GSP1086

Visão geral
O AlloyDB para PostgreSQL é um serviço de banco de dados totalmente gerenciado e compatível com PostgreSQL para suas cargas de trabalho mais exigentes em bancos de dados empresariais. O AlloyDB combina o melhor do Google com um dos mecanismos de banco de dados de código aberto mais usados, o PostgreSQL, para desempenho, escala e disponibilidade superiores.
Neste laboratório, você vai realizar tarefas administrativas essenciais para o uso ideal de um banco de dados do AlloyDB para PostgreSQL.
Atividades deste laboratório
Neste laboratório, você vai aprender a:
- Examinar uma flag de banco de dados
- Configurar uma extensão de banco de dados
- Criar uma instância do pool de leitura para um cluster atual
- Configurar backups
- Analisar o Monitoring no console do AlloyDB
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
Clique em Ativar o Cloud Shell  na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.
-
Clique nas seguintes janelas:
- Continue na janela de informações do Cloud Shell.
- Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
- Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Tarefa 1: examinar uma flag de banco de dados
-
Um cluster e uma instância do AlloyDB foram provisionados quando você começou o laboratório. No menu de navegação do console do Cloud ( ), clique em VER TODOS OS PRODUTOS. Na seção Bancos de dados, clique em AlloyDB e em Clusters para examinar os detalhes do cluster.
), clique em VER TODOS OS PRODUTOS. Na seção Bancos de dados, clique em AlloyDB e em Clusters para examinar os detalhes do cluster.
-
O cluster é chamado de lab-cluster, e a instância é chamada de lab-instance.
-
A instância leva algum tempo para ser totalmente criada e inicializada. Aguarde até que o Status seja Pronto para continuar.
-
Anote o endereço IP privado na seção de instâncias. Copie o endereço IP privado em um arquivo de texto para colar o valor em uma etapa posterior.
-
A instância também foi configurada com a flag de banco de dados enable_pgaudit já definida. O Pgaudit é um recurso bastante utilizado do PostgreSQL que oferece registros detalhados de auditoria de sessão e objeto usando o recurso de geração de registros padrão. Para ativar totalmente o pgaudit, também é necessário ativar a extensão de banco de dados correspondente, o que será feito na próxima seção.
-
Na seção Instâncias no cluster, selecione lab-instance e clique em Editar instância principal.
-
Para adicionar uma flag de banco de dados à instância, expanda as Opções de configuração avançada e clique em Adicionar uma flag de banco de dados.
-
Navegue pela lista de flags disponíveis (em Escolher uma flag) para ter uma ideia das opções compatíveis. Você não vai adicionar uma nova flag como parte deste laboratório.
-
Clique em Cancelar duas vezes para sair da tela Editar instância principal.
Tarefa 2: configurar uma extensão de banco de dados
-
Usando o que foi feito na tarefa anterior, você vai configurar uma extensão de banco de dados para ativar totalmente o recurso pgaudit no cluster do AlloyDB.
-
Ao contrário da configuração de uma flag, é necessário se conectar à instância pelo cliente psql para ativar uma extensão de banco de dados.
-
No menu de navegação (), em Compute Engine, clique em Instâncias de VM.
-
Na instância chamada alloydb-client, na coluna Conectar, clique em SSH para abrir uma janela do terminal.
-
Defina a seguinte variável de ambiente, substituindo ALLOYDB_ADDRESS pelo endereço IP privado da instância do AlloyDB.
export ALLOYDB=ALLOYDB_ADDRESS
- Execute o comando a seguir para armazenar o endereço IP privado da instância do AlloyDB na VM do cliente do AlloyDB para que ele persista durante todo o laboratório.
echo $ALLOYDB > alloydbip.txt
- Use o comando a seguir para iniciar o cliente PostgreSQL (psql). Será solicitada a senha do usuário postgres (Change3Me) que você inseriu ao criar o cluster.
psql -h $ALLOYDB -U postgres
- O prompt do terminal psql será exibido, conforme mostrado abaixo.
psql (14.5 (Debian 14.5-1.pgdg110+1), server 14.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=>
- Insira e execute os comandos SQL a seguir separadamente para ativar a extensão.
\c postgres
CREATE EXTENSION IF NOT EXISTS PGAUDIT;
- Execute a consulta de sistema a seguir para conferir detalhes sobre a extensão pgaudit.
select extname, extversion from pg_extension where extname = 'pgaudit';
extname | extversion
---------+------------
pgaudit | 1.6.1
(1 row)
-
Digite \q para sair do cliente psql.
-
Digite exit para fechar a janela do terminal.
-
Clique em Verificar meu progresso para conferir o objetivo.
Ativar a extensão pgaudit
Tarefa 3: criar uma instância do pool de leitura para um cluster atual
- Um dos principais recursos do AlloyDB para PostgreSQL é a implementação de instâncias do pool de leitura. Uma instância do pool de leitura aumenta a capacidade de leitura do cluster agregando nós que podem ser escalonados, o que permite leituras altamente disponíveis.
