管理 AlloyDB 数据库
实验
30 分钟
universal_currency_alt
1 个点数
show_chart
入门级
info
此实验可能会提供 AI 工具来支持您学习。

此内容尚未针对移动设备进行优化。
为获得最佳体验,请在桌面设备上访问通过电子邮件发送的链接。
GSP1086

概览
AlloyDB for PostgreSQL 是一项兼容 PostgreSQL 的全托管式数据库服务,适用于要求严苛的企业数据库工作负载。AlloyDB 结合了 Google 的技术精华和最受欢迎的开源数据库引擎之一 PostgreSQL,可提供卓越的性能、伸缩能力和可用性。
在本实验中,您将执行一些管理任务,这些任务对于 AlloyDB for PostgreSQL 数据库的优化使用至关重要。
您将执行的操作
在本实验中,您将学习如何执行以下任务:
- 检查数据库标志
- 设置数据库扩展程序
- 为现有集群创建读取池实例
- 设置备份
- 查看 AlloyDB 控制台中的监控信息中心
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式(推荐)或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:请仅使用学生账号完成本实验。如果您使用其他 Google Cloud 账号,则可能会向该账号收取费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
- “打开 Google Cloud 控制台”按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在“实验详细信息”窗格中找到“用户名”。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在“实验详细信息”窗格中找到“密码”。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。
注意:在本实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于这是临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需访问 Google Cloud 产品和服务,请点击导航菜单,或在搜索字段中输入服务或产品的名称。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
-
点击 Google Cloud 控制台顶部的激活 Cloud Shell  。
。
-
在弹出的窗口中执行以下操作:
- 继续完成 Cloud Shell 信息窗口中的设置。
- 授权 Cloud Shell 使用您的凭据进行 Google Cloud API 调用。
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID 。输出内容中有一行说明了此会话的 Project_ID:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
gcloud auth list
- 点击授权。
输出:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (可选)您可以通过此命令列出项目 ID:
gcloud config list project
输出:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注意:如需查看在 Google Cloud 中使用 gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
任务 1. 检查数据库标志
-
在您开始本实验时,系统已预配 AlloyDB 集群和实例。在 Cloud 控制台的导航菜单 ( ) 中,点击查看所有产品。在数据库部分中,依次点击 AlloyDB 和集群,以查看集群的详细信息。
) 中,点击查看所有产品。在数据库部分中,依次点击 AlloyDB 和集群,以查看集群的详细信息。
-
集群名为 lab-cluster,实例名为 lab-instance。
-
实例需要一段时间才能完全创建和初始化。请等待状态显示为准备就绪后再继续。
-
请记下实例部分中的专用 IP 地址。将专用 IP 地址复制到文本文件中,以便在后续步骤中粘贴该值。
-
在实例的配置中,还设置了 enable_pgaudit 数据库标志。pgaudit 是 PostgreSQL 的一项热门功能,可通过标准日志记录工具提供详细的会话和对象审核日志记录。如需完全启用 pgaudit,您还必须启用相应的数据库扩展程序,这将在下一部分中完成。
-
在集群中的实例部分中,选择 lab-instance,然后点击修改主实例。
-
如需向实例添加数据库标志,请展开高级配置选项,然后点击添加数据库标志。
-
浏览可用标志列表(位于选择标志中),了解受支持的选项。在本实验中,您不用添加其他标志。
-
点击两次取消,退出修改主实例界面。
任务 2. 设置数据库扩展程序
-
接下来,您将设置数据库扩展程序,以便为 AlloyDB 集群完全启用 pgaudit 功能。
-
与配置标志不同,您必须通过 psql 客户端连接到实例,才能启用数据库扩展程序。
-
在导航菜单 () 中,点击 Compute Engine 下的虚拟机实例。
-
对于名为 alloydb-client 的实例,在连接列中点击 SSH,打开一个终端窗口。
-
设置以下环境变量,并将 ALLOYDB_ADDRESS 替换为 AlloyDB 实例的专用 IP 地址。
