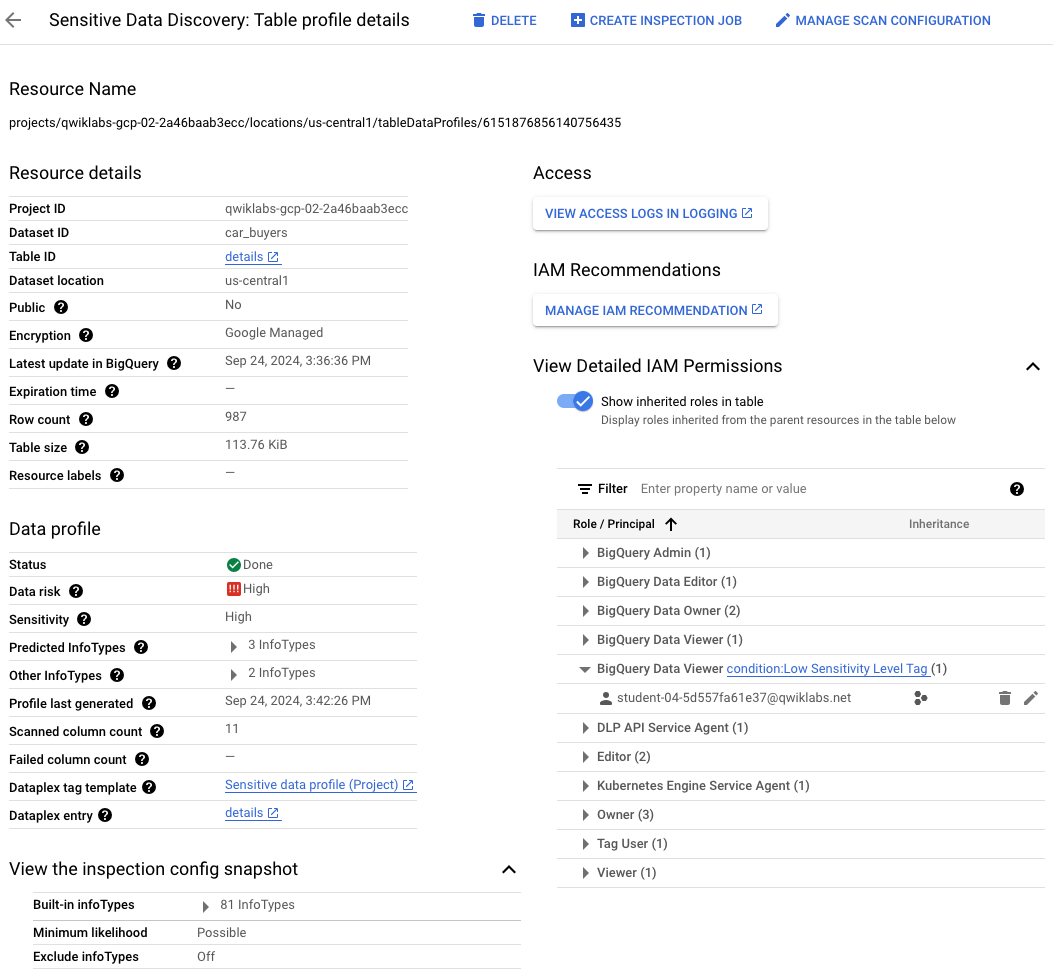
Glückwunsch!
In diesem Lab haben Sie eine Konfiguration für einen Erkennungsscan für
BigQuery im pausierten Modus erstellt. Anschließend haben Sie ein Tag
erstellt, um sensible Daten in BigQuery zu kennzeichnen, und die Konfiguration
des Erkennungsscans aktualisiert, um das erstellte Tag für automatisierte
Scans zu verwenden. Zum Schluss haben Sie das erstellte Tag verwendet, um
zusätzlichen Nutzerkonten bedingten Zugriff auf BigQuery-Daten zu gewähren.
Weitere Informationen
Weitere Informationen zu Sensitive Data Protection für BigQuery finden Sie in
den folgenden Ressourcen:
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 18. November 2024 aktualisiert
Lab zuletzt am 18. November 2024 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