Não é necessário ter instâncias do pool de leitura em um cluster, mas elas oferecem um melhor suporte para cargas de trabalho de análise de dados do que as instâncias principais. Assim, elas são sua melhor opção em matéria de análise de dados.
-
Para adicionar uma instância do pool de leitura, clique em Adicionar pool de leitura ou Adicionar instância do pool de leitura na seção Instâncias no cluster da página Visão geral do cluster.
-
Em ID da instância do pool de leitura, insira lab-instance-rp1. Defina a Contagem de nós como 2.
-
Selecione 2 vCPUs, 16 GB como tipo de máquina.
-
Clique em Criar pool de leitura.
-
A criação da instância do pool de leitura leva entre 8 e 11 minutos.
-
A instância do pool de leitura agora aparece na página Visão geral. Observe que o IP privado está no mesmo pool de endereços da instância principal. O endereço IP direto permite direcionar consultas específicas de leitura para o pool de leitura, melhorando o desempenho geral do cluster.
-
Clique em Verificar meu progresso para conferir o objetivo.
Criar uma instância do pool de leitura
Tarefa 4: configurar backups
-
Os backups automáticos são configurados por padrão quando todos os clusters do AlloyDB são criados. No entanto, é possível criar backups sob demanda para mais opções de recuperação com base nos requisitos da carga de trabalho.
-
No menu de navegação do console do Cloud (), clique em VER TODOS OS PRODUTOS e, em Bancos de dados, clique em AlloyDB e em Backups para abrir a página Backups.
-
Como sua instância não foi criada há tempo suficiente para receber backups automáticos, vamos criar um backup sob demanda. Clique em Criar backup.
-
Verifique se lab-cluster está selecionado como a origem do backup.
-
Insira um ID exclusivo para o backup. Nesse caso, digite lab-backup.
-
Clique em Criar.
O AlloyDB verifica se o cluster de origem está no estado Pronto e inicia uma operação de longa duração para realizar o backup. A página Backups mostra o backup com o status Em andamento até que a operação seja concluída. A velocidade varia de acordo com o tamanho da instância, mas, no ambiente de laboratório, o backup deve ser criado rapidamente, em 1 minuto.
- No Cloud Shell, execute o comando abaixo para conferir mais detalhes sobre o backup.
gcloud beta alloydb backups list
-
A recuperação de um backup é muito simples. Clique no link Restaurar no final da linha do backup. Inspecione as informações do backup e o destino proposto para recuperação. Neste laboratório, você não vai restaurar o backup que acabou de criar. Clique em Cancelar para fechar o assistente.
-
Clique em Verificar meu progresso para conferir o objetivo.
Criar backup
Tarefa 5: analisar o Monitoring no console do AlloyDB
-
O painel de monitoramento do AlloyDB contém muitas informações sobre o uso, o tamanho e o desempenho dos clusters e das instâncias. O painel mostra as métricas dos recursos que você usa e ajuda a monitorar as tendências resultantes.
-
Na Visão geral do cluster, selecione o link Monitoring no lado esquerdo da página.
-
Como houve pouca atividade em lab-instance, as métricas exibidas no momento não oferecem muitas informações. Você vai usar a ferramenta do Postgres pgbench para gerar um conjunto de dados sintético e executar uma carga de trabalho simulada para colocar lab-instance sob uma carga representativa.
-
No menu de navegação (), em Compute Engine, clique em Instâncias de VM.
-
Na instância chamada alloydb-client, na coluna Conectar, clique em SSH para abrir uma janela do terminal.
-
Execute o comando a seguir para definir a variável de ambiente ALLOYDB.
export ALLOYDB=$(cat alloydbip.txt)
- A primeira etapa para usar o pgbench é criar e preencher as tabelas de exemplo. Execute o comando a seguir para criar um conjunto de quatro tabelas. Será solicitada a senha do usuário postgres, que é Change3Me.
A maior tabela, pgbench_accounts, será carregada com 5 milhões de linhas. A operação será bem rápida.
pgbench -h $ALLOYDB -U postgres -i -s 50 -F 90 -n postgres
pgbench create
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 9.49 s, remaining 0.00 s)
creating primary keys...
done in 13.71 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 9.98 s, primary keys 3.72 s).
- Conecte-se ao cliente psql e execute a consulta a seguir para verificar a contagem de linhas na tabela pgbench_accounts. Será solicitada a senha do usuário postgres, que é Change3Me.
psql -h $ALLOYDB -U postgres
select count (*) from pgbench_accounts;
count
---------
5000000
(1 row)
-
Digite \q para sair do cliente psql.