export ALLOYDB=ALLOYDB_ADDRESS
- 运行以下命令,将 AlloyDB 实例的专用 IP 地址存储在 AlloyDB 客户端虚拟机上,以便在整个实验过程中保留该地址。
echo $ALLOYDB > alloydbip.txt
- 使用以下命令启动 PostgreSQL (psql) 客户端。系统会提示您提供 postgres 用户的密码 (Change3Me),该密码是您在创建集群时输入的。
psql -h $ALLOYDB -U postgres
- 系统会显示 psql 终端提示,如下所示。
psql (14.5 (Debian 14.5-1.pgdg110+1), server 14.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=>
- 分别输入并运行以下 SQL 命令,以启用扩展程序。
\c postgres
CREATE EXTENSION IF NOT EXISTS PGAUDIT;
- 运行以下系统查询,查看有关 pgaudit 扩展程序的详细信息。
select extname, extversion from pg_extension where extname = 'pgaudit';
extname | extversion
---------+------------
pgaudit | 1.6.1
(1 row)
-
输入 \q 以退出 psql 客户端。
-
输入 exit 以关闭终端窗口。
-
点击检查我的进度以验证是否完成了以下目标:
启用 pgaudit 扩展程序
任务 3. 为现有集群创建读取池实例
- AlloyDB for PostgreSQL 的一项关键特性是实现了读取池实例。读取池实例通过聚合节点(您可以扩缩这些节点)来增加集群的读取容量,从而实现读取的高可用性。
我们并不强制要求在集群中设置任何读取池实例,但与主实例相比,读取池实例可更好地支持数据分析工作负载。因此,它们是满足数据分析需求的理想选择。
-
如需添加读取池实例,请在集群的概览页面中,点击集群中的实例部分中的添加读取池或添加读取池实例。
-
对于读取池实例 ID,输入 lab-instance-rp1。将节点数设置为 2。
-
对于机器类型,选择 2 个 vCPU、16 GB。
-
点击创建读取池。
-
创建读取池实例大概需要 8 到 11 分钟。
-
您的读取池实例现在会显示在概览页面上。请注意,专用 IP 与主实例位于同一地址池中。通过直接 IP 地址,您可以将读取专用查询分流到读取池,从而提升整体集群性能。
-
点击检查我的进度以验证是否完成了以下目标:
创建读取池实例
任务 4. 设置备份
-
默认情况下,系统会在创建每个 AlloyDB 集群时配置自动备份。不过,您可以根据工作负载要求,按需创建备份,以获得更多恢复选项。
-
在 Cloud 控制台导航菜单 () 中,点击查看所有产品,然后在数据库下点击 AlloyDB,再点击备份,以启动“备份”页面。
-
您的实例才刚创建,尚无任何自动备份,因此您接下来要创建按需备份。点击创建备份。
-
确保选择 lab-cluster 作为备份源。
-
为备份输入唯一 ID。在此例中,请输入 lab-backup。
-
点击创建。
AlloyDB 会检查源集群是否处于准备就绪状态,然后启动一个长时间运行的操作来执行备份。在该操作完成之前,备份页面会将相应备份的状态显示为进行中。备份速度因实例大小而异,但在实验环境中,备份应该会在 1 分钟内快速创建。
- 在 Cloud Shell 中,运行以下命令以查看有关备份的更多详细信息。
gcloud beta alloydb backups list
-
恢复备份非常简单。点击备份行末尾的恢复链接。查看备份信息和建议的恢复目标。在本实验中,您不用恢复刚刚创建的备份。点击取消关闭向导。
-
点击检查我的进度以验证是否完成了以下目标:
创建备份
任务 5. 查看 AlloyDB 控制台中的监控信息中心
-
AlloyDB 监控信息中心包含有关集群和实例的使用情况、大小及性能的丰富信息。该信息中心会显示您使用的资源的指标,并允许您监控由此产生的任何趋势。
-
在集群概览中,选择页面左侧的监控链接。
-
lab-instance 上的活动很少,因此目前显示的指标无法提供太多分析洞见。您将使用 Postgres 工具 pgbench 生成一个合成数据集并运行模拟工作负载,使 lab-instance 承受具有代表性的工作负荷。
-
在导航菜单 () 中,点击 Compute Engine 下的虚拟机实例。
-
对于名为 alloydb-client 的实例,在连接列中点击 SSH,打开一个终端窗口。
-
运行以下命令,设置 ALLOYDB 环境变量。
export ALLOYDB=$(cat alloydbip.txt)
- 使用 pgbench 的第一步是创建并填充示例表。运行以下命令以创建四个表。系统会提示您输入 postgres 用户的密码,即 Change3Me。
最大的表 pgbench_accounts 将加载 500 万行。此操作应该很快就能完成。
pgbench -h $ALLOYDB -U postgres -i -s 50 -F 90 -n postgres
pgbench create
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 9.49 s, remaining 0.00 s)
creating primary keys...
done in 13.71 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 9.98 s, primary keys 3.72 s).
- 连接到 psql 客户端并运行以下查询,以验证 pgbench_accounts 表中的行数。系统会提示您输入 postgres 用户的密码,即 Change3Me。
psql -h $ALLOYDB -U postgres
select count (*) from pgbench_accounts;
count
---------
5000000
(1 row)
-
输入 \q 以退出 psql 客户端。
-
运行以下 pgbench 操作,在 lab-instance 上模拟某工作负载。该操作模拟了 50 个客户端的负载,分 2 个线程执行,整个过程持续 3 分钟,每 30 秒轮询一次性能数据。系统会提示您输入 postgres 用户的密码,即 Change3Me。
pgbench -h $ALLOYDB -U postgres -c 50 -j 2 -P 30 -T 180 postgres
- 该工作负载操作完成后将报告本次运行的统计信息。详细信息类似下方所示:
pgbench (14.5 (Debian 14.5-1.pgdg110+1), server 14.4)
starting vacuum...end.
progress: 30.0 s, 1412.2 tps, lat 34.433 ms stddev 25.836
progress: 60.0 s, 1426.6 tps, lat 35.040 ms stddev 25.459
progress: 90.0 s, 1393.2 tps, lat 35.863 ms stddev 33.101
progress: 120.0 s, 1429.8 tps, lat 34.968 ms stddev 31.735
progress: 150.0 s, 1335.4 tps, lat 37.406 ms stddev 30.922
progress: 180.0 s, 1424.8 tps, lat 35.118 ms stddev 28.440
transaction type:
scaling factor: 50
query mode: simple
number of clients: 50
number of threads: 2
duration: 180 s
number of transactions actually processed: 252710
latency average = 35.458 ms
latency stddev = 29.391 ms
initial connection time = 801.012 ms
tps = 1409.393040 (without initial connection time)
-
返回 AlloyDB 监控信息中心,并将时间范围设置为 1 小时。在下方的图块中,您将看到以下各项的详细信息:平均 CPU 利用率、可用内存下限、连接数、每秒事务数、集群存储空间、最长复制延迟时间和活跃节点数。
-
点击左侧的 Query Insights 链接,详细了解 pgbench 操作对该实例发出的查询。
-
在热门查询和标记下,您会看到查询的排序。在下图中,查询 UPDATE pgbench_branches SET ... 是选择负载(按总时长)排序方式时排在首位的查询。您的结果可能会有所不同。
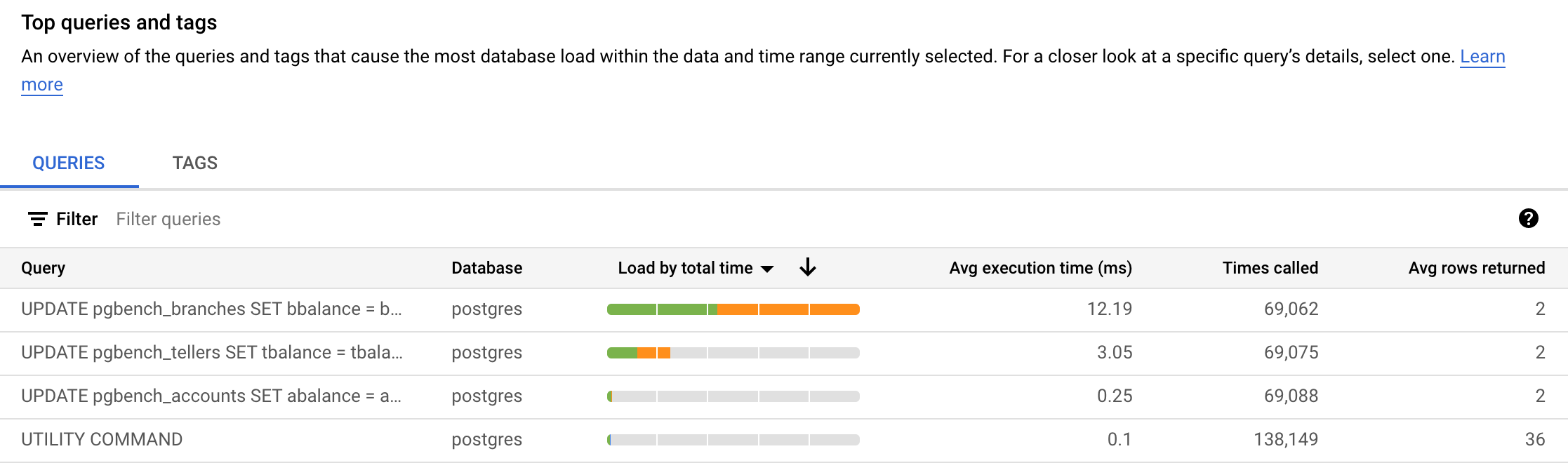
-
负载(按总时长)列有一个选择器选项。您还可以选择负载(按 CPU)、负载(按 IO 等待)和负载(按锁定等待)排序方式查看查询。
-
您可以点击热门查询和标记部分查询列中的任意值,或点击信息中心其他区域中的链接,详细探索查询情况。
恭喜!
您现在已执行对于 AlloyDB for PostgreSQL 数据库的优化使用至关重要的管理任务。
上次更新手册的时间:2024 年 8 月 28 日
上次测试实验的时间:2024 年 8 月 28 日
版权所有 2025 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。