-
Execute a operação pgbench a seguir para simular uma carga de trabalho em lab-instance. A operação corresponde a uma carga de 50 clientes em duas linhas de execução, fazendo uma sondagem a cada 30 segundos durante três minutos. Será solicitada a senha do usuário postgres, que é Change3Me.
pgbench -h $ALLOYDB -U postgres -c 50 -j 2 -P 30 -T 180 postgres
- A operação da carga de trabalho será concluída e vai gerar estatísticas para a execução. Os detalhes vão aparecer assim:
pgbench (14.5 (Debian 14.5-1.pgdg110+1), server 14.4)
starting vacuum...end.
progress: 30.0 s, 1412.2 tps, lat 34.433 ms stddev 25.836
progress: 60.0 s, 1426.6 tps, lat 35.040 ms stddev 25.459
progress: 90.0 s, 1393.2 tps, lat 35.863 ms stddev 33.101
progress: 120.0 s, 1429.8 tps, lat 34.968 ms stddev 31.735
progress: 150.0 s, 1335.4 tps, lat 37.406 ms stddev 30.922
progress: 180.0 s, 1424.8 tps, lat 35.118 ms stddev 28.440
transaction type:
scaling factor: 50
query mode: simple
number of clients: 50
number of threads: 2
duration: 180 s
number of transactions actually processed: 252710
latency average = 35.458 ms
latency stddev = 29.391 ms
initial connection time = 801.012 ms
tps = 1409.393040 (without initial connection time)
-
Volte ao painel de monitoramento do AlloyDB e defina o horizonte de tempo como 1 hora. Nos blocos abaixo, você encontra detalhes sobre Utilização média de CPU, Memória mínima disponível, Conexões, Transações por segundo, Armazenamento de cluster, Atraso máximo de replicação e Nós ativos.
-
Clique no link Query Insights à esquerda para ver detalhes sobre as consultas que a operação pgbench emitiu na instância.
-
Em Principais consultas e tags, você vai encontrar consultas ordenadas. Na imagem abaixo, UPDATE pgbench_branches SET ... foi a consulta mais frequente por Carga por tempo total. Os resultados podem variar.
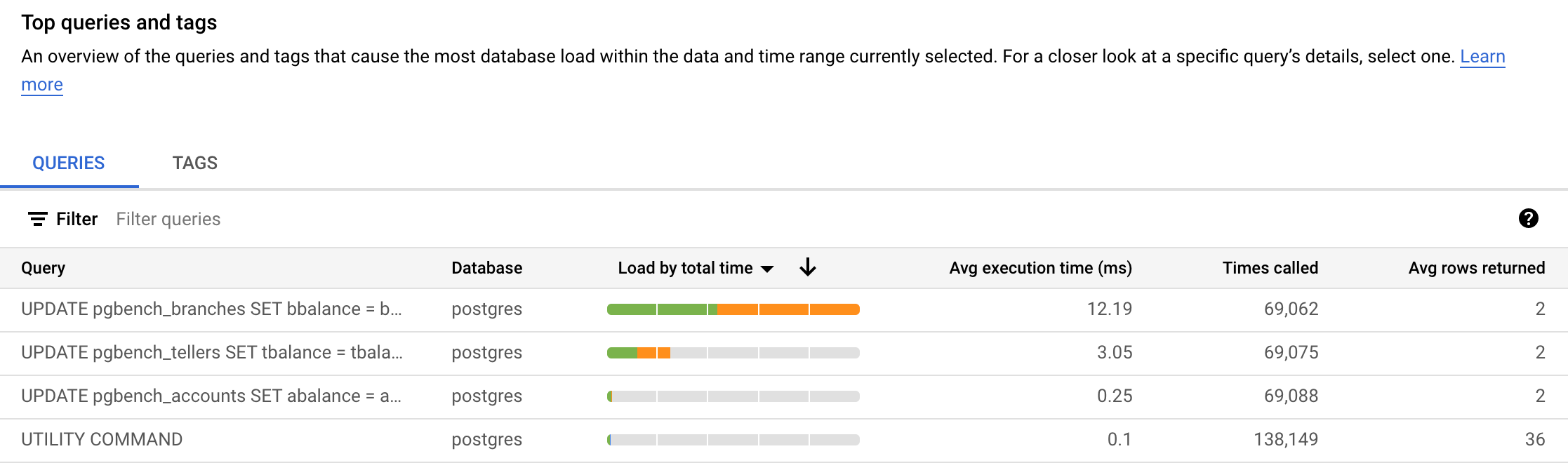
-
A coluna Carga por tempo total tem uma opção de seletor. As consultas também podem ser visualizadas por Carga por CPU, Carga por espera de E/S e Carga por espera de bloqueio.
-
Clique em qualquer um dos valores na coluna Consulta da seção Principais consultas e tags ou nos links em outras áreas do painel para analisar as consultas em detalhes.
Parabéns!
Você executou tarefas administrativas essenciais para o uso ideal de um banco de dados do AlloyDB para PostgreSQL.
Manual atualizado em 28 de agosto de 2024
Laboratório testado em 28 de agosto de 2024
Copyright 2025 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.






